Trí tuệ nhân tạo
Thay đổi cảm xúc trong đoạn phim bằng Trí tuệ nhân tạo

Các nhà nghiên cứu từ Hy Lạp và Vương quốc Anh đã phát triển một phương pháp học sâu mới để thay đổi biểu cảm và tâm trạng rõ ràng của mọi người trong đoạn phim, đồng thời bảo tồn tính trung thực của chuyển động môi của họ so với âm thanh gốc theo cách mà các nỗ lực trước đây không thể sánh được.

Từ video đi kèm với bài báo (đính kèm ở cuối bài viết này), một đoạn ngắn về diễn viên Al Pacino có biểu cảm của anh được thay đổi tinh vi bởi NED, dựa trên các khái niệm ngữ nghĩa cấp cao định nghĩa các biểu cảm khuôn mặt cá nhân và cảm xúc liên quan của chúng. Phương pháp ‘Reference-Driven’ ở bên phải lấy cảm xúc được giải thích từ video nguồn và áp dụng nó cho toàn bộ chuỗi video. Source: https://www.youtube.com/watch?v=Li6W8pRDMJQ
Lĩnh vực này thuộc vào danh mục ngày càng tăng của cảm xúc được tạo sâu, nơi danh tính của người nói gốc được bảo tồn, nhưng biểu cảm và vi biểu cảm của họ được thay đổi. Khi công nghệ Trí tuệ nhân tạo này trưởng thành, nó cung cấp khả năng cho các sản xuất phim và truyền hình để thực hiện các thay đổi tinh vi đối với biểu cảm của diễn viên – nhưng cũng mở ra một danh mục mới của ‘video tạo sâu cảm xúc’.
Thay đổi khuôn mặt
Biểu cảm khuôn mặt của các nhân vật công chúng, như các chính trị gia, được chăm sóc cẩn thận; vào năm 2016, biểu cảm khuôn mặt của Hillary Clinton đã đứng dưới sự kiểm tra nghiêm ngặt của truyền thông về tác động tiêu cực tiềm tàng của chúng đối với triển vọng bầu cử của bà; biểu cảm khuôn mặt, như đã biết, cũng là một chủ đề quan tâm đối với FBI; và chúng là chỉ số quan trọng trong các cuộc phỏng vấn việc làm, khiến cho việc phát triển một bộ lọc ‘kiểm soát biểu cảm’ trực tiếp trở thành một phát triển mong muốn cho những người tìm việc đang cố gắng vượt qua vòng sơ loại trên Zoom.
Một nghiên cứu năm 2005 từ Vương quốc Anh đã khẳng định rằng ngoại hình khuôn mặt ảnh hưởng đến quyết định bầu cử, trong khi một bài viết năm 2019 của Washington Post đã xem xét sử dụng các đoạn video ‘không phù hợp với ngữ cảnh’, điều này hiện là điều gần nhất mà những người ủng hộ tin giả có thể làm để thực sự thay đổi cách một nhân vật công chúng dường như đang hành xử, phản ứng hoặc cảm nhận.
Hướng tới Điều khiển Biểu cảm Neural
Hiện tại, tình trạng nghệ thuật trong việc điều khiển ảnh hưởng khuôn mặt khá thô sơ, vì nó liên quan đến việc phân tách các khái niệm cấp cao (như buồn, giận dữ, hạnh phúc, cười) từ nội dung video thực tế. Mặc dù các kiến trúc deepfake truyền thống dường như đạt được sự phân tách này khá tốt, nhưng việc phản ánh cảm xúc trên các danh tính khác nhau vẫn yêu cầu hai tập dữ liệu khuôn mặt đào tạo phải chứa các biểu cảm tương ứng cho mỗi danh tính.

Typical examples of face images in datasets used to train deepfakes. Hiện tại, bạn chỉ có thể thay đổi biểu cảm khuôn mặt của một người bằng cách tạo ra các đường dẫn biểu cảm cụ thể cho mỗi danh tính trong mạng nơ-ron deepfake. Phần mềm deepfake năm 2017 không có sự hiểu biết nội tại, ngữ nghĩa về một ‘nụ cười’ – nó chỉ ánh xạ và khớp các thay đổi về hình học khuôn mặt giữa hai đối tượng.
Điều mong muốn, và chưa được thực hiện hoàn hảo, là nhận ra cách chủ thể B (ví dụ) cười, và đơn giản tạo một ‘nút cười’ trong kiến trúc, mà không cần ánh xạ nó đến một hình ảnh tương đương của chủ thể A cười.
Bài báo mới có tiêu đề Neural Emotion Director: Speech-preserving semantic control of facial expressions in “in-the-wild” videos, và đến từ các nhà nghiên cứu tại Trường Điện và Máy tính tại Đại học Kỹ thuật Quốc gia Athens, Viện Khoa học Máy tính tại Quỹ Nghiên cứu và Công nghệ Hellas (FORTH), và Trường Kỹ thuật, Toán và Khoa học Vật lý tại Đại học Exeter ở Vương quốc Anh.
Đội ngũ đã phát triển một khuôn khổ gọi là Neural Emotion Director (NED), bao gồm một mạng lưới dịch chuyển cảm xúc dựa trên 3D, 3D-Based Emotion Manipulator.
NED lấy một chuỗi tham số biểu cảm nhận được và dịch chúng sang một miền đích. Nó được đào tạo trên dữ liệu không song song, điều này có nghĩa là không cần thiết phải đào tạo trên các tập dữ liệu mà mỗi danh tính có các biểu cảm khuôn mặt tương ứng.
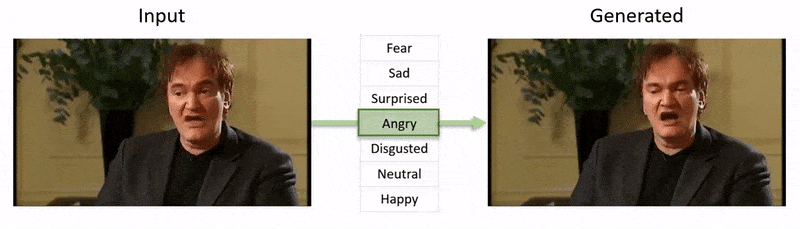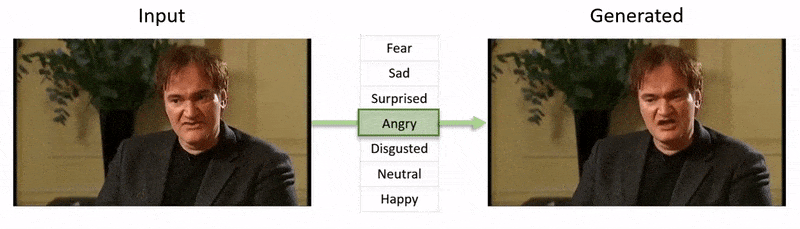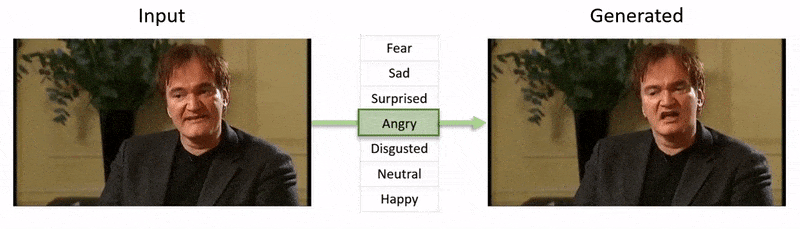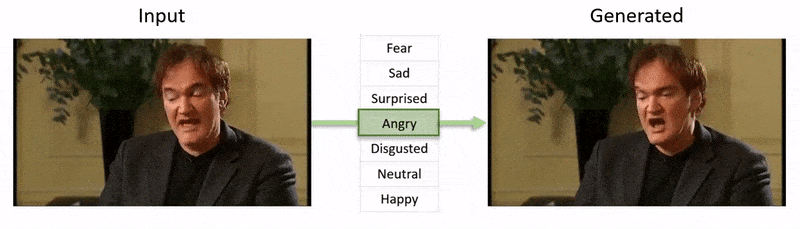
Video, được hiển thị ở cuối bài viết này, chạy qua một loạt các thử nghiệm nơi NED áp đặt một trạng thái cảm xúc rõ ràng lên footage từ tập dữ liệu YouTube.
Các tác giả tuyên bố rằng NED là phương pháp đầu tiên dựa trên video để ‘điều khiển’ diễn viên trong các tình huống ngẫu nhiên và khó dự đoán, và đã làm cho mã có sẵn trên trang dự án NED.
Phương pháp và Kiến trúc
Hệ thống được đào tạo trên hai tập dữ liệu video lớn đã được chú thích với các nhãn ‘cảm xúc’.
Đầu ra được kích hoạt bởi một bộ kết xuất khuôn mặt video mà kết xuất cảm xúc mong muốn đến video bằng cách sử dụng các kỹ thuật tổng hợp hình ảnh khuôn mặt truyền thống, bao gồm phân đoạn khuôn mặt, căn chỉnh điểm mốc khuôn mặt và trộn, nơi chỉ khu vực khuôn mặt được tổng hợp và sau đó áp đặt lên footage gốc.

Kiến trúc cho đường ống của Neural Emotion Detector (NED). Source: https://arxiv.org/pdf/2112.00585.pdf
Ban đầu, hệ thống thu được phục hồi khuôn mặt 3D và áp đặt căn chỉnh điểm mốc khuôn mặt lên các khung hình đầu vào để xác định biểu cảm. Sau đó, các tham số biểu cảm được phục hồi này được truyền đến 3D-Based Emotion Manipulator, và một vectơ phong cách được tính toán bằng cách sử dụng một nhãn ngữ nghĩa (như ‘hạnh phúc’) hoặc bằng một tệp tham chiếu.
Một tệp tham chiếu là một video thể hiện một biểu cảm / cảm xúc được công nhận cụ thể, sau đó được áp đặt lên toàn bộ video đích, thay thế biểu cảm gốc.

Các giai đoạn trong đường ống chuyển cảm xúc, với các diễn viên khác nhau được lấy mẫu từ video YouTube.
Hình dạng khuôn mặt 3D được tạo cuối cùng sau đó được kết hợp với Tọa độ Mặt Trung bình Bình thường hóa (NMFC) và hình ảnh mắt (được biểu thị bằng các chấm đỏ trong hình ảnh trên), và được truyền đến bộ kết xuất nơ-ron, thực hiện thao tác cuối cùng.
Kết quả
Các nhà nghiên cứu đã thực hiện các nghiên cứu rộng rãi, bao gồm cả nghiên cứu người dùng và nghiên cứu loại bỏ, để đánh giá hiệu quả của phương pháp so với các công việc trước đó, và phát hiện ra rằng trong hầu hết các danh mục, NED vượt trội so với tình trạng hiện tại của nghệ thuật trong phân khúc điều khiển khuôn mặt nơ-ron này.

Các tác giả của bài báo hình dung rằng các triển khai sau này của công việc này, và các công cụ tương tự, sẽ hữu ích chủ yếu trong ngành công nghiệp truyền hình và điện ảnh, tuyên bố:
‘Phương pháp của chúng tôi mở ra rất nhiều khả năng mới cho các ứng dụng hữu ích của công nghệ kết xuất nơ-ron, từ hậu sản xuất phim và trò chơi video đến các hình đại diện cảm xúc siêu thực.’
Đây là một công việc đầu tiên trong lĩnh vực này, nhưng một trong những công việc đầu tiên cố gắng tái tạo khuôn mặt với video chứ không phải hình ảnh tĩnh. Mặc dù video về cơ bản là nhiều hình ảnh tĩnh được chạy cùng nhau rất nhanh, nhưng có các yếu tố thời gian làm cho các ứng dụng trước đó của chuyển cảm xúc kém hiệu quả hơn. Trong video đi kèm và các ví dụ trong bài báo, các tác giả bao gồm các so sánh trực quan về đầu ra của NED so với các phương pháp gần đây khác.

Các so sánh chi tiết hơn và nhiều ví dụ hơn về NED có thể được tìm thấy trong video đầy đủ dưới đây:
3 tháng 12 năm 2021, 18:30 GMT+2 – Theo yêu cầu của một trong những tác giả của bài báo, các sửa đổi đã được thực hiện liên quan đến ‘tệp tham chiếu’, mà tôi đã tuyên bố sai là một bức ảnh tĩnh (khi nó thực sự là một đoạn video). Ngoài ra, một sửa đổi đối với tên của Viện Khoa học Máy tính tại Quỹ Nghiên cứu và Công nghệ.
3 tháng 12 năm 2021, 20:50 GMT+2 – Một yêu cầu thứ hai từ một trong những tác giả của bài báo để sửa đổi thêm tên của tổ chức trên.












