Trí tuệ nhân tạo
Hướng Dẫn Hoàn Chỉnh Về Gemma 2: Mô Hình Ngôn Ngữ Mở Lớn Mới Của Google

Gemma 2 xây dựng trên tiền đề của người tiền nhiệm, mang lại hiệu suất và hiệu quả được cải thiện, cùng với một bộ tính năng sáng tạo giúp nó trở nên đặc biệt hấp dẫn cho cả nghiên cứu và ứng dụng thực tế. Điều khiến Gemma 2 nổi bật là khả năng cung cấp hiệu suất tương đương với các mô hình độc quyền lớn hơn, nhưng trong một gói được thiết kế cho khả năng tiếp cận và sử dụng rộng rãi hơn trên các thiết lập phần cứng khiêm tốn.
Khi tôi深入 tìm hiểu các thông số kỹ thuật và kiến trúc của Gemma 2, tôi ngày càng ấn tượng với sự thông minh của thiết kế. Mô hình này kết hợp nhiều kỹ thuật tiên tiến, bao gồm các cơ chế chú ý mới và cách tiếp cận sáng tạo để ổn định quá trình đào tạo, giúp nó có khả năng đáng kinh ngạc.

Google Open Source LLM Gemma
Trong hướng dẫn toàn diện này, chúng tôi sẽ khám phá Gemma 2 một cách sâu sắc, kiểm tra kiến trúc, tính năng chính và ứng dụng thực tế. Dù bạn là một chuyên gia AI có kinh nghiệm hay một người mới tham gia vào lĩnh vực này, bài viết này nhằm cung cấp thông tin quý giá về cách Gemma 2 hoạt động và cách bạn có thể tận dụng sức mạnh của nó trong các dự án của mình.
What is Gemma 2?
Gemma 2 là mô hình ngôn ngữ mở lớn mới nhất của Google, được thiết kế để nhẹ nhưng mạnh mẽ. Nó được xây dựng trên cùng một nghiên cứu và công nghệ được sử dụng để tạo ra các mô hình Gemini của Google, mang lại hiệu suất hàng đầu trong một gói dễ tiếp cận hơn. Gemma 2 có hai kích thước:
Gemma 2 9B: Mô hình 9 tỷ tham số
Gemma 2 27B: Mô hình lớn hơn 27 tỷ tham số
Mỗi kích thước có hai biến thể:
Base models: Được đào tạo trước trên một tập dữ liệu văn bản lớn
Instruction-tuned (IT) models: Được tinh chỉnh để có hiệu suất tốt hơn trên các nhiệm vụ cụ thể
Truy cập các mô hình trong Google AI Studio: Google AI Studio – Gemma 2
Đọc báo cáo kỹ thuật tại đây: Báo Cáo Kỹ Thuật Gemma 2
Tính Năng và Cải Tiến Chính
Gemma 2 giới thiệu một số tiến bộ đáng kể so với người tiền nhiệm:
1. Dữ Liệu Đào Tạo Tăng
Các mô hình đã được đào tạo trên nhiều dữ liệu hơn:
Gemma 2 27B: Được đào tạo trên 13 nghìn tỷ token
Gemma 2 9B: Được đào tạo trên 8 nghìn tỷ token
Tập dữ liệu mở rộng này, chủ yếu bao gồm dữ liệu web (chủ yếu là tiếng Anh), mã và toán học, góp phần vào hiệu suất và tính linh hoạt của mô hình.
2. Chú Ý Cửa Sổ Trượt
Gemma 2 thực hiện một cách tiếp cận mới đối với các cơ chế chú ý:
Mỗi lớp khác sử dụng chú ý cửa sổ trượt với ngữ cảnh địa phương 4096 token
Các lớp xen kẽ sử dụng chú ý toàn cầu toàn phần trên toàn bộ ngữ cảnh 8192 token
Cách tiếp cận kết hợp này nhằm cân bằng giữa hiệu quả và khả năng bắt kịp các phụ thuộc dài trong đầu vào.
3. Mũ Mềm
Để cải thiện sự ổn định và hiệu suất đào tạo, Gemma 2 giới thiệu một cơ chế mũ mềm:
def soft_cap(x, cap): return cap * torch.tanh(x / cap) # Áp dụng cho logit chú ý attention_logits = soft_cap(attention_logits, cap=50.0) # Áp dụng cho logit lớp cuối final_logits = soft_cap(final_logits, cap=30.0)
Kỹ thuật này ngăn chặn logit không tăng quá lớn mà không cần cắt cứng, duy trì nhiều thông tin hơn đồng thời ổn định quá trình đào tạo.
- Gemma 2 9B: Mô hình 9 tỷ tham số
- Gemma 2 27B: Mô hình lớn hơn 27 tỷ tham số
Mỗi kích thước có hai biến thể:
- Base models: Được đào tạo trước trên một tập dữ liệu văn bản lớn
- Instruction-tuned (IT) models: Được tinh chỉnh để có hiệu suất tốt hơn trên các nhiệm vụ cụ thể
4. Truyền Đạt Kiến Thức
Đối với mô hình 9B, Gemma 2 sử dụng kỹ thuật truyền đạt kiến thức:
- Đào tạo trước: Mô hình 9B học từ một mô hình giáo viên lớn hơn trong quá trình đào tạo ban đầu
- Sau đào tạo: Cả hai mô hình 9B và 27B sử dụng truyền đạt chính sách để tinh chỉnh hiệu suất
Quá trình này giúp mô hình nhỏ hơn bắt kịp khả năng của mô hình lớn hơn một cách hiệu quả.
5. Kết Hợp Mô Hình
Gemma 2 sử dụng một kỹ thuật kết hợp mô hình mới gọi là Warp, kết hợp nhiều mô hình trong ba giai đoạn:
- Đường Diện Trung Bình Trượt (EMA) trong quá trình tinh chỉnh học tăng cường
- Tuyến Tính Spherical (SLERP) sau khi tinh chỉnh nhiều chính sách
- Tuyến Tính Đến Khởi Đầu (LITI) như một bước cuối cùng
Cách tiếp cận này nhằm tạo ra một mô hình cuối cùng mạnh mẽ và có khả năng hơn.
Benchmarks Hiệu Suất
Gemma 2 thể hiện hiệu suất ấn tượng trên nhiều benchmarks:
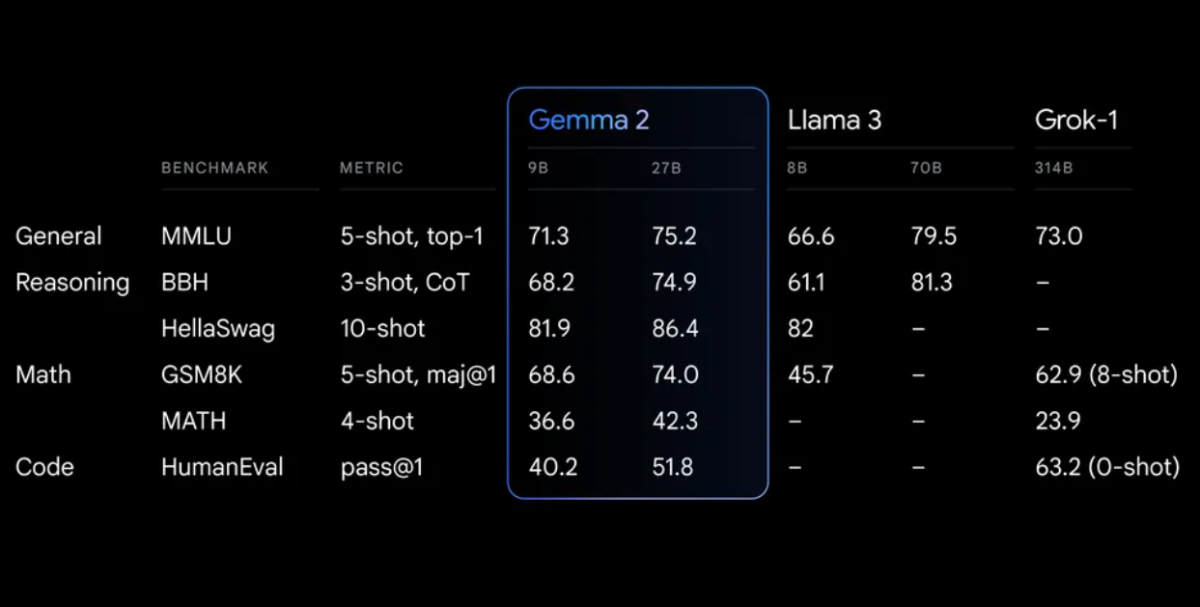
Gemma 2 trên kiến trúc được thiết kế lại, được thiết kế cho cả hiệu suất và hiệu quả suy luận
Bắt Đầu Với Gemma 2
Để bắt đầu sử dụng Gemma 2 trong các dự án của bạn, bạn có một số lựa chọn:
1. Google AI Studio
Để thử nghiệm nhanh mà không cần yêu cầu phần cứng, bạn có thể truy cập Gemma 2 thông qua Google AI Studio.
2. Hugging Face Transformers
Gemma 2 được tích hợp với thư viện Hugging Face Transformers phổ biến. Dưới đây là cách bạn có thể sử dụng nó:
<div class="relative flex flex-col rounded-lg"> <div class="text-text-300 absolute pl-3 pt-2.5 text-xs"> from transformers import AutoTokenizer, AutoModelForCausalLM # Tải mô hình và tokenizer model_name = "google/gemma-2-27b-it" # hoặc "google/gemma-2-9b-it" cho phiên bản nhỏ hơn tokenizer = AutoTokenizer.from_pretrained(model_name) model = AutoModelForCausalLM.from_pretrained(model_name) # Chuẩn bị đầu vào prompt = "Giải thích khái niệm về sự kết nối lượng tử bằng cách sử dụng các thuật ngữ đơn giản." inputs = tokenizer(prompt, return_tensors="pt") # Tạo văn bản outputs = model.generate(**inputs, max_length=200) response = tokenizer.decode(outputs[0], skip_special_tokens=True) print(response)
3. TensorFlow/Keras
Đối với người dùng TensorFlow, Gemma 2 có sẵn thông qua Keras:
import tensorflow as tf from keras_nlp.models import GemmaCausalLM # Tải mô hình model = GemmaCausalLM.from_preset("gemma_2b_en") # Tạo văn bản prompt = "Giải thích khái niệm về sự kết nối lượng tử bằng cách sử dụng các thuật ngữ đơn giản." output = model.generate(prompt, max_length=200) print(output)
Sử Dụng Nâng Cao: Xây Dựng Hệ Thống RAG Địa Phương Với Gemma 2
Một ứng dụng mạnh mẽ của Gemma 2 là xây dựng Hệ Thống Tạo RAG (Retrieval Augmented Generation). Hãy tạo một hệ thống RAG địa phương đơn giản sử dụng Gemma 2 và Nomic embeddings.
Bước 1: Thiết Lập Môi Trường
Đầu tiên, hãy đảm bảo bạn đã cài đặt các thư viện cần thiết:
pip install langchain ollama nomic chromadb
Bước 2: Chỉ Số Tài Liệu
Tạo một chỉ số để xử lý tài liệu của bạn:
import os
from langchain.text_splitter import RecursiveCharacterTextSplitter
from langchain.document_loaders import DirectoryLoader
from langchain.vectorstores import Chroma
from langchain.embeddings import HuggingFaceEmbeddings












