Yapay Zekâ 101
Karar Ağacı Nedir?
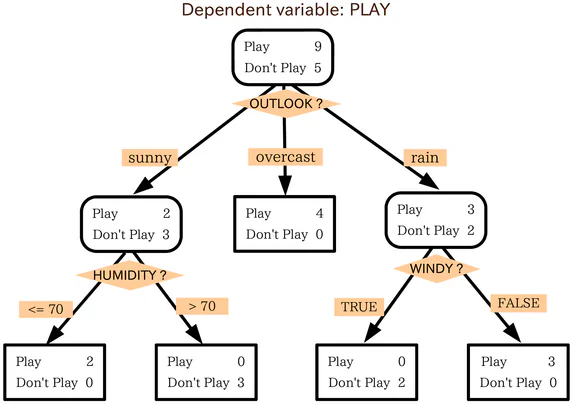
Karar Ağacı Nedir?
Bir karar ağacı hem regresyon hem de sınıflandırma görevleri için kullanılan yararlı bir makine öğrenimi algoritmasıdır. “Karar ağacı” ismi, algoritmanın verisetini küçük ve küçük parçalara ayırma işleminin, verilerin tekil örnekler halinde bölünmesi ve ardından sınıflandırılması gerçeğinden gelir. Algoritmanın sonuçlarını görselleştirebilirseniz, kategorilerin bölünme şekli bir ağaca ve birçok yaprağa benzeyecektir.
Bu, bir karar ağacının hızlı bir tanımı, ancak karar ağaçlarının nasıl çalıştığına dair daha derin bir bakış alalım. Karar ağaçlarının nasıl çalıştığını ve kullanım örneklerini anlamak, makine öğrenimi projelerinizde bunları ne zaman kullanacağınızı bilmeye yardımcı olacaktır.
Karar Ağacının Biçimi
Bir karar ağacı bir akış şemasına benzer. Bir akış şemasını kullanmak için şemanın başlangıç noktasında veya kökünde başlarsınız ve ardından başlangıç düğümünün filtreleme kriterlerine göre cevap verdiğiniz şekilde, bir sonraki olası düğümlerden birine geçersiniz. Bu işlem, bir son bulana kadar tekrarlanır.
Karar ağaçları esasen aynı şekilde çalışır, ağaçtaki her iç düğme bazı türde test veya filtreleme kriteridir. Dıştaki düğümler, ağaçın son noktaları, ilgili veri noktası için etiketleridir ve “yapraklar” olarak adlandırılırlar. İç düğümlerden bir sonraki düğüme giden dallar, özellikler veya özelliklerin birleşimleridir. Veri noktalarını sınıflandırmak için kullanılan kurallar, kökten yapraklara kadar uzanan yollardır.

Karar Ağaçları için Algoritmalar
Karar ağaçları, verisetini farklı kriterlere göre bireysel veri noktalarına ayırma yaklaşımına dayanan bir algoritmik yaklaşım kullanır. Bu bölünmeler, verisetinin farklı değişkenleri veya özellikleriyle yapılır. Örneğin, girdilerdeki özelliklere dayanarak bir köpeğin veya kedinin tanımlanıp tanımlanmadığını belirlemek istiyorsanız, verilerin bölündüğü değişkenler “pençeler” ve “havlamalar” gibi şeyler olabilir.
Peki, verileri dallara ve yapraklara ayırmak için hangi algoritmalar kullanılır? Bir ağacı bölmek için çeşitli yöntemler kullanılabilir, ancak bölme için en yaygın yöntem muhtemelen “özyinelemeli ikili bölme” olarak adlandırılan bir tekniğidir. Bu bölme yöntemini uygularken, işlem kökten başlar ve verisetindeki özelliklerin sayısı, mümkün olan bölme sayısını temsil eder. Her olası bölmenin ne kadar doğruluk kaybına neden olacağını belirlemek için bir fonksiyon kullanılır ve bölme, doğruluk kaybını en aza indiren kriterlere göre yapılır. Bu işlem özyinelemeli olarak gerçekleştirilir ve alt gruplar aynı genel strateji kullanılarak oluşturulur.
Bölmenin maliyetini belirlemek için bir maliyet fonksiyonu kullanılır. Regresyon görevleri ve sınıflandırma görevleri için farklı bir maliyet fonksiyonu kullanılır. Her iki maliyet fonksiyonunun da amacı, en benzer yanıt değerlerine sahip dalları veya en homojen dalları belirlemektir. Belirli bir sınıfa ait test verilerinin belirli yollardan geçmesini istiyorsunuz ve bu mantıklı geliyor.
Özyinelemeli ikili bölme için regresyon maliyet fonksiyonu açısından, maliyeti hesaplamak için kullanılan algoritma şudur:
sum(y – prediction)^2
Bir veri noktaları grubu için tahmini, o gruba ait eğitim verilerinin yanıtlarının ortalamasıdır. Tüm veri noktaları, tüm olası bölme işlemlerinin maliyetini belirlemek için maliyet fonksiyonundan geçirilir ve en düşük maliyetli bölme seçilir.
Sınıflandırma maliyet fonksiyonu ile ilgili olarak, fonksiyon şudur:
G = sum(pk * (1 – pk))
Bu, Gini puanıdır ve bir bölmenin etkinliğini, bölme sonucu oluşan gruplardaki farklı sınıflardan örneklerin sayısı temelinde ölçen bir ölçüttür. Başka bir deyişle, grupların bölme之后 ne kadar karışık olduğunu ölçer. Optimum bir bölme, bölme sonucu oluşan tüm grupların yalnızca bir sınıftan girdiler içermesi durumudur. Optimum bir bölme yaratıldığında, “pk” değeri 0 veya 1 olacaktır ve G 0’a eşit olacaktır. İkili sınıflandırma durumunda en kötü durumlu bölmenin, sınıfların bölünmede %50-%50 temsil edildiği durum olduğunu tahmin edebilirsiniz. Bu durumda, “pk” değeri 0,5 olacaktır ve G de 0,5 olacaktır.
Bölme işlemi, tüm veri noktalarının yapraklara dönüştürülüp sınıflandırıldığında son bulur. Ancak, ağacın büyümesini erken durdurmak isteyebilirsiniz. Büyük ve karmaşık ağaçlar aşırı uyuma eğilimlidir, ancak bunu önlemek için çeşitli yöntemler kullanılabilir. Aşırı uyuma karşı koymak için bir yöntem, bir yaprağı oluşturmak için kullanılacak minimum veri noktaları sayısını belirtmektir. Aşırı uyuma karşı koymak için bir başka yöntem, ağacı belirli bir maksimum derinliğe kısıtlamaktır, bu da kökten bir yaprağa kadar uzanan bir yolun ne kadar uzun olabileceğini kontrol eder.
Karar ağaçlarının oluşturulmasındaki bir başka işlem budamadır. Budama, modelin öngörme gücünü artırmak ve ağaçların karmaşıklığını azaltmak için, model için az önemli olan veya öngörme gücüne sahip olmayan özellikleri içeren dalları çıkarmaya yardımcı olabilir. Bu şekilde, ağaç daha az karmaşık hale gelir ve aşırı uyuma karşı daha az eğilimlidir.
Budama işlemini gerçekleştirirken, işlem ağaçların tepesinden veya dibinden başlayabilir. Ancak, en kolay budama yöntemi, yapraklardan başlamak ve her yaprak içindeki en yaygın sınıfı içeren düğümü düşürmeye çalışmaktır. Modelin doğruluğu, bu işlemin yapıldığında bozulmazsa, değişiklik korunur. Budama için kullanılan diğer teknikler vardır, ancak yukarıda açıklandığı gibi – hata azaltma budaması – muhtemelen en yaygın decision tree budama yöntemidir.
Karar Ağaçlarını Kullanma Konuları
Karar ağaçları sıkça kullanılır quando sınıflandırma yapılması gerekir ancak hesaplama zamanı önemli bir kısıttır. Karar ağaçları, seçilen veri setlerindeki hangi özelliklerin en güçlü öngörme gücüne sahip olduğunu netleştirebilir. Ayrıca, birçok makine öğrenimi algoritmasında kullanılan sınıflandırma kurallarının yorumlanması zor olabilirken, karar ağaçları yorumlanabilir kurallar üretebilir. Karar ağaçları, hem kategorik hem de sürekli değişkenleri kullanabilir, bu da, yalnızca bir değişken türünü işleyebilen algoritmalarla karşılaştırıldığında daha az ön işleme gerektirir.
Karar ağaçları, sürekli özniteliklerin değerlerini belirlemede iyi performans göstermez. Karar ağaçlarının bir başka sınırlaması, sınıflandırma yapılırken, eğitim örnekleri az ve sınıflar çok olduğunda, karar ağacının yanlış olmasıdır.








