Yapay Zekâ 101
Peşıştımlı Öğrenme Nedir?
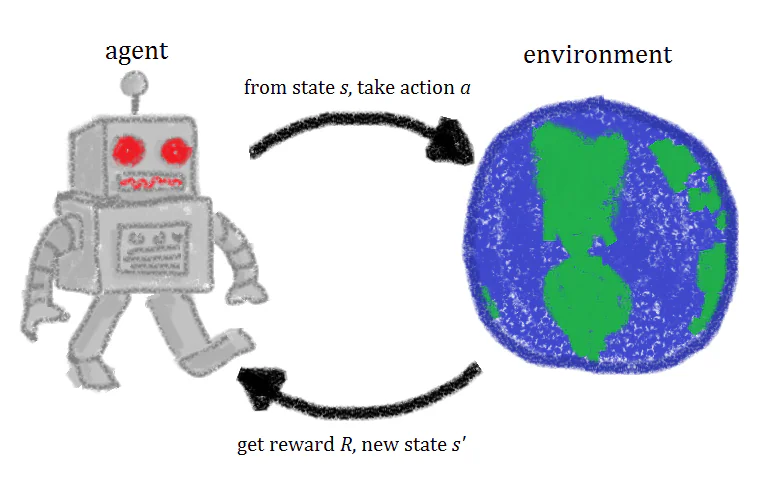
Peşıştımlı Öğrenme Nedir?
Basitçe ifade etmek gerekirse, peşiştimli öğrenme, yapay zeka ajanlarını tekrar eden eylemler ve bunlarla ilgili ödüller aracılığıyla eğiten bir makine öğrenimi tekniğidir. Bir peşiştimli öğrenme ajanı, bir ortamda dener, eylemler gerçekleştirir ve doğru eylemler gerçekleştirildiğinde ödüllendirilir. Zamanla, ajan ödüllendirilmesini en üst düzeye çıkarmak için eylemleri öğrenir. Bu, peşiştimli öğrenmenin kısa bir tanımlamasıdır, ancak peşiştimli öğrenmenin arkasındaki kavramlara daha yakından bakmak, size bundan daha iyi ve daha sezgisel bir anlayış kazandıracaktır.
“Peşıştımlı öğrenme” terimi, psikolojideki peşiştim kavramından uyarlanmıştır. Bu nedenle, psikoijik peşiştim kavramını anlamak için bir an durup inceleyelim. Psikolojik anlamda, peşiştim terimi, belirli bir yanıtın/eylemin meydana gelme olasılığını artıran bir şeyi ifade eder. Bu peşiştim kavramı, operant koşullanma teorisinin merkezi bir fikridir ve ilk olarak psikolog B.F. Skinner tarafından önerilmiştir. Bu bağlamda, peşiştim, belirli bir davranışın sıklığını artıran her şeydir. İnsanların olası peşiştimlerini düşünürsek, bunlar övgü, işyerinde terfi, şeker ve eğlenceli faaliyetler gibi şeyler olabilir.
Geleneksel, psikolojik anlamda, iki tür peşiştim vardır. Pozitif peşiştim ve negatif peşiştim vardır. Pozitif peşiştim, bir davranışı artırmak için bir şey eklemektir, örneğin iyi davranış gösteren köpeğinize bir ödül vermek gibi. Negatif peşiştim, bir davranışı ortaya çıkarmak için bir uyaranı ortadan kaldırmayı içerir, örneğin bir kedinin çıkmasını sağlamak için yüksek sesli gürültüleri kapatmak gibi.
Pozitif ve Negatif Peşıştımlı Öğrenme
Pozitif peşiştim, bir davranışı artırırken, negatif peşiştim bir davranışı azaltır. Genel olarak, peşiştimli öğrenmede en çok kullanılan peşiştim türü, pozitif peşiştimdir, çünkü modellerin belirli bir görevde performansı en üst düzeye çıkarmalarına yardımcı olur. Ayrıca, pozitif peşiştim, modelin daha sürdürülebilir değişiklikler yapmasına, uzun süreler boyunca devam eden kalıplar oluşturmasına yol açar.
Öte yandan, negatif peşiştim de bir davranışı daha olası hale getirse de, minimum performans standardını korumak için kullanılır, modelin maksimum performansına ulaşması için değil. Peşıştımlı öğrenmede negatif peşiştim, bir modelin istenmeyen eylemlerden uzak tutulmasına yardımcı olabilir, ancak bir modelin arzulanan eylemleri keşfetmesine gerçekten neden olamaz.
Peşıştımlı Öğrenme Ajanını Eğitmek
Bir peşiştimli öğrenme ajanı eğitildiğinde, dört farklı bileşen veya durumlar eğitimde kullanılır: ilk durumlar (Durum 0), yeni durum (Durum 1), eylemler ve ödüller.
Şöyle bir düşünün: bir platform oyununda AI’nın amacı, ekranın sağ tarafına doğru ilerleyerek seviyenin sonuna ulaşmak olan bir peşiştimli öğrenme ajanını eğitiyoruz. Oyunun ilk durumu, ortamdan elde edilir, yani oyunun ilk karesi analiz edilir ve modele verilir. Bu bilgilere dayanarak, model bir eylem kararı vermelidir.
Eğitim过程inin ilk aşamalarında, bu eylemler rastgeledir, ancak model peşiştimli öğrenme ile güçlendirildikçe, belirli eylemler daha yaygın hale gelir. Eylem gerçekleştirildikten sonra, oyun ortamı güncellenir ve yeni bir durum veya kare oluşturulur. Eğer ajanın gerçekleştirdiği eylem arzulanan bir sonuç ürettiyse, örneğin bu durumda ajan hala hayattadır ve bir düşman tarafından vurulmadıysa, ajana bir ödül verilir ve gelecekte aynı eylemi gerçekleştirmesi daha olası hale gelir.
Bu temel sistem sürekli olarak tekrarlanır ve her tekrarında ajan biraz daha fazla şey öğrenir ve ödüllerini en üst düzeye çıkarmaya çalışır.
Epizodik Karşı Devam Eden Görevler
Peşıştımlı öğrenme görevleri genellikle iki farklı kategoriye yerleştirilebilir: epizodik görevler ve sürekli görevler.
Epizodik görevler, öğrenme/öğretim döngüsünü gerçekleştirir ve performanslarını geliştirir, sonra belirli bir sonlandırma ölçütü karşılanana kadar eğitim sonlandırılır. Bir oyunda, bu, seviyenin sonuna ulaşmak veya bir tehlikeye düşmek gibi olabilir. Öte yandan, sürekli görevler, bir sonlandırma ölçütü olmadan sürekli olarak eğitim görür ve mühendis eğitimini sonlandırana kadar devam eder.
Monte Carlo Karşı Zaman Farkı
Bir peşiştimli öğrenme ajanını eğitmek veya öğretmek için iki temel yol vardır. Monte Carlo yaklaşımında, ödüller yalnızca eğitim bölümünün sonunda ajana verilir. Başka bir deyişle, yalnızca sonlandırma koşulu karşılandığında model, ne kadar iyi performans gösterdiğini öğrenir. Ardından bu bilgiyi güncelleyebilir ve bir sonraki eğitim turunda yeni bilgiye göre tepki verebilir.
Zaman farkı yöntemi, Monte Carlo yönteminden farklı olarak, değer tahmini veya puan tahmini, eğitim bölümünün sırasında güncellenir. Model bir sonraki zaman adımına ilerlediğinde, değerler güncellenir.
Keşif Karşı Kullanım
Bir peşiştimli öğrenme ajanını eğitmek, iki farklı ölçütü dengelemekle ilgili bir denge eylemidir: keşif ve kullanım.
Keşif, çevreyi daha fazla bilgi toplamak için gerçekleştirilen eylemdir, जबकi kullanım, zaten bilinen bilgileri kullanarak ödül puanları kazanmaktır. Eğer bir ajan yalnızca keşif yapar ve asla kullanım yapmazsa, arzulanan eylemler asla gerçekleştirilmez. Öte yandan, eğer bir ajan yalnızca kullanım yapar ve asla keşif yapmazsa, ajan yalnızca bir eylem gerçekleştirmeyi öğrenir ve diğer olası stratejileri keşfedemez. Bu nedenle, bir peşiştimli öğrenme ajanı oluştururken keşif ve kullanımı dengelemek çok önemlidir.
Peşıştımlı Öğrenmenin Kullanım Alanları
Peşıştımlı öğrenme, çeşitli rollerde kullanılabilecek bir teknolojidir ve görevlerin otomasyonu gerektiği uygulamalar için en uygunudur.
Endüstriyel robotların görevlerini otomasyonu, peşiştimli öğrenmenin faydalı olabileceği bir alandır. Peşıştımlı öğrenme, ayrıca metin madenciliği gibi sorunlar için de kullanılabilir, bu da uzun metinleri özetleyebilecek modeller oluşturulmasını sağlar. Araştırmacılar, peşiştimli öğrenmeyi sağlık alanında da deniyorlar, peşiştimli ajanlar tedavi politikalarının optimizasyonu gibi görevleri gerçekleştiriyor. Peşıştımlı öğrenme, ayrıca öğrencilere eğitim materyallerini özelleştirmek için de kullanılabilir.
Peşıştımlı Öğrenmenin Özeti
Peşıştımlı öğrenme, AI ajanları oluşturmak için güçlü bir yöntemdir ve etkileyici ve bazen şaşırtıcı sonuçlar elde edilebilir. Bir ajanı peşiştimli öğrenme ile eğitmek karmaşık ve zor olabilir, çünkü birçok eğitim iterasyonu ve keşif/kullanım ikileminin nazik bir dengesi gerektirir. Ancak, başarılı olursa, peşiştimli öğrenme ile oluşturulan bir ajan, çeşitli ortamlarda karmaşık görevleri gerçekleştirebilir.








