Trí tuệ nhân tạo
SofGAN: Một Trình Tạo Mặt GAN Cung Cấp Kiểm Soát Lớn Hơn
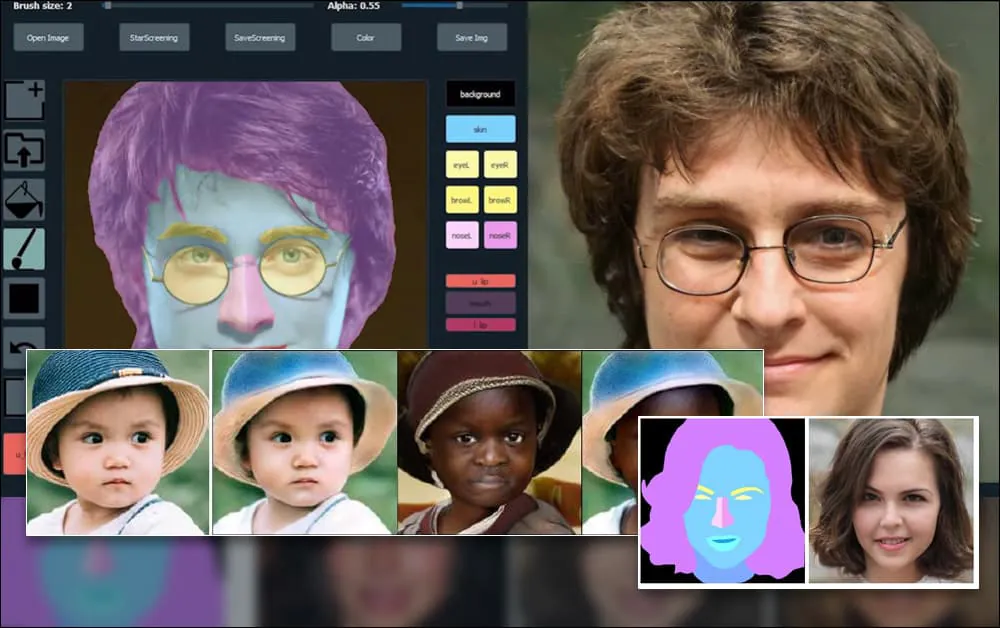
Các nhà nghiên cứu tại Thượng Hải và Mỹ đã phát triển một hệ thống tạo ảnh chân dung dựa trên GAN cho phép người dùng tạo ra những khuôn mặt mới với mức độ kiểm soát chưa từng có trước đây đối với các khía cạnh cá nhân như tóc, mắt, kính, kết cấu và màu sắc.
Để chứng minh sự linh hoạt của hệ thống, các nhà tạo ra nó đã cung cấp một giao diện giống như Photoshop, nơi người dùng có thể vẽ trực tiếp các yếu tố phân đoạn ngữ nghĩa sẽ được giải thích lại thành hình ảnh thực tế, và thậm chí có thể được thu thập bằng cách vẽ trực tiếp lên các bức ảnh hiện có.
Trong ví dụ dưới đây, một bức ảnh của diễn viên Daniel Radcliffe được sử dụng làm mẫu (và mục tiêu không phải là tạo ra một sự giống hệt, mà là một hình ảnh thực tế chung). Khi người dùng điền vào các yếu tố khác nhau, bao gồm cả các khía cạnh rời rạc như kính, chúng được xác định và giải thích trong hình ảnh đầu ra:
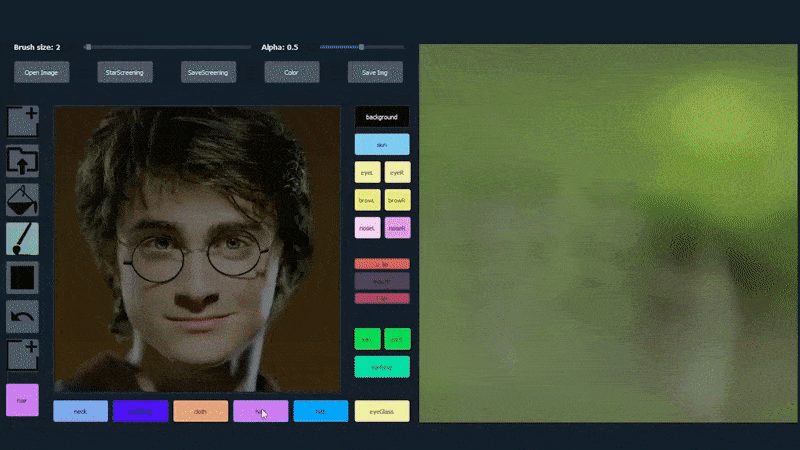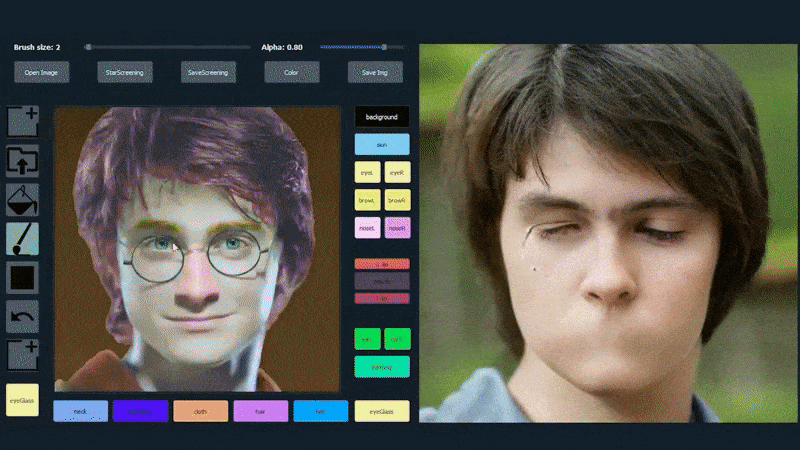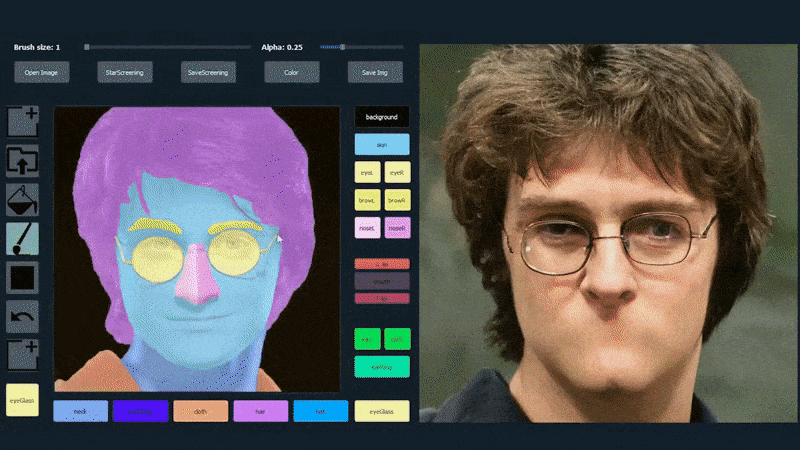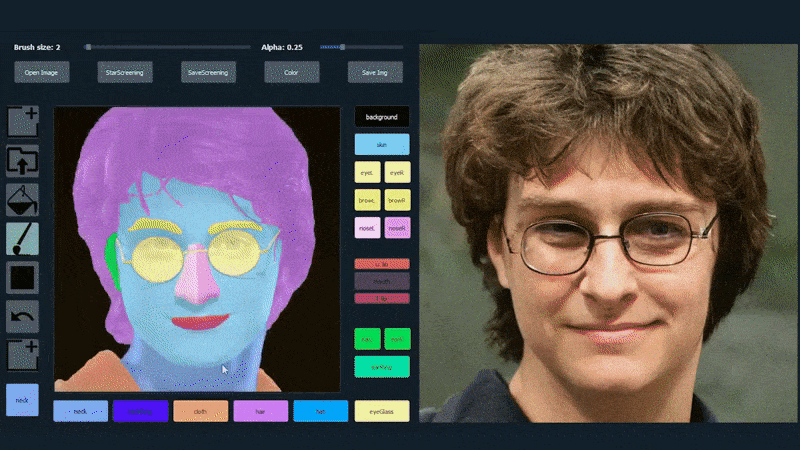
Sử dụng một hình ảnh làm vật liệu vẽ cho một bức ảnh chân dung được tạo bởi SofGAN. Source: https://www.youtube.com/watch?v=xig8ZA3DVZ8
Bài báo này có tiêu đề SofGAN: Một Trình Tạo Ảnh Chân Dung Với Phong Cách Động, và được dẫn dắt bởi Anpei Chen và Ruiyang Liu, cùng với hai nhà nghiên cứu khác từ Đại học ShanghaiTech và một từ Đại học California tại San Diego.
Phân Tách Đặc Điểm
Đóng góp chính của công việc này không phải là cung cấp một giao diện người dùng thân thiện, mà là ‘phân tách’ các đặc điểm của các đặc điểm khuôn mặt đã học, như tư thế và kết cấu, điều này cho phép SofGAN cũng tạo ra các khuôn mặt ở các góc gián tiếp với góc nhìn của máy ảnh.

Khác thường trong các trình tạo khuôn mặt dựa trên Mạng Đối Nghịch, SofGAN có thể thay đổi góc nhìn theo ý muốn, trong giới hạn của mảng góc hiện diện trong dữ liệu đào tạo. Source: https://arxiv.org/pdf/2007.03780.pdf
Vì kết cấu hiện đã được phân tách khỏi hình học, hình dạng khuôn mặt và kết cấu cũng có thể được điều khiển như các thực thể riêng biệt. Trên thực tế, điều này cho phép thay đổi chủng tộc của một khuôn mặt nguồn, một thực hành đáng tiếc mà bây giờ có một ứng dụng có thể hữu ích, cho tạo các tập dữ liệu học máy cân bằng về chủng tộc.

SofGAN cũng hỗ trợ lão hóa nhân tạo và điều chỉnh phong cách nhất quán với thuộc tính ở mức độ hạt nhân chưa từng thấy trong các hệ thống phân đoạn > hình ảnh tương tự như GauGAN của NVIDIA và hệ thống kết xuất thần kinh dựa trên trò chơi của Intel.

SofGAN có thể thực hiện lão hóa như một phong cách lặp lại.
Một đột phá khác cho phương pháp SofGAN là việc đào tạo không yêu cầu phân đoạn / hình ảnh thực sự ghép đôi, mà có thể được đào tạo trực tiếp trên hình ảnh thế giới thực không ghép đôi.
Các nhà nghiên cứu tuyên bố rằng kiến trúc ‘phân tách’ của SofGAN đã được lấy cảm hứng từ các hệ thống kết xuất hình ảnh truyền thống, những hệ thống này phân tách các khía cạnh cá nhân của một hình ảnh. Trong các quy trình hiệu ứng hình ảnh, các yếu tố cho một hợp chất được phân tách thành các thành phần nhỏ nhất, với các chuyên gia dành riêng cho từng thành phần.
Trường Nghĩa Occupation (SOF)
Để đạt được điều này trong một khuôn khổ tổng hợp hình ảnh học máy, các nhà nghiên cứu đã phát triển một trường chiếm dụng ngữ nghĩa (SOF), một phần mở rộng của trường chiếm dụng truyền thống mà phân tách các yếu tố thành phần của các bức ảnh chân dung. SOF được đào tạo trên các bản đồ phân đoạn ngữ nghĩa đa góc đã được hiệu chỉnh, nhưng không có sự giám sát thực sự.

Nhiều lần lặp lại từ một bản đồ phân đoạn đơn (phía dưới bên trái).
Ngoài ra, các bản đồ phân đoạn 2D được thu được bằng cách theo dõi tia từ đầu ra của SOF, trước khi được kết cấu bởi một máy phát sinh GAN. Các bản đồ phân đoạn ngữ nghĩa ‘nhân tạo’ cũng được mã hóa trong một không gian chiều thấp thông qua một bộ mã hóa ba lớp để đảm bảo tính liên tục của đầu ra khi góc nhìn được thay đổi.
Phương pháp đào tạo trộn không gian hai phong cách ngẫu nhiên cho mỗi vùng ngữ nghĩa:

Kiến trúc cho SofGAN.
Các nhà nghiên cứu tuyên bố rằng SofGAN đạt được khoảng cách Frechet Inception Distance (FID) thấp hơn so với các phương pháp hiện tại và tốt nhất (SOTA), cũng như một chỉ số Learned Perceptual Image Patch Similarity (LPIPS) cao hơn.
Các phương pháp StyleGAN trước đây thường bị cản trở bởi sự kết nối đặc điểm, trong đó các yếu tố tạo nên một hình ảnh bị gắn kết không thể tách rời với nhau, gây ra sự xuất hiện của các yếu tố không mong muốn cùng với một yếu tố mong muốn (ví dụ: vòng tai có thể xuất hiện khi hình dạng tai được kết xuất đã được thông tin tại thời điểm đào tạo bởi một bức ảnh có vòng tai).

Theo dõi tia được sử dụng để tính toán thể tích của các bản đồ phân đoạn ngữ nghĩa, cho phép nhiều góc nhìn.
Các Tập Dữ Liệu và Đào Tạo
Ba tập dữ liệu đã được sử dụng trong việc phát triển các phiên bản khác nhau của SofGAN: CelebAMask-HQ, một kho chứa 30.000 hình ảnh độ phân giải cao lấy từ tập dữ liệu CelebA-HQ; NVIDIA’s Flickr-Faces-HQ (FFHQ), chứa 70.000 hình ảnh, nơi các nhà nghiên cứu đã gắn nhãn cho các hình ảnh với một bộ phân tích khuôn mặt được đào tạo trước; và một nhóm 122 bản quét chân dung tự sản xuất với các vùng ngữ nghĩa được gắn nhãn thủ công.
SOF bao gồm ba mô-đun có thể đào tạo – hyper-net, một người theo dõi tia (xem hình ảnh trên), và một bộ phân loại. Bộ phát sinh StyleGAN của Dự án Semantic Instance Wised (SIW) được cấu hình tương tự như StyleGAN2 ở một số khía cạnh. Dữ liệu tăng cường được áp dụng thông qua việc缩 và cắt ngẫu nhiên, và đào tạo tính năng điều chỉnh đường dẫn mỗi bốn bước. Toàn bộ quy trình đào tạo mất 22 ngày để đạt được 800.000 lần lặp lại trên bốn GPU RTX 2080 Ti qua CUDA 10.1.
Các nhà nghiên cứu quan sát thấy rằng các kết quả tổng quát, mức độ cao bắt đầu xuất hiện khá sớm trong quá trình đào tạo, tại 1500 lần lặp lại, ba ngày vào đào tạo. Phần còn lại của quá trình đào tạo được dành cho việc thu được chi tiết tinh tế như các khía cạnh tóc và mắt.
SofGAN thường đạt được kết quả thực tế hơn từ một bản đồ phân đoạn đơn so với các phương pháp đối thủ như SPADE và Pix2PixHD của NVIDIA, và SEAN.

Dưới đây là video được phát hành bởi các nhà nghiên cứu. Các video tự lưu trữ khác có sẵn tại trang dự án.
https://www.youtube.com/watch?v=xig8ZA3DVZ8












