
Trí tuệ nhân tạo
Công cụ kiểm tra xu hướng do AI điều khiển cho các bài báo, có sẵn bằng Python

Các nhà nghiên cứu ở Canada, Ấn Độ, Trung Quốc và Úc đã hợp tác để sản xuất một gói Python miễn phí có thể được sử dụng một cách hiệu quả để phát hiện và thay thế 'ngôn ngữ không công bằng' trong bản tin.
Hệ thống mang tên thiên vị, sử dụng nhiều công nghệ máy học và cơ sở dữ liệu khác nhau để phát triển quy trình làm việc tuần hoàn gồm ba giai đoạn có thể tinh chỉnh văn bản thiên vị cho đến khi nó trả về một phiên bản không thiên vị hoặc ít nhất là trung lập hơn.

Ngôn ngữ được tải trong một đoạn tin tức được xác định là 'thiên vị' được Dbias chuyển đổi thành một phiên bản ít gây kích động hơn. Nguồn: https://arxiv.org/ftp/arxiv/papers/2207/2207.03938.pdf
Hệ thống đại diện cho một đường ống có thể tái sử dụng và khép kín có thể được cài đặt qua Pip từ Ôm mặt và được tích hợp vào các dự án hiện có dưới dạng giai đoạn bổ sung, tiện ích bổ sung hoặc plugin.
Vào tháng XNUMX, chức năng tương tự đã được triển khai trong Google Documents bị chỉ trích, đặc biệt là vì nó thiếu khả năng chỉnh sửa. Mặt khác, Dbias có thể được đào tạo có chọn lọc hơn dựa trên bất kỳ kho tin tức nào mà người dùng cuối mong muốn, đồng thời duy trì khả năng phát triển các nguyên tắc công bằng theo yêu cầu.
Điểm khác biệt quan trọng là quy trình Dbias nhằm mục đích tự động chuyển đổi 'ngôn ngữ được tải' (những từ bổ sung lớp quan trọng cho giao tiếp thực tế) thành ngôn ngữ trung lập hoặc ngôn ngữ tầm thường, thay vì liên tục dạy cho người dùng. Về cơ bản, người dùng cuối sẽ xác định các bộ lọc đạo đức và đào tạo hệ thống phù hợp; theo cách tiếp cận của Google Tài liệu, hệ thống này – được cho là – đào tạo người dùng, theo kiểu đơn phương.
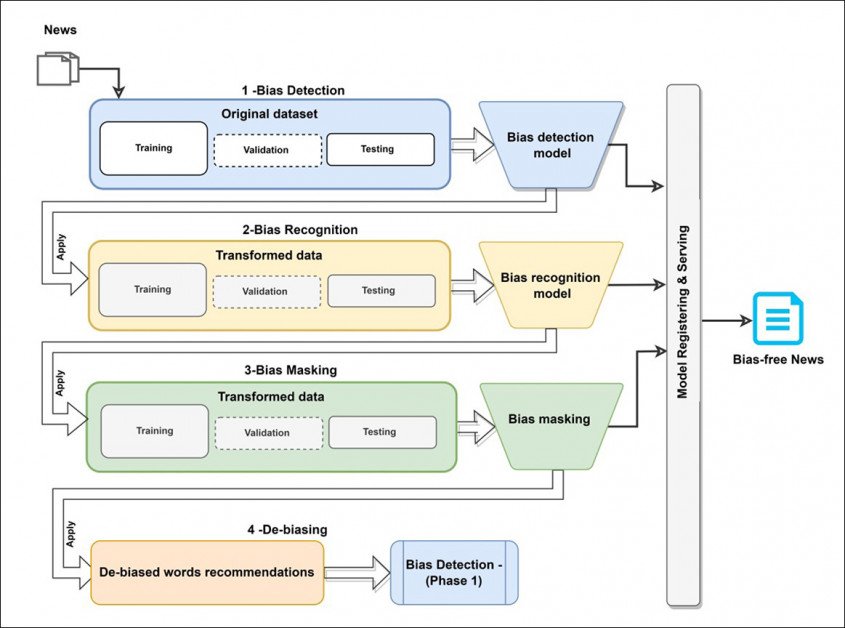
Kiến trúc khái niệm cho quy trình làm việc Dbias.
Theo các nhà nghiên cứu, Dbias là gói phát hiện sai lệch có thể cấu hình thực sự đầu tiên, trái ngược với các dự án lắp ráp sẵn có vốn đặc trưng cho tiểu ngành Xử lý ngôn ngữ tự nhiên (NLP) này cho đến nay.
Sản phẩm giấy mới có tiêu đề Một cách tiếp cận để đảm bảo tính công bằng trong các bài báovà đến từ những người đóng góp tại Đại học Toronto, Đại học Toronto Metropolitan, Quản lý Tài nguyên Môi trường tại Bangalore, Học viện Khoa học DeepBlue ở Trung Quốc và Đại học Sydney.
Phương pháp
Mô-đun đầu tiên trong Dbias là Phát hiện sai lệch, điều này thúc đẩy Chưng cấtBERT gói – phiên bản được tối ưu hóa cao của Google khá chuyên sâu về máy móc Chứng nhận. Đối với dự án, DistilBERT đã được tinh chỉnh trên Media Bias Annotation (MBIC) tập dữ liệu.

MBIC bao gồm các bài báo từ nhiều nguồn truyền thông khác nhau, bao gồm Huffington Post, USA Today và MSNBC. Các nhà nghiên cứu đã sử dụng phiên bản mở rộng của bộ dữ liệu.
Mặc dù dữ liệu gốc đã được chú thích bởi các công nhân có nguồn lực từ cộng đồng (một phương pháp mà bị cháy vào cuối năm 2021), các nhà nghiên cứu của bài báo mới đã có thể xác định thêm các trường hợp sai lệch chưa được gắn nhãn trong tập dữ liệu và thêm các trường hợp này theo cách thủ công. Các trường hợp sai lệch được xác định liên quan đến chủng tộc, giáo dục, dân tộc, ngôn ngữ, tôn giáo và giới tính.
Mô-đun tiếp theo, Nhận dạng sai lệch, sử dụng Nhận dạng đối tượng được đặt tên (NER) để phân biệt các từ sai lệch khỏi văn bản đầu vào. Bài báo viết:
'Ví dụ: tin tức “Đừng tin vào sự cường điệu giả khoa học về lốc xoáy và biến đổi khí hậu” đã được phân loại là sai lệch bởi mô-đun phát hiện sai lệch trước đó và mô-đun nhận dạng sai lệch giờ đây có thể xác định thuật ngữ “sự cường điệu giả khoa học” như một từ thiên vị.'
NER không được thiết kế riêng cho nhiệm vụ này, nhưng đã được sử dụng trước để xác định sai lệch, đáng chú ý là đối với một Dự án 2021 từ Đại học Durham ở Vương quốc Anh.
Ở giai đoạn này, các nhà nghiên cứu đã sử dụng roberta kết hợp với đường ống SpaCy English Transformer NER.

Giai đoạn tiếp theo, Mặt nạ thiên vị, liên quan đến nhiều mặt nạ mới của các từ thiên vị được xác định, hoạt động tuần tự trong các trường hợp có nhiều từ thiên vị được xác định.

Ngôn ngữ được tải được thay thế bằng ngôn ngữ thực dụng trong giai đoạn thứ ba của Dbias. Lưu ý rằng 'miệng' và 'sử dụng' tương đương với cùng một hành động, mặc dù hành động trước được coi là chế nhạo.
Khi cần thiết, phản hồi từ giai đoạn này sẽ được gửi trở lại phần đầu của quy trình để đánh giá thêm cho đến khi một số cụm từ hoặc từ thay thế phù hợp được tạo ra. Giai đoạn này sử dụng Masked Language Modeling (MLM) dọc theo các đường được thiết lập bởi một cộng tác 2021 dẫn đầu bởi Facebook Research.
Thông thường, tác vụ MLM sẽ che dấu 15% số từ một cách ngẫu nhiên, nhưng thay vào đó, quy trình làm việc của Dbias sẽ yêu cầu quy trình lấy các từ có thành kiến đã xác định làm đầu vào.
Kiến trúc đã được triển khai và đào tạo trên Google Colab Pro trên NVIDIA P100 với 24GB VRAM ở kích thước lô 16, chỉ sử dụng hai nhãn (có thành kiến và không thiên vị).
Kiểm tra
Các nhà nghiên cứu đã thử nghiệm Dbias dựa trên năm phương pháp có thể so sánh được: LG-TFIDF với Hồi quy logistic và TfidfVectorizer (TFIDF) nhúng từ; LG-ELMO; MLP-ELMO (mạng nơ-ron nhân tạo chuyển tiếp nguồn cấp dữ liệu có chứa các nhúng ELMO); BERT; và RoBERTa.
Các số liệu được sử dụng cho các bài kiểm tra là độ chính xác (ACC), độ chính xác (PREC), khả năng thu hồi (Rec) và điểm F1. Vì các nhà nghiên cứu không biết về bất kỳ hệ thống hiện có nào có thể hoàn thành cả ba nhiệm vụ trong một quy trình duy nhất, nên việc phân phối đã được thực hiện cho các khung cạnh tranh, bằng cách chỉ đánh giá các nhiệm vụ chính của Dbias – phát hiện và nhận dạng sai lệch.

Kết quả từ các thử nghiệm Dbias.
Dbias đã thành công trong việc vượt qua các kết quả từ tất cả các khung cạnh tranh, bao gồm cả những khung có yêu cầu xử lý nặng hơn
Bài báo viết:
'Kết quả cũng cho thấy rằng nói chung, các phương pháp nhúng thần kinh sâu có thể vượt trội hơn các phương pháp nhúng truyền thống (ví dụ: TFIDF) trong nhiệm vụ phân loại sai lệch. Điều này được thể hiện qua hiệu suất tốt hơn của nhúng mạng thần kinh sâu (tức là ELMO) so với vector hóa TFIDF khi được sử dụng với LG.
'Điều này có lẽ là do các nhúng thần kinh sâu có thể nắm bắt tốt hơn ngữ cảnh của các từ trong văn bản ở các ngữ cảnh khác nhau. Các phương pháp nhúng thần kinh sâu và phương pháp thần kinh sâu (MLP, BERT, RoBERTa) cũng hoạt động tốt hơn phương pháp ML truyền thống (LG).'
Các nhà nghiên cứu cũng lưu ý rằng các phương pháp dựa trên Transformer vượt trội so với các phương pháp cạnh tranh trong việc phát hiện sai lệch.
Một thử nghiệm bổ sung liên quan đến việc so sánh giữa Dbias và các phiên bản khác nhau của SpaCy Core Web, bao gồm core-sm (nhỏ), core-md (trung bình) và core-lg (lớn). Dbias cũng có thể lãnh đạo hội đồng quản trị trong những thử nghiệm này:

Các nhà nghiên cứu kết luận bằng cách quan sát rằng các nhiệm vụ nhận dạng sai lệch thường cho thấy độ chính xác cao hơn trong các mô hình lớn hơn và đắt tiền hơn, do – họ suy đoán – số lượng tham số và điểm dữ liệu tăng lên. Họ cũng nhận thấy rằng hiệu quả của công việc trong tương lai trong lĩnh vực này sẽ phụ thuộc vào những nỗ lực lớn hơn để chú thích các bộ dữ liệu chất lượng cao.
Rừng và Cây cối
Hy vọng rằng loại dự án công nhận sự thiên vị chi tiết này cuối cùng sẽ được tích hợp vào các khuôn khổ tìm kiếm sự thiên vị có thể có cái nhìn ít thiển cận hơn và cân nhắc rằng việc chọn đưa tin về bất kỳ câu chuyện cụ thể nào tự nó là một hành động thiên vị có khả năng được thúc đẩy bởi nhiều thứ hơn là chỉ thống kê lượt xem được báo cáo.
Xuất bản lần đầu vào ngày 14 tháng 2022 năm XNUMX.















