Trí tuệ nhân tạo
Enfabrica Ra Mắt Bộ Nhớ Fabric Dựa Trên Ethernet Có Thể Định Nghĩa Lại Sự Kết Luận Của Trí Tuệ Nhân Tạo Tại Quy Mô Lớn
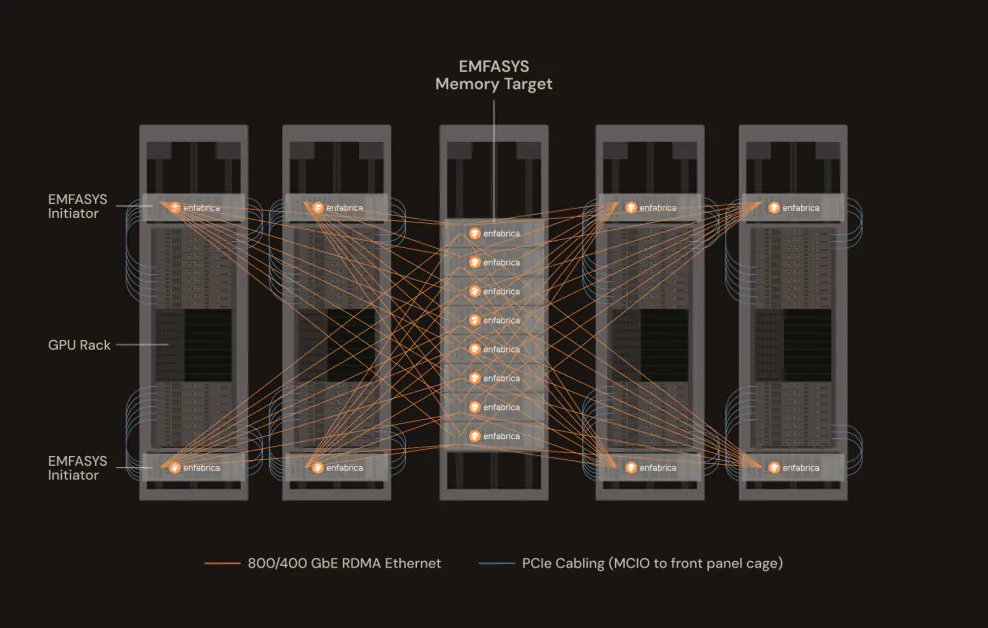
Enfabrica, một công ty khởi nghiệp tại Thung lũng Silicon được hỗ trợ bởi Nvidia, đã ra mắt một sản phẩm đột phá có thể thay đổi đáng kể cách thức triển khai và mở rộng các công việc trí tuệ nhân tạo quy mô lớn. Hệ thống vải nhớ đàn hồi (EMFASYS) của công ty là bộ nhớ vải dựa trên Ethernet đầu tiên được thiết kế đặc biệt để giải quyết nút thắt cốt lõi của việc suy luận trí tuệ nhân tạo: truy cập bộ nhớ.
Tại thời điểm các mô hình trí tuệ nhân tạo trở nên phức tạp, nhận thức ngữ cảnh và bền bỉ hơn – đòi hỏi lượng bộ nhớ lớn cho mỗi phiên làm việc của người dùng – EMFASYS cung cấp một cách tiếp cận mới để tách bộ nhớ khỏi tính toán, cho phép các trung tâm dữ liệu trí tuệ nhân tạo cải thiện hiệu suất, giảm chi phí và tăng cường sử dụng tài nguyên đắt tiền nhất của họ: GPU.
Bộ Nhớ Fabric Là Gì — Và Tại Sao Nó Quan Trọng?
Truyền thống, bộ nhớ trong các trung tâm dữ liệu đã được gắn chặt với máy chủ hoặc nút mà nó cư trú. Mỗi GPU hoặc CPU chỉ có thể truy cập vào bộ nhớ có băng thông cao trực tiếp gắn với nó – thường là HBM cho GPU hoặc DRAM cho CPU. Kiến trúc này hoạt động tốt khi các công việc nhỏ và có thể dự đoán. Nhưng trí tuệ nhân tạo đã thay đổi trò chơi. Các mô hình ngôn ngữ lớn đòi hỏi truy cập vào các cửa sổ ngữ cảnh lớn, lịch sử người dùng và bộ nhớ đa tác nhân – tất cả đều phải được xử lý nhanh chóng và không có độ trễ. Những yêu cầu bộ nhớ này thường vượt quá khả năng của bộ nhớ cục bộ, tạo ra các nút thắt khiến lõi GPU bị kẹt và làm tăng chi phí cơ sở hạ tầng.
Một bộ nhớ vải giải quyết vấn đề này bằng cách biến bộ nhớ thành một tài nguyên được chia sẻ, phân tán – một loại bộ nhớ đám mây trong trung tâm dữ liệu. Hãy nghĩ về nó như tạo ra một “đám mây bộ nhớ” trong giá đỡ trung tâm dữ liệu. Thay vì sao chép bộ nhớ trên các máy chủ hoặc quá tải bộ nhớ HBM đắt tiền, một bộ nhớ vải cho phép bộ nhớ được tổng hợp, tách rời và truy cập theo nhu cầu trên mạng tốc độ cao. Điều này cho phép các công việc suy luận trí tuệ nhân tạo mở rộng quy mô hiệu quả hơn mà không bị giới hạn bởi giới hạn bộ nhớ vật lý của bất kỳ nút nào.
Phương Pháp Của Enfabrica: Ethernet và CXL, Cùng Nhau Một Lần
EMFASYS đạt được kiến trúc bộ nhớ quy mô giá đỡ này bằng cách kết hợp hai công nghệ mạnh mẽ: RDMA trên Ethernet và Liên Kết Tính Toán CXL. Đầu tiên cho phép chuyển giao dữ liệu siêu thấp độ trễ, băng thông cao trên mạng Ethernet tiêu chuẩn. Thứ hai cho phép bộ nhớ được tách rời khỏi CPU và GPU và tập hợp thành tài nguyên được chia sẻ, có thể truy cập qua liên kết CXL tốc độ cao.
Ở trung tâm của EMFASYS là chip ACF-S của Enfabrica, một “SuperNIC” 3,2 terabit/giây (Tbps) kết hợp mạng và kiểm soát bộ nhớ vào một thiết bị duy nhất. Chip này cho phép máy chủ giao tiếp với các khối bộ nhớ DDR5 hàng terabyte – lên đến 18 terabyte mỗi nút – phân tán trên toàn giá đỡ. Điều quan trọng là nó thực hiện việc này bằng cách sử dụng các cổng Ethernet tiêu chuẩn, cho phép các nhà điều hành tận dụng cơ sở hạ tầng trung tâm dữ liệu hiện có mà không cần đầu tư vào các kết nối độc quyền.
Điều khiến EMFASYS đặc biệt hấp dẫn là khả năng của nó trong việc chuyển giao động các công việc bị ràng buộc bởi bộ nhớ từ HBM đắt tiền gắn với GPU sang DRAM giá cả phải chăng hơn, tất cả đều duy trì độ trễ truy cập ở mức micro giây. Phần mềm đằng sau EMFASYS bao gồm các cơ chế lưu trữ thông minh và cân bằng tải giúp ẩn độ trễ và điều phối chuyển động bộ nhớ theo cách minh bạch đối với các mô hình ngôn ngữ lớn đang chạy trên hệ thống.
Ảnh Hưởng Đối Với Ngành Công Nghiệp Trí Tuệ Nhân Tạo
Đây không chỉ là một giải pháp phần cứng thông minh – nó đại diện cho một sự thay đổi triết lý trong cách xây dựng và mở rộng cơ sở hạ tầng trí tuệ nhân tạo. Khi trí tuệ nhân tạo tạo ra từ một điều mới mẻ đến một điều cần thiết, với hàng tỷ truy vấn của người dùng được xử lý hàng ngày, chi phí phục vụ các mô hình này đã trở nên không bền vững đối với nhiều công ty. GPU thường bị underutilized không phải vì thiếu tính toán, mà vì chúng đang chờ bộ nhớ. EMFASYS giải quyết sự mất cân bằng trực tiếp này.
Bằng cách cho phép bộ nhớ được chia sẻ, gắn với vải và có thể truy cập qua Ethernet, Enfabrica cung cấp cho các nhà điều hành trung tâm dữ liệu một giải pháp mở rộng quy mô thay thế để liên tục mua thêm GPU hoặc HBM. Thay vào đó, họ có thể tăng dung lượng bộ nhớ một cách mô đun, sử dụng DRAM ngoài hộp và mạng thông minh, giảm tổng diện tích và cải thiện kinh tế của suy luận trí tuệ nhân tạo.
Ảnh hưởng vượt ra ngoài tiết kiệm chi phí ngay lập tức. Kiến trúc này mở đường cho các mô hình dịch vụ bộ nhớ, nơi ngữ cảnh, lịch sử và trạng thái tác nhân có thể tồn tại vượt quá một phiên hoặc máy chủ, mở ra cánh cửa cho các hệ thống trí tuệ nhân tạo thông minh và cá nhân hóa hơn. Nó cũng đặt nền tảng cho các đám mây trí tuệ nhân tạo mạnh mẽ hơn, nơi các công việc có thể được phân phối đàn hồi trên toàn giá đỡ hoặc toàn bộ trung tâm dữ liệu mà không bị giới hạn bởi bộ nhớ cứng.
Nhìn Về Tương Lai
Enfabrica’s EMFASYS hiện đang được lấy mẫu với các khách hàng được chọn, và trong khi công ty chưa tiết lộ những đối tác đó là ai, Reuters báo cáo rằng các nhà cung cấp đám mây trí tuệ nhân tạo lớn đã thử nghiệm hệ thống này. Điều này đặt Enfabrica không chỉ là một nhà cung cấp linh kiện, mà còn là một nhà kích hoạt chính trong thế hệ tiếp theo của cơ sở hạ tầng trí tuệ nhân tạo.
Bằng cách tách bộ nhớ khỏi tính toán và làm cho nó có sẵn trên mạng Ethernet tốc độ cao, hàng hóa, Enfabrica đang đặt nền tảng cho một kỷ nguyên mới của kiến trúc trí tuệ nhân tạo – một nơi suy luận có thể mở rộng quy mô mà không có sự thỏa hiệp, nơi tài nguyên không còn bị mắc kẹt và nơi kinh tế của việc triển khai các mô hình ngôn ngữ lớn cuối cùng bắt đầu có ý nghĩa.
Trong một thế giới ngày càng được định nghĩa bởi các hệ thống trí tuệ nhân tạo giàu ngữ cảnh, đa tác nhân, bộ nhớ không còn là một diễn viên phụ – nó là sân khấu. Và Enfabrica đang đặt cược rằng ai xây dựng sân khấu tốt nhất sẽ định nghĩa hiệu suất của trí tuệ nhân tạo trong nhiều năm tới.












