Yapay Zekâ
MoE Devrimi: Gelişmiş Routing ve Uzmanlaşma Nasıl LLM’leri Dönüştürüyor
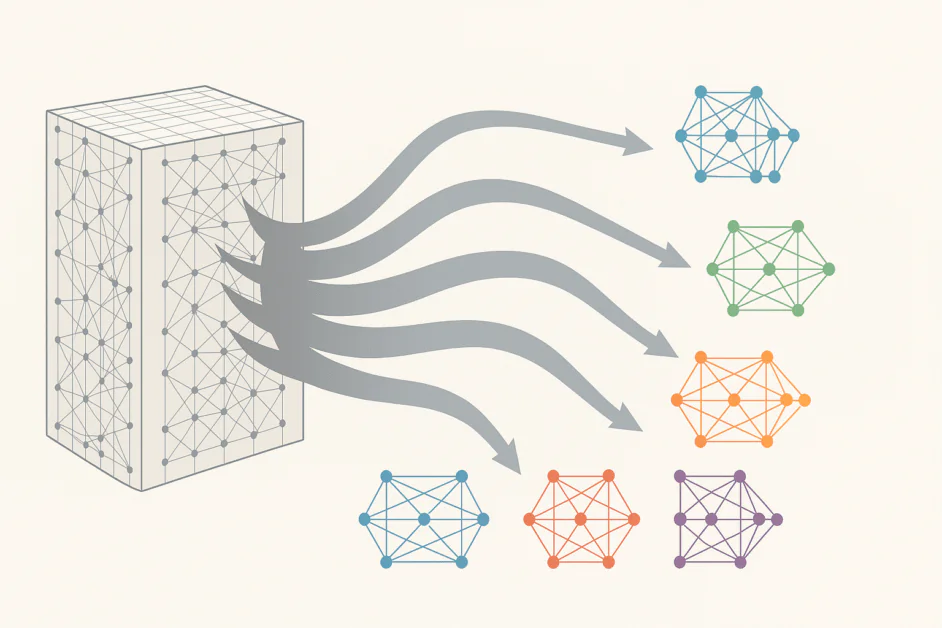
Sadece birkaç yıl içinde, büyük dil modelleri (LLM’ler) milyonlardan yüz milyarlarca parametreye genişledi ve büyük AI sistemlerini mühendislik ve ölçeklendirme yeteneğimizdeki muhteşem ilerlemeyi gösterdi. Bu devasa sistemler, akıcı metin yazma, kod oluşturma, karmaşık problemler üzerinde akıl yürütme ve insan benzeri diyalog gibi şaşırtıcı yetenekler sunuyor. Ancak bu hızlı ölçekleme önemli bir maliyetle geliyor. Bu devasa modelleri eğitme ve çalıştırma, olağanüstü miktarda hesaplama gücü, enerji ve sermaye tüketiyor. Bir zamanlar ilerlemeyi teşvik eden “daha büyük daha iyi” stratejisi sınırlarını göstermeye başladı. Büyüyen kısıtlamalara yanıt olarak, Mixture of Experts (MoE) olarak bilinen bir AI mimarisi, büyük dil modellerini ölçeklendirme için daha akıllı ve daha verimli bir yol sunmak için ilerleme kaydediyor. Bir massive, her zaman aktif ağa bağımlı olmak yerine, MoE modeli, her biri belirli veri veya görev türleri ile ilgilenmek üzere eğitilmiş uzman alt ağların bir koleksiyonuna ayırır. Akıllı routing yoluyla, model yalnızca her girişin en ilgili uzmanlarını etkinleştirir, hesaplama yükünü azaltırken performansı korur veya hatta geliştirir. Bu, ölçeklenebilirliği verimlilikle birleştirebilme yetisi, MoE’yi AI’deki en belirgin ortaya çıkan paradigmalardan biri haline getiriyor. Bu makale, gelişmiş routing ve uzmanlaşmanın bu dönüşümü nasıl sürdürdüğünü ve bunun akıllı sistemlerin geleceği için ne anlama geldiğini keşfediyor.
Temel Mimarının Anlaşılması
Mixture of Experts (MoE) fikri yeni değil. 1990’lardaki toplu öğrenme yöntemlerine kadar uzanıyor. Değişen şey, bunu çalışır hale getiren teknoloji. Sadece yakın yıllarda donanım ve routing algoritmalarındaki ilerlemeler, bu kavramı modern Transformer tabanlı dil modellerine getirmeyi pratik hale getirdi.
Temelinde, MoE büyük bir sinir ağını, her biri belirli bir veri veya görev türünü işlemek üzere eğitilmiş daha küçük, uzman alt ağların bir koleksiyonu olarak yeniden tanımlar. Her girişin tüm parametrelerini etkinleştirmek yerine, MoE bir routing mekanizması tanır, hangi uzmanların belirli bir token veya dizi için en ilgili olduğunu belirler. Sonuç, yalnızca bir kesir parametrelerini herhangi bir zamanda kullanan bir modeldir, bu da hesaplama talebini dramatik olarak azaltırken performansı korur veya hatta geliştirir.
Pratikte, bu mimari değişikliği, araştırmacıların trilyonlarca parametreye kadar ölçeklenmesini, hesap kaynaklarında orantılı bir artış olmadan sağlar. Geleneksel yoğun besleme ileri katmanlarını daha akıllı ve dinamik bir sistemle değiştirir. Her MoE katmanı, genellikle kendileri daha küçük besleme ileri ağları olan birden fazla uzmandan oluşur ve hangi uzmanların her bir girişi işleyeceğini belirleyen bir router veya kapı ağları içerir. Router, ilgili soruları her uzmana gönderen bir proje müdürü gibi davranır. Sistem, hangi uzmanların farklı sorun türleri için en iyi performansı gösterdiğini öğrenir ve eğitim boyunca routing stratejisini iyileştirir.
Bu tasarım, ölçek ve verimlilik arasında çarpıcı bir kombinasyon sunar. Örneğin, en gelişmiş MoE modellerinden biri olan DeepSeek V3, 685 milyar parametreyi kullanır ancak yalnızca küçük bir kısmını çıkarım sırasında etkinleştirir. Büyük bir modelin performansı sunar ancak önemli ölçüde daha düşük hesaplama ve enerji gereksinimleriyle.
Routing Mekanizmalarının Evrimi
Router, MoE’nin kalbidir ve hangi uzmanların her girişi işleyeceğini belirler. İlk modeller, basit stratejiler kullandı, öğrenilen ağırlıklara dayanarak en iyi iki veya üç uzmanı seçti. Modern sistemler çok daha sofistikedir.
Bugünün dinamik routing mekanizmaları, girdi karmaşıklığına bağlı olarak etkinleştirilen uzmanların sayısını ayarlar. Basit bir soru yalnızca bir uzmana ihtiyaç duyabilirken, zorlu akıl yürütme görevleri birden fazla uzmanı etkinleştirebilir. DeepSeek-V2, dağıtılmış donanım genelinde iletişim maliyetlerini kontrol etmek için cihaz sınırlı routing uyguladı. DeepSeek-V3, performans bozulmasına olmadan daha zengin uzman uzmanlaşmasına izin veren yardımcı kayıp stratejilerini öncü olarak uyguladı.
Gelişmiş router’lar artık akıllı kaynak yöneticileri olarak hareket eder, girdi özellikleri, ağ derinliği veya gerçek zamanlı performans geri bildirimi temelinde seçim stratejilerini ayarlar. Bazı araştırmacılar, uzun vadeli görev performansı için takviye öğrenimini optimize etmeyi keşfediyor. Teknikler gibi yumuşak kapı, uzman seçimini daha sorunsuz hale getirirken, olasılıksal görev dağıtımı, atamaları optimize etmek için istatistiksel yöntemler kullanır.
Uzmanlaşma Performansı Sürdürür
MoE’nin temel vaadi, derin uzmanlaşmanın geniş genellemeyi aşacağıdır. Her uzman, her şeyde ortalama olmak yerine belirli alanlarda uzmanlaşmaya odaklanır. Eğitim sırasında, routing mekanizmaları belirli girdi türlerini tutarlı olarak belirli uzmanlara yönlendirir, güçlü bir geri bildirim döngüsü oluşturur. Bazı uzmanlar kodlama, diğerleri tıbbi terminoloji ve diğerleri yaratıcı yazma konusunda uzmanlaşır.
Ancak bu hedefe ulaşmak, zorluklar sunar. Geleneksel yük dengeleme yaklaşımları, tüm uzmanların eşit kullanımını zorlayarak ironik bir şekilde uzmanlaşmayı engelleyebilir. Ancak alan hızla ilerlemektedir. Çalışmalar, ince MoE modellerinin açık uzmanlaşmaya sahip olduğunu, farklı uzmanların kendi alanlarında hakim olduğunu gösteriyor. Çalışmalar, routing mekanizmalarının bu mimari iş bölümünü şekillendirmede aktif bir rol oynadığını onaylıyor.
Alan ana uzmanları kullanan stratejiler, önemli performans iyileştirmeleri gösterdi. Örneğin, araştırmacılar, AIME2024 benchmark’te %3,33’lük bir doğruluk artışı bildirdi. Uzmanlaşma çalıştığında, sonuçlar şaşırtıcıdır. DeepSeek V3, çoğu doğal dil benchmark’inde GPT-4o’yu aşar ve tüm kodlama ve matematiksel akıl yürütme görevlerinde liderlik eder, açık kaynaklı bir model için etkileyici bir kilometre taşı.
Model Kapasitelerine Pratik Etkisi
MoE devrimi, temel model kapasitelerinde somut iyileştirmeler sağladı. Modeller artık daha uzun bağlamları daha verimli bir şekilde işleyebiliyor; hem DeepSeek V3 hem de GPT-4o, MoE mimarisinin özellikle teknik alanlarda performansı optimize ettiği 128K tokeni tek bir girişte işleyebilir. Bu, tüm kodu analiz etme veya uzun yasal belgeleri işleme gibi uygulamalar için kritiktir.
Maliyet verimliliği kazanımları daha da dramatiktir. Analiz, DeepSeek-V3’ün GPT-4o’ya göre token başına yaklaşık 29,8 kat daha ucuz olduğunu öne sürüyor. Bu fiyat farkı, gelişmiş AI’yi daha geniş bir kullanıcı ve uygulama yelpazesine erişilebilir hale getirir. AI’nin demokratikleşmesini önemli ölçüde hızlandırır.
Ayrıca, mimari daha sürdürülebilir bir dağıtımı sağlar. Bir MoE modelini eğitmek hala önemli kaynaklar gerektirir, ancak dramatically daha düşük çıkarım maliyeti, AI şirketleri ve müşterileri için daha verimli ve ekonomik olarak viable bir model için yolu açar.
Challenges and the Path Forward
MoE’nin önemli avantajlarına rağmen, zorluklar yok değil. Eğitim kararsız olabilir, bazen uzmanların amaçlandığı gibi uzmanlaşmadığı durumlar ortaya çıkabilir. İlk modeller, bir uzmanın diğerlerini domine ettiği “routing collapse” ile mücadele etti. Tüm uzmanların yeterli eğitim verisine sahip olmasını sağlamak, ancak bir alt kümesinin aktif olması gerekir, dikkatli bir denge gerektirir.
En önemli engel, iletişim yüküdür. Dağıtılmış GPU kurulumlarında, iletişim maliyetleri işleme zamanının %77’sini tüketebilir. Çok fazla uzman, sık sık birlikte etkinleştirilir ve bu da donanım hızlandırıcıları arasında tekrar edilen veri transferlerine neden olur. Bu, AI donanım tasarımının temel bir yeniden değerlendirmesine yol açıyor.
Hafıza talepleri başka bir önemli zorluk oluşturur. MoE, çıkarım sırasında hesap maliyetlerini azaltırken, tüm uzmanların bellekte yüklenmesi gerekir, bu da kenar cihazları veya kaynak sınırlı ortamları zorlar. Yorumlanabilirlik başka bir ana zorluktur, çünkü bir uzmanın belirli bir çıktıya katkıda bulunup bulunmadığını belirlemek, mimariye başka bir karmaşıklık katmanı ekler. Araştırmacılar, uzman etkinleştirmelerini izlemek ve karar alma yolunu görselleştirmek için yöntemler geliştiriyor, MoE sistemlerini daha şeffaf ve denetimi daha kolay hale getirmeyi amaçlıyor.
Sonuç
Mixture of Experts paradigması, yalnızca yeni bir mimari değil, AI modelleri oluşturma felsefesi açısından yeni bir yaklaşım sunuyor. Akıllı routing’i alan düzeyinde uzmanlaşmayla birleştiren MoE, bir zamanlar çelişkili görünen şeyi başarmayı başarıyor: daha büyük ölçekleme ile daha az hesaplama. Kararsızlık, iletişim ve yorumlanabilirlik konularındaki zorluklara rağmen, verimlilik, adaptasyon ve doğruluk dengesi, AI sistemlerinin geleceğine işaret ediyor; yalnızca daha büyük değil, aynı zamanda daha akıllı.












