
Trí tuệ nhân tạo
Google hình dung một Hệ thống truy vấn giống GPT-3, không có kết quả tìm kiếm

Một bài báo mới từ bốn nhà nghiên cứu của Google đề xuất một hệ thống 'chuyên gia' có khả năng trả lời chính thức các câu hỏi của người dùng mà không cần trình bày danh sách các kết quả tìm kiếm có thể có, tương tự như mô hình Hỏi & Đáp đã thu hút sự chú ý của công chúng thông qua sự ra đời của GPT-3 trong quá khứ năm.
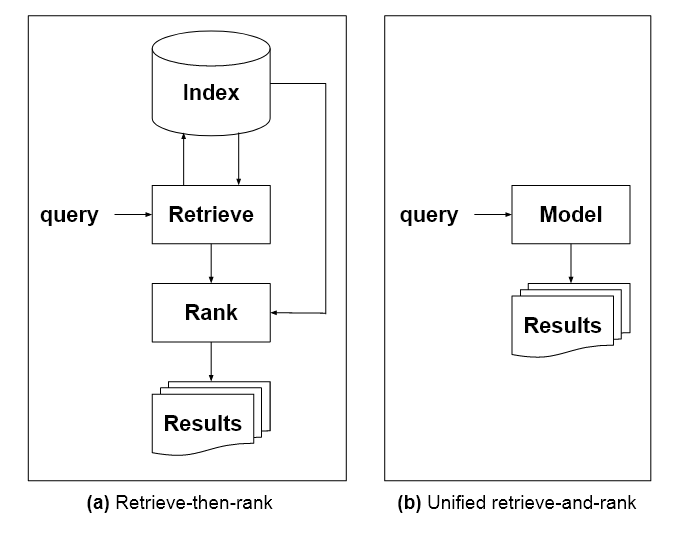
Sản phẩm giấy, được phép Suy nghĩ lại Tìm kiếm: Đưa các Chuyên gia ra khỏi Dilettantes, gợi ý rằng tiêu chuẩn hiện tại về việc hiển thị cho người dùng danh sách kết quả tìm kiếm để phản hồi một câu hỏi là 'gánh nặng nhận thức' và đề xuất những cải tiến về khả năng của hệ thống xử lý ngôn ngữ tự nhiên (NLP) trong việc cung cấp phản hồi chính xác và dứt khoát .
Theo mô hình được đề xuất của một 'chuyên gia', nhà tiên tri tên miền chéo, hàng nghìn nguồn kết quả tìm kiếm có thể có sẽ được đưa vào một mô hình ngôn ngữ thay vì có sẵn rõ ràng dưới dạng tài nguyên khám phá để người dùng tự đánh giá và điều hướng. Nguồn: https://arxiv.org/pdf/2105.02274.pdf
Bài báo do Donald Metzler tại Google Research đứng đầu, đề xuất các cải tiến về loại phản hồi tiên tri đa miền hiện có thể nhận được từ các mô hình ngôn ngữ tự hồi quy học sâu như GPT-3. Những cải tiến chính dự kiến là a) mô hình sẽ có khả năng trích dẫn chính xác các nguồn thông báo phản hồi và b) mô hình sẽ được ngăn chặn khỏi 'ảo giác' phản hồi hoặc phát minh ra tài liệu nguồn không tồn tại, hiện đang là một vấn đề với các kiến trúc như vậy.
Khả năng và đào tạo đa miền
Ngoài ra, mô hình ngôn ngữ được đề xuất, được mô tả trong bài báo là 'Một mô hình duy nhất cho tất cả các nhiệm vụ truy xuất thông tin', sẽ được đào tạo trên nhiều lĩnh vực, bao gồm cả hình ảnh và văn bản. Nó cũng cần sự hiểu biết về nguồn gốc của kiến thức, điều còn thiếu trong kiến trúc kiểu GPT-3.
'Để thay thế các chỉ mục bằng một mô hình thống nhất, duy nhất, chính mô hình đó phải có kiến thức về vũ trụ của các số nhận dạng tài liệu, giống như cách mà các chỉ mục truyền thống làm. Một cách để thực hiện điều này là tránh xa các LM truyền thống và hướng tới các mô hình kho văn bản cùng mô hình hóa các mối quan hệ thuật ngữ-thuật ngữ, thuật ngữ-tài liệu và tài liệu-tài liệu.'

Trong hình trên, từ bài báo, ba cách tiếp cận để đáp ứng yêu cầu của người dùng: bên trái, các mô hình ngôn ngữ ẩn trong kết quả tìm kiếm theo thuật toán của Google đã chọn và ưu tiên 'câu trả lời hay nhất', nhưng lại để nó là kết quả hàng đầu trong số nhiều kết quả. Center, một phản hồi đàm thoại kiểu GPT-3, nói với thẩm quyền nhưng không biện minh cho tuyên bố của mình hoặc trích dẫn nguồn. Đúng vậy, hệ thống chuyên gia được đề xuất kết hợp trực tiếp 'phản hồi tốt nhất' từ các kết quả tìm kiếm được xếp hạng vào một câu trả lời mô phạm, với các trích dẫn chú thích cuối trang theo phong cách học thuật (không được mô tả trong hình ảnh gốc) cho biết các nguồn cung cấp phản hồi.
Loại bỏ kết quả độc hại và không chính xác
Các nhà nghiên cứu lưu ý rằng tính chất năng động và được cập nhật liên tục của các chỉ mục tìm kiếm là một thách thức để tái tạo hoàn toàn trong mô hình học máy có tính chất này. Ví dụ: khi một nguồn đáng tin cậy một thời đã được đào tạo trực tiếp về sự hiểu biết của mô hình về thế giới, việc loại bỏ ảnh hưởng của nó (ví dụ: sau khi nó bị mất uy tín) có thể khó khăn hơn việc chỉ xóa URL khỏi SERP, vì các khái niệm dữ liệu có thể trở nên khó khăn hơn. trừu tượng và được thể hiện rộng rãi trong quá trình tiếp thu trong đào tạo.
Ngoài ra, một mô hình như vậy sẽ cần phải được đào tạo liên tục để cung cấp cùng một mức độ phản hồi đối với các bài báo và ấn phẩm mới như hiện tại được cung cấp bởi các nguồn liên tục của Google. Trên thực tế, điều này có nghĩa là triển khai liên tục và tự động, trái ngược với chế độ hiện tại, trong đó các sửa đổi nhỏ được thực hiện đối với trọng số và cài đặt của thuật toán tìm kiếm dạng tự do, nhưng bản thân thuật toán thường chỉ được cập nhật không thường xuyên.
Các bề mặt tấn công cho một Oracle chuyên gia tập trung
Một mô hình tập trung liên tục đồng hóa và khái quát hóa dữ liệu mới có thể biến đổi bề mặt tấn công cho các yêu cầu tìm kiếm.
Hiện tại, kẻ tấn công có thể thu được lợi ích bằng cách đạt được thứ hạng cao cho các miền hoặc trang chứa thông tin sai lệch hoặc mã độc. Dưới sự bảo trợ của một nhà tiên tri 'chuyên gia' mờ đục hơn, cơ hội chuyển hướng người dùng sang các miền tấn công bị giảm đi đáng kể, nhưng khả năng tiêm các cuộc tấn công dữ liệu độc hại lại tăng lên rất nhiều.
Điều này là do hệ thống được đề xuất không loại bỏ thuật toán xếp hạng tìm kiếm mà ẩn nó khỏi người dùng, tự động hóa hiệu quả mức độ ưu tiên của/các kết quả hàng đầu và biến nó (hoặc chúng) thành một tuyên bố mô phạm. Những người dùng độc hại từ lâu đã có thể dàn dựng các cuộc tấn công chống lại thuật toán tìm kiếm của Google, để bán sản phẩm giả, người dùng trực tiếp đến các miền phát tán phần mềm độc hại, hoặc cho các mục đích của thao túng chính trị, trong số nhiều trường hợp sử dụng khác.
Không AGI
Các nhà nghiên cứu nhấn mạnh rằng một hệ thống như vậy sẽ khó có thể đủ tiêu chuẩn là Trí tuệ nhân tạo chung (AGI) và đặt triển vọng về một chuyên gia phản hồi toàn cầu trong bối cảnh xử lý ngôn ngữ tự nhiên, chịu mọi thách thức mà các mô hình như vậy hiện đang phải đối mặt.
Bài viết phác thảo năm yêu cầu đối với phản hồi 'chất lượng cao':
1: Quyền hạn
Như với các thuật toán xếp hạng hiện tại, 'thẩm quyền' dường như bắt nguồn từ trích dẫn từ các miền chất lượng cao được coi là có thẩm quyền. Các nhà nghiên cứu quan sát:
'Các phản hồi sẽ tạo nội dung bằng cách lấy từ các nguồn có thẩm quyền cao. Đây là một lý do khác tại sao việc thiết lập các kết nối rõ ràng hơn giữa các chuỗi thuật ngữ và siêu dữ liệu tài liệu lại rất quan trọng. Nếu tất cả các tài liệu trong kho văn bản được chú thích bằng điểm số có thẩm quyền, thì điểm số đó sẽ được tính đến khi đào tạo mô hình, tạo phản hồi hoặc cả hai.'
Mặc dù các nhà nghiên cứu không gợi ý rằng kết quả SERPs truyền thống sẽ không khả dụng nếu một nhà tiên tri chuyên gia thuộc loại này được phát hiện là hoạt động hiệu quả và phổ biến, nhưng toàn bộ bài báo trình bày hệ thống xếp hạng truyền thống và danh sách kết quả tìm kiếm, dưới ánh sáng của 'thập kỷ cũ' và hệ thống truy xuất thông tin lỗi thời.
'Thực tế là xếp hạng là một thành phần quan trọng của mô hình này là một triệu chứng của hệ thống truy xuất cung cấp cho người dùng lựa chọn các câu trả lời tiềm năng, điều này gây ra gánh nặng nhận thức khá lớn cho người dùng. Mong muốn trả về câu trả lời thay vì danh sách kết quả được xếp hạng là một trong những yếu tố thúc đẩy phát triển hệ thống trả lời câu hỏi. '
2: Minh bạch
Các nhà nghiên cứu nhận xét:
'Bất cứ khi nào có thể, nguồn gốc của thông tin được trình bày cho người dùng nên được cung cấp cho họ. Đây có phải là nguồn thông tin chính? Nếu không, nguồn chính là gì?'
3: Xử lý Xu hướng
Bài báo lưu ý rằng các mô hình ngôn ngữ được đào tạo trước được thiết kế không phải để đánh giá sự thật theo kinh nghiệm mà để khái quát hóa và ưu tiên các xu hướng chi phối trong dữ liệu. Nó thừa nhận rằng chỉ thị này mở ra mô hình để tấn công (như đã xảy ra với Microsoft's chatbot vô tình phân biệt chủng tộc vào năm 2016), và các hệ thống phụ trợ đó sẽ cần thiết để bảo vệ chống lại các phản ứng hệ thống thiên vị như vậy.
4: Kích hoạt các quan điểm đa dạng
Bài viết cũng đề xuất cơ chế đảm bảo đa nguyên quan điểm:
'Các phản hồi được tạo nên đại diện cho một loạt các quan điểm đa dạng nhưng không nên phân cực. Ví dụ: đối với các truy vấn về các chủ đề gây tranh cãi, cả hai mặt của chủ đề phải được đề cập một cách công bằng và cân bằng. Điều này rõ ràng có mối liên hệ chặt chẽ với xu hướng mô hình.'
5: Ngôn ngữ có thể truy cập
Bên cạnh việc cung cấp các bản dịch chính xác trong trường hợp phản hồi được coi là có thẩm quyền ở một ngôn ngữ khác, bài báo gợi ý rằng các phản hồi được gói gọn nên được 'viết bằng thuật ngữ đơn giản nhất có thể'.















