Trí tuệ nhân tạo
Hướng dẫn đầy đủ về Gemma 2: Mô hình ngôn ngữ lớn mở mới của Google

đá quý 2 được xây dựng dựa trên phiên bản tiền nhiệm, mang lại hiệu suất và hiệu quả vượt trội, cùng với bộ tính năng cải tiến đặc biệt hấp dẫn cho cả ứng dụng nghiên cứu và thực tiễn. Điểm khác biệt của Gemma 2 là khả năng mang lại hiệu suất tương đương với các mẫu máy độc quyền lớn hơn nhiều, nhưng được thiết kế để dễ dàng tiếp cận và sử dụng trên các thiết lập phần cứng khiêm tốn hơn.
Khi đi sâu vào các thông số kỹ thuật và kiến trúc của Gemma 2, tôi càng thấy mình bị ấn tượng bởi sự khéo léo trong thiết kế của nó. Mô hình này kết hợp một số kỹ thuật tiên tiến, bao gồm các cơ chế chú ý mới và các phương pháp tiếp cận sáng tạo để ổn định quá trình đào tạo, góp phần tạo nên những khả năng vượt trội của nó.

Mã nguồn mở LLM Gemma của Google
Trong hướng dẫn toàn diện này, chúng ta sẽ khám phá sâu hơn về Gemma 2, xem xét kiến trúc, các tính năng chính và ứng dụng thực tế của nó. Cho dù bạn là một chuyên gia AI dày dạn kinh nghiệm hay một người mới bắt đầu đầy nhiệt huyết, bài viết này sẽ cung cấp những hiểu biết giá trị về cách Gemma 2 hoạt động và cách bạn có thể tận dụng sức mạnh của nó trong các dự án của riêng mình.
Gemma 2 là gì?
Gemma 2 là mô hình ngôn ngữ lớn mã nguồn mở mới nhất của Google, được thiết kế nhẹ nhưng mạnh mẽ. Nó được xây dựng dựa trên cùng một nghiên cứu và công nghệ được sử dụng để tạo ra các mô hình Gemini của Google, mang đến hiệu suất tiên tiến trong một gói dễ tiếp cận hơn. Gemma 2 có hai kích cỡ:
Gemma 2 9B: Mô hình tham số 9 tỷ
Gemma 2 27B: Một mô hình tham số lớn hơn 27 tỷ
Mỗi kích thước có sẵn trong hai biến thể:
mô hình cơ sở: Được đào tạo trước trên một kho dữ liệu văn bản khổng lồ
Các mô hình điều chỉnh theo hướng dẫn (IT): Tinh chỉnh để có hiệu suất tốt hơn trong các tác vụ cụ thể
Truy cập các mô hình trong Google AI Studio: Studio AI của Google – Gemma 2
Đọc bài báo tại đây: Báo cáo kỹ thuật Gemma 2
Các tính năng và cải tiến chính
Gemma 2 giới thiệu một số cải tiến đáng kể so với phiên bản tiền nhiệm:
1. Tăng dữ liệu đào tạo
Các mô hình đã được đào tạo về cơ bản nhiều dữ liệu hơn:
Gemma 2 27B: Được đào tạo trên 13 nghìn tỷ token
Gemma 2 9B: Được đào tạo trên 8 nghìn tỷ token
Bộ dữ liệu mở rộng này, chủ yếu bao gồm dữ liệu web (chủ yếu là tiếng Anh), mã và toán học, góp phần cải thiện hiệu suất và tính linh hoạt của các mô hình.
2. Chú ý cửa sổ trượt
Gemma 2 thực hiện một cách tiếp cận mới đối với cơ chế chú ý:
Mọi lớp khác sử dụng sự chú ý của cửa sổ trượt với bối cảnh cục bộ là 4096 mã thông báo
Các lớp xen kẽ sử dụng toàn bộ sự chú ý toàn cầu bậc hai trên toàn bộ bối cảnh mã thông báo 8192
Cách tiếp cận kết hợp này nhằm mục đích cân bằng giữa hiệu quả với khả năng nắm bắt các yếu tố phụ thuộc tầm xa trong đầu vào.
3. Đóng nắp mềm
Để cải thiện tính ổn định và hiệu suất tập luyện, Gemma 2 giới thiệu cơ chế giới hạn mềm:
def soft_cap(x, cap):
return cap * torch.tanh(x / cap)
# Applied to attention logits
attention_logits = soft_cap(attention_logits, cap=50.0)
# Applied to final layer logits
final_logits = soft_cap(final_logits, cap=30.0)
Kỹ thuật này ngăn chặn các bản ghi phát triển quá lớn mà không cần cắt bớt, duy trì nhiều thông tin hơn trong khi ổn định quá trình đào tạo.
- Gemma 2 9B: Mô hình tham số 9 tỷ
- Gemma 2 27B: Một mô hình tham số lớn hơn 27 tỷ
Mỗi kích thước có sẵn trong hai biến thể:
- Mô hình cơ sở: Được đào tạo trước trên kho dữ liệu văn bản khổng lồ
- Mô hình được điều chỉnh theo hướng dẫn (IT): Được tinh chỉnh để có hiệu suất tốt hơn đối với các tác vụ cụ thể
4. Chắt lọc kiến thức
Đối với mô hình 9B, Gemma 2 sử dụng các kỹ thuật chắt lọc kiến thức:
- Đào tạo trước: Mô hình 9B học từ mô hình giáo viên lớn hơn trong quá trình đào tạo ban đầu
- Sau đào tạo: Cả hai mô hình 9B và 27B đều sử dụng phương pháp chắt lọc theo chính sách để tinh chỉnh hiệu suất của chúng
Quá trình này giúp mô hình nhỏ hơn nắm bắt được khả năng của các mô hình lớn hơn một cách hiệu quả hơn.
5. Hợp nhất mô hình
Gemma 2 sử dụng kỹ thuật hợp nhất mô hình mới có tên Warp, kết hợp nhiều mô hình theo ba giai đoạn:
- Đường trung bình động hàm mũ (EMA) trong quá trình tinh chỉnh học tăng cường
- IntERPolation tuyến tính hình cầu (SLERP) sau khi tinh chỉnh nhiều chính sách
- Nội suy tuyến tính hướng tới khởi tạo (LITI) là bước cuối cùng
Cách tiếp cận này nhằm mục đích tạo ra một mô hình cuối cùng mạnh mẽ và có khả năng hơn.
Điểm chuẩn hiệu suất
Gemma 2 thể hiện hiệu suất ấn tượng trên nhiều tiêu chuẩn khác nhau:
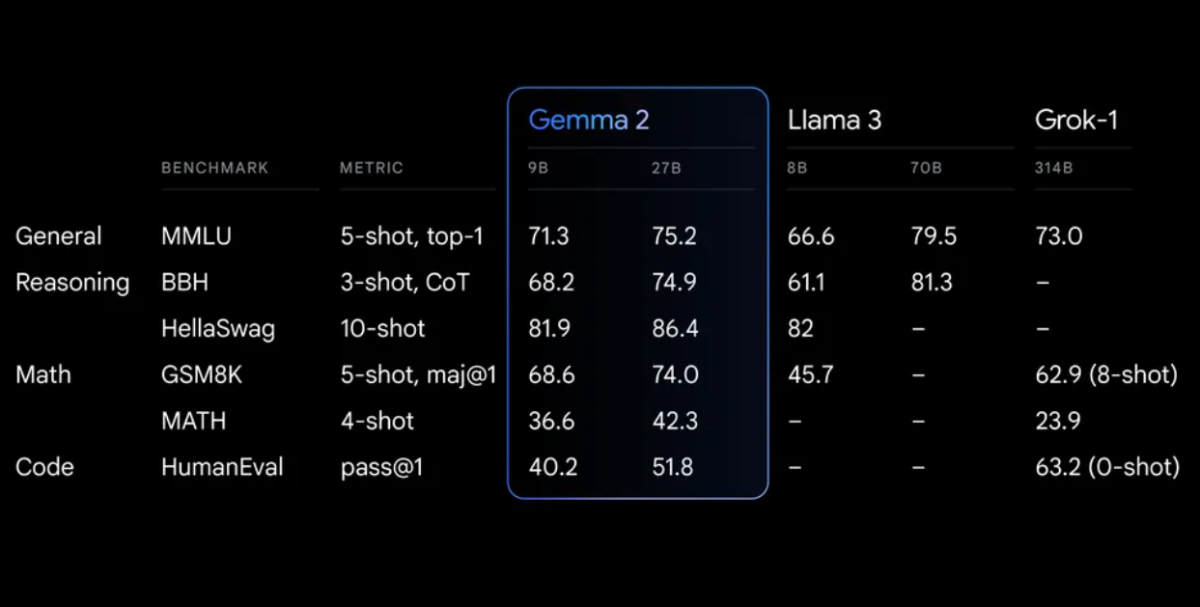
Gemma 2 trên kiến trúc được thiết kế lại, được thiết kế để mang lại cả hiệu suất vượt trội và hiệu quả suy luận
Bắt đầu với Gemma 2
Để bắt đầu sử dụng Gemma 2 trong dự án của mình, bạn có một số tùy chọn:
1. Phòng thu AI của Google
Để thử nghiệm nhanh mà không yêu cầu phần cứng, bạn có thể truy cập Gemma 2 thông qua Studio AI của Google.
2. Máy biến hình ôm mặt
Gemma 2 được tích hợp phổ biến Ôm mặt Thư viện Transformers. Sau đây là cách bạn có thể sử dụng:
<div class="relative flex flex-col rounded-lg"> <div class="text-text-300 absolute pl-3 pt-2.5 text-xs"> from transformers import AutoTokenizer, AutoModelForCausalLM # Load the model and tokenizer model_name = "google/gemma-2-27b-it" # or "google/gemma-2-9b-it" for the smaller version tokenizer = AutoTokenizer.from_pretrained(model_name) model = AutoModelForCausalLM.from_pretrained(model_name) # Prepare input prompt = "Explain the concept of quantum entanglement in simple terms." inputs = tokenizer(prompt, return_tensors="pt") # Generate text outputs = model.generate(**inputs, max_length=200) response = tokenizer.decode(outputs[0], skip_special_tokens=True) print(response)
3. TensorFlow/Keras
Đối với người dùng TensorFlow, Gemma 2 có sẵn thông qua Keras:
import tensorflow as tf
from keras_nlp.models import GemmaCausalLM
# Load the model
model = GemmaCausalLM.from_preset("gemma_2b_en")
# Generate text
prompt = "Explain the concept of quantum entanglement in simple terms."
output = model.generate(prompt, max_length=200)
print(output)
Cách sử dụng nâng cao: Xây dựng hệ thống RAG cục bộ với Gemma 2
Một ứng dụng mạnh mẽ của Gemma 2 là xây dựng hệ thống Retrieval Augmented Generation (RAG). Hãy cùng tạo một hệ thống RAG đơn giản, hoàn toàn cục bộ bằng cách sử dụng Gemma 2 và nhúng Nomic.
Bước 1: Thiết lập môi trường
Trước tiên, hãy đảm bảo bạn đã cài đặt các thư viện cần thiết:
pip install langchain ollama nomic chromadb
Bước 2: Lập chỉ mục tài liệu
Tạo một bộ chỉ mục để xử lý tài liệu của bạn:
import os
from langchain.text_splitter import RecursiveCharacterTextSplitter
from langchain.document_loaders import DirectoryLoader
from langchain.vectorstores import Chroma
from langchain.embeddings import HuggingFaceEmbeddings
class Indexer:
def __init__(self, directory_path):
self.directory_path = directory_path
self.text_splitter = RecursiveCharacterTextSplitter(chunk_size=1000, chunk_overlap=200)
self.embeddings = HuggingFaceEmbeddings(model_name="nomic-ai/nomic-embed-text-v1")
def load_and_split_documents(self):
loader = DirectoryLoader(self.directory_path, glob="**/*.txt")
documents = loader.load()
return self.text_splitter.split_documents(documents)
def create_vector_store(self, documents):
return Chroma.from_documents(documents, self.embeddings, persist_directory="./chroma_db")
def index(self):
documents = self.load_and_split_documents()
vector_store = self.create_vector_store(documents)
vector_store.persist()
return vector_store
# Usage
indexer = Indexer("path/to/your/documents")
vector_store = indexer.index()
Bước 3: Thiết lập hệ thống RAG
Bây giờ, chúng ta hãy tạo hệ thống RAG bằng Gemma 2:
from langchain.llms import Ollama
from langchain.chains import RetrievalQA
from langchain.prompts import PromptTemplate
class RAGSystem:
def __init__(self, vector_store):
self.vector_store = vector_store
self.llm = Ollama(model="gemma2:9b")
self.retriever = self.vector_store.as_retriever(search_kwargs={"k": 3})
self.template = """Use the following pieces of context to answer the question at the end.
If you don't know the answer, just say that you don't know, don't try to make up an answer.
{context}
Question: {question}
Answer: """
self.qa_prompt = PromptTemplate(
template=self.template, input_variables=["context", "question"]
)
self.qa_chain = RetrievalQA.from_chain_type(
llm=self.llm,
chain_type="stuff",
retriever=self.retriever,
return_source_documents=True,
chain_type_kwargs={"prompt": self.qa_prompt}
)
def query(self, question):
return self.qa_chain({"query": question})
# Usage
rag_system = RAGSystem(vector_store)
response = rag_system.query("What is the capital of France?")
print(response["result"])
Hệ thống RAG này sử dụng Gemma 2 đến Ollama cho mô hình ngôn ngữ và nhúng Nomic để truy xuất tài liệu. Nó cho phép bạn đặt câu hỏi dựa trên các tài liệu được lập chỉ mục, cung cấp câu trả lời kèm theo ngữ cảnh từ các nguồn có liên quan.
Tinh chỉnh Gemma 2
Đối với các tác vụ hoặc miền cụ thể, bạn có thể muốn tinh chỉnh Gemma 2. Sau đây là một ví dụ cơ bản sử dụng thư viện Hugging Face Transformers:
from transformers import AutoTokenizer, AutoModelForCausalLM, TrainingArguments, Trainer
from datasets import load_dataset
# Load model and tokenizer
model_name = "google/gemma-2-9b-it"
tokenizer = AutoTokenizer.from_pretrained(model_name)
model = AutoModelForCausalLM.from_pretrained(model_name)
# Prepare dataset
dataset = load_dataset("your_dataset")
def tokenize_function(examples):
return tokenizer(examples["text"], padding="max_length", truncation=True)
tokenized_datasets = dataset.map(tokenize_function, batched=True)
# Set up training arguments
training_args = TrainingArguments(
output_dir="./results",
num_train_epochs=3,
per_device_train_batch_size=4,
per_device_eval_batch_size=4,
warmup_steps=500,
weight_decay=0.01,
logging_dir="./logs",
)
# Initialize Trainer
trainer = Trainer(
model=model,
args=training_args,
train_dataset=tokenized_datasets["train"],
eval_dataset=tokenized_datasets["test"],
)
# Start fine-tuning
trainer.train()
# Save the fine-tuned model
model.save_pretrained("./fine_tuned_gemma2")
tokenizer.save_pretrained("./fine_tuned_gemma2")
Hãy nhớ điều chỉnh các thông số đào tạo dựa trên yêu cầu cụ thể và nguồn lực tính toán của bạn.
Những cân nhắc và hạn chế về mặt đạo đức
Mặc dù Gemma 2 cung cấp những khả năng ấn tượng, nhưng điều quan trọng là phải nhận thức được những hạn chế và cân nhắc về mặt đạo đức của nó:
- Bias: Giống như tất cả các mô hình ngôn ngữ, Gemma 2 có thể phản ánh những thành kiến có trong dữ liệu huấn luyện của nó. Luôn đánh giá nghiêm túc kết quả đầu ra của nó.
- Tính chính xác: Mặc dù có khả năng cao nhưng Gemma 2 đôi khi có thể tạo ra thông tin không chính xác hoặc không nhất quán. Xác minh các sự kiện quan trọng từ các nguồn đáng tin cậy.
- Độ dài ngữ cảnh: Gemma 2 có độ dài ngữ cảnh là 8192 mã thông báo. Đối với các tài liệu hoặc cuộc hội thoại dài hơn, bạn có thể cần triển khai các chiến lược để quản lý ngữ cảnh một cách hiệu quả.
- Tài nguyên tính toán: Đặc biệt đối với mô hình 27B, có thể cần có nguồn lực tính toán đáng kể để suy luận và tinh chỉnh hiệu quả.
- Sử dụng có trách nhiệm: Tuân thủ các thông lệ AI có trách nhiệm của Google và đảm bảo việc bạn sử dụng Gemma 2 phù hợp với các nguyên tắc AI có đạo đức.
Kết luận
Các tính năng nâng cao của Gemma 2 như chú ý đến cửa sổ trượt, giới hạn mềm và kỹ thuật hợp nhất mô hình mới khiến nó trở thành một công cụ mạnh mẽ cho nhiều tác vụ xử lý ngôn ngữ tự nhiên.
Bằng cách tận dụng Gemma 2 trong các dự án của bạn, cho dù thông qua suy luận đơn giản, hệ thống RAG phức tạp hay mô hình tinh chỉnh cho các miền cụ thể, bạn có thể khai thác sức mạnh của SOTA AI trong khi duy trì quyền kiểm soát dữ liệu và quy trình của mình.












