
Trí tuệ nhân tạo
Hiệu quảViT: Bộ biến đổi thị giác hiệu quả về bộ nhớ cho thị giác máy tính có độ phân giải cao

Nhờ công suất mô hình cao, các mẫu Vision Transformer đã gặt hái được nhiều thành công trong thời gian gần đây. Bất chấp hiệu suất của chúng, các mô hình máy biến áp tầm nhìn có một nhược điểm lớn: khả năng tính toán vượt trội của chúng đi kèm với chi phí tính toán cao và đó là lý do tại sao máy biến áp tầm nhìn không phải là lựa chọn đầu tiên cho các ứng dụng thời gian thực. Để giải quyết vấn đề này, một nhóm các nhà phát triển đã cho ra mắt EfficiencyViT, dòng máy biến áp thị giác tốc độ cao.
Khi làm việc trên EfficiencyViT, các nhà phát triển nhận thấy rằng tốc độ của các mô hình máy biến áp hiện tại thường bị giới hạn bởi các hoạt động bộ nhớ không hiệu quả, đặc biệt là các chức năng theo phần tử & định hình lại tensor trong mạng MHSA hoặc Multi-Head Self Notice. Để giải quyết các hoạt động bộ nhớ kém hiệu quả này, các nhà phát triển của EtiviT đã làm việc trên một khối xây dựng mới bằng cách sử dụng bố cục bánh sandwich, tức là mô hình EtiviT sử dụng một mạng Chú ý nhiều đầu được gắn với bộ nhớ duy nhất giữa các lớp FFN hiệu quả giúp cải thiện hiệu quả bộ nhớ và cũng tăng cường giao tiếp kênh tổng thể. Hơn nữa, mô hình cũng phát hiện ra rằng các bản đồ chú ý thường có độ tương đồng cao giữa các đầu, dẫn đến dư thừa tính toán. Để giải quyết vấn đề dư thừa, mô hình EfficiencyViT trình bày một mô-đun chú ý nhóm xếp tầng nhằm cung cấp cho các đầu chú ý bằng các phần phân chia khác nhau của tính năng đầy đủ. Phương pháp này không chỉ giúp tiết kiệm chi phí tính toán mà còn cải thiện tính đa dạng chú ý của mô hình.
Các thử nghiệm toàn diện được thực hiện trên mô hình Hiệu quảViT trong các tình huống khác nhau cho thấy rằng Hiệu quảViT vượt trội hơn các mô hình hiệu quả hiện có về thị giác máy tính đồng thời đạt được sự cân bằng tốt giữa độ chính xác và tốc độ. Vì vậy, chúng ta hãy tìm hiểu sâu hơn và khám phá mô hình Hiệu quảViT sâu hơn một chút.
Giới thiệu về Vision Transformers và EfficiencyViT
Vision Transformers vẫn là một trong những framework phổ biến nhất trong ngành thị giác máy tính vì chúng mang lại hiệu suất vượt trội và khả năng tính toán cao. Tuy nhiên, với việc không ngừng cải thiện độ chính xác và hiệu suất của các mô hình máy biến áp thị giác, chi phí vận hành và chi phí tính toán cũng tăng theo. Ví dụ: các mô hình hiện tại được biết là cung cấp hiệu suất hiện đại trên bộ dữ liệu ImageNet như SwinV2 và V-MoE lần lượt sử dụng các tham số 3B và 14.7B. Kích thước khổng lồ của các mô hình này cùng với chi phí và yêu cầu tính toán khiến chúng thực tế không phù hợp với các thiết bị và ứng dụng thời gian thực.
Mô hình EfficiencyNet nhằm mục đích khám phá cách nâng cao hiệu suất của mô hình máy biến áp tầm nhìnvà tìm ra các nguyên tắc liên quan đến việc thiết kế các kiến trúc khung dựa trên máy biến áp hiệu quả và hiệu quả. Mô hình Hiệu quảViT dựa trên các khung biến đổi tầm nhìn hiện có như Swim và DeiT, đồng thời phân tích ba yếu tố thiết yếu ảnh hưởng đến tốc độ can thiệp của mô hình bao gồm dự phòng tính toán, truy cập bộ nhớ và sử dụng tham số. Hơn nữa, mô hình này còn nhận thấy rằng tốc độ của các mô hình máy biến áp thị giác trong giới hạn bộ nhớ, có nghĩa là việc sử dụng toàn bộ sức mạnh tính toán trong CPU/GPU bị cấm hoặc hạn chế do độ trễ truy cập bộ nhớ, dẫn đến tác động tiêu cực đến tốc độ thời gian chạy của máy biến áp . Các chức năng theo phần tử và định hình lại tensor trong mạng MHSA hoặc mạng Tự chú ý nhiều đầu là những hoạt động tiêu tốn bộ nhớ nhất. Mô hình này còn nhận thấy rằng việc điều chỉnh tối ưu tỷ lệ giữa FFN (mạng chuyển tiếp nguồn cấp dữ liệu) và MHSA có thể giúp giảm đáng kể thời gian truy cập bộ nhớ mà không ảnh hưởng đến hiệu suất. Tuy nhiên, mô hình cũng quan sát thấy một số điểm dư thừa trong bản đồ chú ý do xu hướng của người chú ý muốn tìm hiểu các phép chiếu tuyến tính tương tự.
Mô hình này là sự trau dồi cuối cùng của những phát hiện trong quá trình nghiên cứu cho EfficiencyViT. Mô hình này có màu đen mới với bố cục bánh sandwich áp dụng một lớp MHSA gắn với bộ nhớ duy nhất giữa Mạng chuyển tiếp nguồn cấp dữ liệu hoặc các lớp FFN. Cách tiếp cận này không chỉ giảm thời gian cần thiết để thực hiện các hoạt động liên quan đến bộ nhớ trong MHSA mà còn làm cho toàn bộ quá trình trở nên hiệu quả hơn về bộ nhớ bằng cách cho phép nhiều lớp FFN hơn để tạo điều kiện thuận lợi cho việc liên lạc giữa các kênh khác nhau. Mô hình này cũng sử dụng mô-đun Chú ý nhóm theo tầng hoặc CGA mới nhằm mục đích làm cho việc tính toán hiệu quả hơn bằng cách giảm sự dư thừa tính toán không chỉ trong các đầu chú ý mà còn tăng độ sâu của mạng dẫn đến công suất mô hình được nâng cao. Cuối cùng, mô hình mở rộng độ rộng kênh của các thành phần mạng thiết yếu bao gồm các phép chiếu giá trị, đồng thời thu hẹp các thành phần mạng có giá trị thấp như thứ nguyên ẩn trong mạng chuyển tiếp nguồn cấp dữ liệu để phân phối lại các tham số trong khung.

Như có thể thấy trong hình ảnh trên, khung công tác EfficiencyViT hoạt động tốt hơn các mô hình CNN và ViT hiện đại cả về độ chính xác và tốc độ. Nhưng làm thế nào mà khung công tác Hiệu quảViT có thể hoạt động tốt hơn một số khung công nghệ hiện đại nhất? Hãy cùng tìm hiểu điều đó.
Hiệu quảViT: Cải thiện hiệu quả của máy biến áp tầm nhìn
Mô hình Hiệu quảViT nhằm mục đích nâng cao hiệu quả của các mô hình biến đổi tầm nhìn hiện có bằng cách sử dụng ba quan điểm,
- Tính toán dư thừa.
- Truy cập bộ nhớ.
- Cách sử dụng tham số.
Mô hình nhằm mục đích tìm hiểu xem các thông số trên ảnh hưởng như thế nào đến hiệu suất của các mô hình máy biến áp tầm nhìn và cách giải quyết chúng để đạt được kết quả tốt hơn với hiệu quả tốt hơn. Hãy nói về chúng sâu hơn một chút.
Truy cập và hiệu quả bộ nhớ
Một trong những yếu tố thiết yếu ảnh hưởng đến tốc độ của mô hình là chi phí truy cập bộ nhớ hoặc MAO. Như có thể thấy trong hình bên dưới, một số toán tử trong máy biến áp bao gồm phép cộng, chuẩn hóa và định hình lại phần tử thường xuyên là những thao tác không hiệu quả về bộ nhớ vì chúng yêu cầu quyền truy cập vào các đơn vị bộ nhớ khác nhau, đây là một quá trình tốn thời gian.
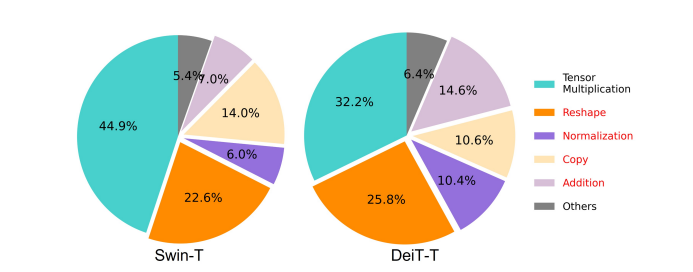
Mặc dù có một số phương pháp hiện có có thể đơn giản hóa các phép tính tự chú ý của softmax tiêu chuẩn như xấp xỉ thứ hạng thấp và chú ý thưa thớt, nhưng chúng thường cung cấp khả năng tăng tốc hạn chế và làm giảm độ chính xác.
Mặt khác, khung công tác EtiviT nhằm mục đích cắt giảm chi phí truy cập bộ nhớ bằng cách giảm số lượng lớp không hiệu quả về bộ nhớ trong khung. Mô hình này chia tỷ lệ DeiT-T và Swin-T thành các mạng con nhỏ với thông lượng nhiễu cao hơn là 1.25X và 1.5X, đồng thời so sánh hiệu suất của các mạng con này với tỷ lệ của các lớp MHSA. Như có thể thấy trong hình bên dưới, khi được triển khai, phương pháp này sẽ tăng độ chính xác của các lớp MHSA lên khoảng 20 đến 40%.

Tính hiệu quả
Các lớp MHSA có xu hướng nhúng chuỗi đầu vào vào nhiều không gian con hoặc phần đầu và tính toán các bản đồ chú ý riêng lẻ, một phương pháp được biết là giúp tăng hiệu suất. Tuy nhiên, bản đồ chú ý không hề rẻ về mặt tính toán và để khám phá chi phí tính toán, mô hình Hiệu quảViT khám phá cách giảm sự chú ý dư thừa trong các mô hình ViT nhỏ hơn. Mô hình này đo lường độ tương tự cosine tối đa của từng đầu và các đầu còn lại trong mỗi khối bằng cách huấn luyện các mô hình DeiT-T và Swim-T được thu nhỏ theo chiều rộng với tốc độ suy luận tăng lên 1.25×. Như có thể thấy trong hình bên dưới, có rất nhiều điểm tương đồng giữa các đầu chú ý, điều này cho thấy rằng mô hình phát sinh dư thừa tính toán vì nhiều đầu có xu hướng tìm hiểu các phép chiếu tương tự của tính năng đầy đủ chính xác.

Để khuyến khích các đầu tìm hiểu các mẫu khác nhau, mô hình này áp dụng rõ ràng một giải pháp trực quan trong đó mỗi đầu chỉ được cung cấp một phần của tính năng đầy đủ, một kỹ thuật tương tự như ý tưởng tích chập nhóm. Mô hình này huấn luyện các khía cạnh khác nhau của các mô hình thu nhỏ có các lớp MHSA đã được sửa đổi.
Hiệu quả tham số
Các mô hình ViT trung bình kế thừa các chiến lược thiết kế của họ như sử dụng chiều rộng tương đương cho các hình chiếu, đặt tỷ lệ mở rộng thành 4 trong FFN và tăng đầu qua các giai đoạn từ máy biến áp NLP. Cấu hình của các thành phần này cần được thiết kế lại cẩn thận cho các mô-đun nhẹ. Mô hình Hiệu quảViT triển khai tính năng cắt tỉa có cấu trúc Taylor để tự động tìm các thành phần thiết yếu trong các lớp Swim-T và DeiT-T, đồng thời khám phá thêm các nguyên tắc phân bổ tham số cơ bản. Dưới những hạn chế về nguồn lực nhất định, các phương pháp cắt tỉa sẽ loại bỏ các kênh không quan trọng và giữ lại những kênh quan trọng để đảm bảo độ chính xác cao nhất có thể. Hình bên dưới so sánh tỷ lệ kênh với phần nhúng đầu vào trước và sau khi cắt bớt trên khung Swin-T. Quan sát thấy: Độ chính xác đường cơ sở: 79.1%; độ chính xác cắt tỉa: 76.5%.

Hình ảnh trên chỉ ra rằng hai giai đoạn đầu tiên của khung bảo toàn nhiều kích thước hơn, trong khi hai giai đoạn cuối bảo toàn ít kích thước hơn nhiều. Điều đó có thể có nghĩa là một cấu hình kênh điển hình sẽ nhân đôi kênh sau mỗi giai đoạn hoặc sử dụng các kênh tương đương cho tất cả các khối, có thể dẫn đến sự dư thừa đáng kể ở một số khối cuối cùng.
Biến áp tầm nhìn hiệu quả: Kiến trúc
Trên cơ sở những kiến thức thu được trong quá trình phân tích ở trên, các nhà phát triển đã nỗ lực tạo ra một mô hình phân cấp mới cung cấp tốc độ nhiễu nhanh, Hiệu quảViT người mẫu. Chúng ta hãy xem xét chi tiết cấu trúc của khung công tác EffiviT. Hình dưới đây cung cấp cho bạn ý tưởng chung về khung công tác EfficiencyViT.
Các khối xây dựng của Khung Hiệu quảViT
Khối xây dựng cho mạng máy biến áp tầm nhìn hiệu quả hơn được minh họa trong hình bên dưới.

Khung này bao gồm một mô-đun chú ý nhóm xếp tầng, bố cục bánh sandwich hiệu quả về bộ nhớ và chiến lược phân bổ lại tham số tập trung vào việc cải thiện hiệu quả của mô hình về mặt tính toán, bộ nhớ và tham số tương ứng. Hãy nói về chúng chi tiết hơn.
Bố cục bánh sandwich
Mô hình này sử dụng bố cục bánh sandwich mới để xây dựng khối bộ nhớ hiệu quả và hiệu quả hơn cho khung. Bố cục bánh sandwich sử dụng ít lớp tự chú ý hơn và sử dụng các mạng chuyển tiếp nguồn cấp dữ liệu hiệu quả hơn về bộ nhớ để liên lạc kênh. Cụ thể hơn, mô hình áp dụng một lớp tự chú ý duy nhất để trộn không gian được kẹp giữa các lớp FFN. Thiết kế không chỉ giúp giảm mức tiêu thụ thời gian bộ nhớ do các lớp tự chú ý mà còn cho phép liên lạc hiệu quả giữa các kênh khác nhau trong mạng nhờ sử dụng các lớp FFN. Mô hình này cũng áp dụng một lớp mã thông báo tương tác bổ sung trước mỗi lớp mạng chuyển tiếp nguồn cấp dữ liệu bằng cách sử dụng DWConv hoặc Convolution, đồng thời nâng cao năng lực của mô hình bằng cách đưa ra độ lệch quy nạp của thông tin cấu trúc cục bộ.
Sự chú ý của nhóm xếp tầng
Một trong những vấn đề chính với các lớp MHSA là sự dư thừa trong các đầu chú ý khiến việc tính toán trở nên kém hiệu quả hơn. Để giải quyết vấn đề, mô hình này đề xuất CGA hoặc Chú ý nhóm theo tầng cho các máy biến đổi tầm nhìn, một mô-đun chú ý mới lấy cảm hứng từ các tổ hợp nhóm trong CNN hiệu quả. Theo cách tiếp cận này, mô hình cung cấp cho từng phần tử đầu với sự phân chia đầy đủ các tính năng và do đó phân tách tính toán chú ý một cách rõ ràng trên các phần tử. Việc phân chia các tính năng thay vì cung cấp đầy đủ các tính năng cho mỗi đầu giúp tiết kiệm tính toán và làm cho quy trình hiệu quả hơn, đồng thời mô hình tiếp tục nỗ lực cải thiện độ chính xác và công suất của nó hơn nữa bằng cách khuyến khích các lớp tìm hiểu các dự báo về các tính năng có thông tin phong phú hơn.

Tái phân bổ tham số
Để nâng cao hiệu quả của các tham số, mô hình sẽ phân bổ lại các tham số trong mạng bằng cách mở rộng độ rộng kênh của các mô-đun quan trọng đồng thời thu hẹp độ rộng kênh của các mô-đun không quá quan trọng. Dựa trên phân tích của Taylor, mô hình đặt các kích thước kênh nhỏ cho các hình chiếu trong mỗi đầu trong mỗi giai đoạn hoặc mô hình cho phép các hình chiếu có cùng kích thước với đầu vào. Tỷ lệ mở rộng của mạng chuyển tiếp nguồn cấp dữ liệu cũng được giảm xuống 2 từ 4 để hỗ trợ dự phòng tham số. Chiến lược tái phân bổ được đề xuất mà khung EffityViT triển khai, phân bổ nhiều kênh hơn cho các mô-đun quan trọng để cho phép chúng tìm hiểu các cách biểu diễn trong không gian nhiều chiều tốt hơn nhằm giảm thiểu việc mất thông tin đối tượng. Hơn nữa, để tăng tốc quá trình can thiệp và nâng cao hiệu quả của mô hình hơn nữa, mô hình sẽ tự động loại bỏ các tham số dư thừa trong các mô-đun không quan trọng.

Tổng quan về khung công tác Hiệu quảViT có thể được giải thích trong hình trên, trong đó các bộ phận,
- Kiến trúc của EfficiencyViT,
- Khối bố trí Sandwich,
- Sự chú ý của nhóm xếp tầng.
Hiệu quảViT: Kiến trúc mạng

Hình ảnh trên tóm tắt kiến trúc mạng của khung công tác EviT. Mô hình này giới thiệu một bản vá chồng chéo nhúng [20,80] nhúng các bản vá 16 × 16 vào mã thông báo kích thước C1 nhằm nâng cao khả năng của mô hình để hoạt động tốt hơn trong việc học biểu diễn trực quan ở cấp độ thấp. Kiến trúc của mô hình bao gồm ba giai đoạn trong đó mỗi giai đoạn xếp chồng các khối xây dựng được đề xuất của khung EfficiencyViT và số lượng mã thông báo ở mỗi lớp lấy mẫu con (lấy mẫu con 2× của độ phân giải) giảm đi 4 lần. Để làm cho việc lấy mẫu con hiệu quả hơn, mô hình đề xuất một khối mẫu con cũng có bố cục bánh sandwich được đề xuất ngoại trừ khối dư đảo ngược sẽ thay thế lớp chú ý để giảm mất thông tin trong quá trình lấy mẫu. Hơn nữa, thay vì LayerNorm(LN) thông thường, mô hình này sử dụng BatchNorm(BN) vì BN có thể được xếp vào các lớp tuyến tính hoặc lớp chập trước đó, mang lại lợi thế về thời gian chạy so với LN.
Dòng mô hình Hiệu quảViT
Nhóm mô hình EfficiencyViT bao gồm 6 mô hình với các tỷ lệ chiều sâu và chiều rộng khác nhau và một số lượng đầu nhất định được phân bổ cho từng giai đoạn. Các mô hình sử dụng ít khối hơn trong giai đoạn đầu khi so sánh với các giai đoạn cuối, một quy trình tương tự như quy trình được tiếp theo bởi khung MobileNetV3 vì quy trình xử lý ở giai đoạn đầu với độ phân giải lớn hơn tốn nhiều thời gian. Chiều rộng được tăng dần qua các giai đoạn với hệ số nhỏ để giảm sự dư thừa ở các giai đoạn sau. Bảng đính kèm bên dưới cung cấp chi tiết kiến trúc của dòng mô hình EfficiencyViT trong đó C, L và H đề cập đến chiều rộng, chiều sâu và số lượng đầu trong giai đoạn cụ thể.

Hiệu quảViT: Triển khai mô hình và kết quả
Mô hình Hiệu quảViT có tổng kích thước lô là 2,048, được xây dựng bằng Timm & PyTorch, được đào tạo từ đầu trong 300 kỷ nguyên sử dụng 8 GPU Nvidia V100, sử dụng bộ lập lịch tốc độ học cosine, trình tối ưu hóa AdamW và tiến hành thử nghiệm phân loại hình ảnh trên ImageNet -1K. Hình ảnh đầu vào được cắt ngẫu nhiên và thay đổi kích thước thành độ phân giải 224×224. Đối với các thử nghiệm liên quan đến phân loại hình ảnh xuôi dòng, khung công tác EnoughViT sẽ tinh chỉnh mô hình trong 300 kỷ nguyên và sử dụng trình tối ưu hóa AdamW với kích thước lô là 256. Mô hình sử dụng RetineNet để phát hiện đối tượng trên COCO và tiến hành huấn luyện các mô hình trong 12 kỷ nguyên tiếp theo. kỷ nguyên với các cài đặt giống hệt nhau.
Kết quả trên ImageNet
Để phân tích hiệu suất của EfficiencyViT, nó được so sánh với các mô hình ViT & CNN hiện tại trên bộ dữ liệu ImageNet. Kết quả so sánh được báo cáo trong hình dưới đây. Như có thể thấy, dòng mô hình EfficiencyViT vượt trội hơn các khung hiện tại trong hầu hết các trường hợp và đạt được sự cân bằng lý tưởng giữa tốc độ và độ chính xác.

So sánh với CNN hiệu quả và ViT hiệu quả
Trước tiên, mô hình này so sánh hiệu suất của nó với các CNN hiệu quả như EfficiencyNet và các khung CNN cơ bản như MobileNets. Có thể thấy rằng khi so sánh với các khung MobileNet, các mô hình EfficiencyViT đạt được điểm chính xác top 1 tốt hơn, đồng thời chạy nhanh hơn lần lượt 3.0 lần và 2.5 lần trên CPU Intel và GPU V100.
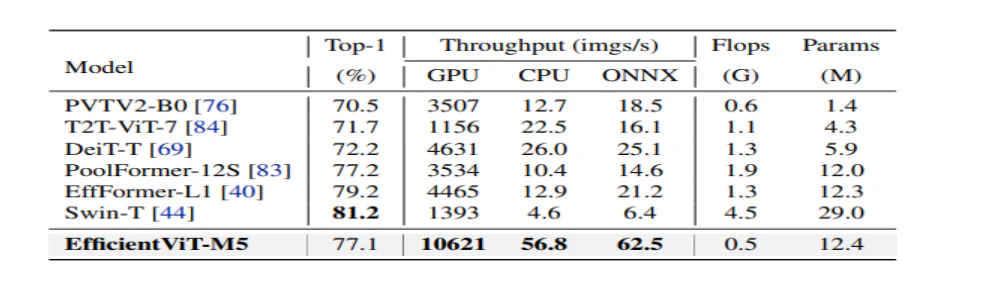
Hình trên so sánh hiệu suất của mô hình Hiệu quảViT với các mô hình ViT quy mô lớn hiện đại chạy trên bộ dữ liệu ImageNet-1K.
Phân loại hình ảnh xuôi dòng
Mô hình Hiệu quảViT được áp dụng cho các nhiệm vụ tiếp theo khác nhau để nghiên cứu khả năng học chuyển giao của mô hình và hình ảnh bên dưới tóm tắt kết quả của thử nghiệm. Như có thể thấy, mô hình EfficiencyViT-M5 quản lý để đạt được kết quả tốt hơn hoặc tương tự trên tất cả các tập dữ liệu trong khi vẫn duy trì thông lượng cao hơn nhiều. Ngoại lệ duy nhất là tập dữ liệu Ô tô, trong đó mô hình Hiệu quảViT không cung cấp độ chính xác.

Phát hiện đối tượng
Để phân tích khả năng phát hiện đối tượng của EfficiencyViT, nó được so sánh với các mô hình hiệu quả trong nhiệm vụ phát hiện đối tượng COCO và hình ảnh bên dưới tóm tắt kết quả so sánh.

Kết luận:
Trong bài viết này, chúng ta đã nói về EfficiencyViT, một dòng mô hình máy biến áp tầm nhìn nhanh sử dụng sự chú ý của nhóm theo tầng và cung cấp các hoạt động tiết kiệm bộ nhớ. Các thử nghiệm mở rộng được thực hiện để phân tích hiệu suất của EfficiencyViT đã cho thấy kết quả đầy hứa hẹn vì mô hình EffityViT vượt trội hơn các mô hình CNN và biến áp tầm nhìn hiện tại trong hầu hết các trường hợp. Chúng tôi cũng đã cố gắng đưa ra phân tích về các yếu tố đóng vai trò ảnh hưởng đến tốc độ nhiễu của máy biến áp thị giác.















