Yapay Zeka
Çok Belirteçli Tahminle Büyük Dil Modellerini Güçlendirme
By
Aayush Mittal Mittal
Büyük dil modelleri GPT, LLaMA ve diğerleri gibi (LLM'ler), insan benzeri metinleri anlama ve üretme konusundaki olağanüstü yetenekleriyle dünyayı kasıp kavurdu. Bununla birlikte, etkileyici yeteneklerine rağmen, "sonraki belirteç tahmini" olarak bilinen bu modelleri eğitmenin standart yönteminin bazı doğal sınırlamaları vardır.
Sonraki jeton tahmininde model, önceki kelimelere göre bir sonraki kelimeyi tahmin edecek şekilde eğitilir. Bu yaklaşımın başarılı olduğu kanıtlanmış olsa da, uzun vadeli bağımlılıklarla ve karmaşık akıl yürütme görevleriyle mücadele eden modellerin ortaya çıkmasına yol açabilir. Ayrıca, öğretmenin zorladığı eğitim rejimi ile çıkarım sırasındaki otoregresif üretim süreci arasındaki uyumsuzluk, optimumun altında performansla sonuçlanabilir.
Yakın zamanda yayınlanan bir araştırma makalesi Gloeckle ve ark. (2024) Meta AI'dan "" adlı yeni bir eğitim paradigması tanıtılıyor.çoklu token tahminiBu sınırlamaları ele almayı ve büyük dil modellerini güçlendirmeyi amaçlayan bir blog yazısı. Bu blog yazısında, bu çığır açan araştırmanın temel kavramlarını, teknik ayrıntılarını ve olası etkilerini derinlemesine inceleyeceğiz.
Tek Token Tahmini: Geleneksel Yaklaşım
Çoklu belirteç tahmininin ayrıntılarına dalmadan önce, geleneksel yaklaşımın anlaşılması önemlidir. büyük dil modelinin beygir gücü Yıllarca eğitim – tek jeton tahmini, aynı zamanda sonraki jeton tahmini olarak da bilinir.
Sonraki Belirteç Tahmin Paradigması
Sonraki belirteç tahmin paradigmasında, dil modelleri, önceki bağlam göz önüne alındığında bir sonraki kelimeyi tahmin etmek için eğitilir. Daha resmi olarak model, önceki x1, x1, …, xt jetonları göz önüne alındığında, bir sonraki xt+2 jetonunun olasılığını maksimuma çıkarmakla görevlendirilir. Bu genellikle çapraz entropi kaybını en aza indirerek yapılır:
L = -Σt log P(xt+1 | x1, x2, …, xt)
Bu basit ama güçlü eğitim hedefi, GPT (Radford ve diğerleri, 2018), BERT (Devlin ve diğerleri, 2019) ve bunların çeşitleri gibi birçok başarılı büyük dil modelinin temeli olmuştur.
Öğretmen Zorlaması ve Otoregresif Üretim
Sonraki belirteç tahmini, "adlı bir eğitim tekniğine dayanır"öğretmen zorlamaeğitim sırasında gelecekteki her jeton için temel gerçeğin modele sağlandığı yer. Bu, modelin doğru bağlamdan ve hedef dizilerden öğrenmesine olanak tanıyarak daha istikrarlı ve verimli eğitimi kolaylaştırır.
Bununla birlikte, çıkarım veya üretim sırasında model, önceden oluşturulmuş jetonlara dayalı olarak her seferinde bir jetonu tahmin ederek otoregresif bir şekilde çalışır. Eğitim rejimi (öğretmen zorlaması) ve çıkarım rejimi (otoregresif üretim) arasındaki bu uyumsuzluk, özellikle daha uzun diziler veya karmaşık muhakeme görevleri için potansiyel tutarsızlıklara ve optimal olmayan performansa yol açabilir.
Sonraki Jeton Tahmininin Sınırlamaları
Bir sonraki token tahmini oldukça başarılı olsa da, bazı doğal sınırlamaları da var:
- Kısa Vadeli Odaklanma: Model, yalnızca bir sonraki belirteci tahmin ederek, uzun vadeli bağımlılıkları ve metnin genel yapısını ve tutarlılığını yakalamada zorluk yaşayabilir, bu da potansiyel olarak tutarsızlıklara veya tutarsız nesillere yol açabilir.
- Yerel Desen Mandallama: Sonraki belirteç tahmin modelleri, eğitim verilerindeki yerel kalıplara uyum sağlayabilir, bu da dağıtım dışı senaryolara veya daha soyut muhakeme gerektiren görevlere genelleme yapmayı zorlaştırır.
- Muhakeme Yetenekleri: Çok adımlı akıl yürütme, algoritmik düşünme veya karmaşık mantıksal işlemler içeren görevlerde, sonraki simge tahmini, bu tür yetenekleri etkili bir şekilde desteklemek için yeterli tümevarımsal önyargıları veya temsilleri sağlayamayabilir.
- Örnek Verimsizliği: Sonraki belirteç tahmininin yerel doğası nedeniyle modeller, gerekli bilgi ve muhakeme becerilerini edinmek için daha büyük eğitim veri kümeleri gerektirebilir ve bu da potansiyel örnek verimsizliklerine yol açabilir.
Bu sınırlamalar, araştırmacıları, bu eksikliklerin bazılarını gidermeyi ve büyük dil modelleri için yeni yeteneklerin kilidini açmayı amaçlayan çoklu belirteçli tahmin gibi alternatif eğitim paradigmalarını keşfetmeye motive etti.
Geleneksel sonraki jeton tahmin yaklaşımını yeni çoklu jeton tahmin tekniğiyle karşılaştırarak, okuyucular ikincisinin motivasyonunu ve potansiyel faydalarını daha iyi anlayabilir ve bu çığır açıcı araştırmanın daha derin bir şekilde araştırılmasına zemin hazırlayabilir.
Çoklu Token Tahmini Nedir?
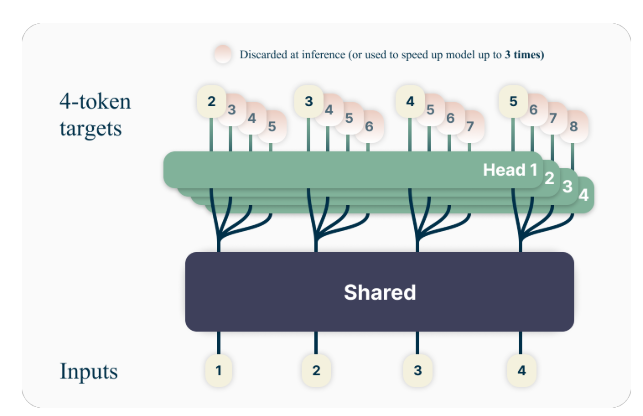
Çoklu belirteç tahmininin ardındaki temel fikir, dil modellerini yalnızca bir sonraki belirteç yerine aynı anda birden fazla gelecekteki belirteci tahmin edecek şekilde eğitmektir. Spesifik olarak, eğitim sırasında modele, paylaşılan bir model gövdesinin üzerinde çalışan n bağımsız çıkış kafasını kullanarak eğitim kümesindeki her konumdaki sonraki n jetonu tahmin etme görevi verilir.
Örneğin, 4 jetonlu bir tahmin kurulumuyla model, önceki bağlam göz önüne alındığında sonraki 4 jetonu aynı anda tahmin edecek şekilde eğitilecektir. Bu yaklaşım, modelin daha uzun vadeli bağımlılıkları yakalamasını ve metnin genel yapısı ve tutarlılığının daha iyi anlaşılmasını teşvik eder.
Bir Oyuncak Örneği
Çoklu belirteç tahmini kavramını daha iyi anlamak için basit bir örneği ele alalım. Diyelim ki şu cümle var:
"Hızlı kahverengi tilki tembel köpeğin üzerinden atlar."
Standart sonraki belirteç tahmin yaklaşımında model, önceki bağlam göz önüne alındığında sonraki kelimeyi tahmin edecek şekilde eğitilecektir. Örneğin, "Hızlı kahverengi tilki üstünden atlıyor" bağlamı göz önüne alındığında, modele bir sonraki "tembel" kelimesini tahmin etme görevi verilecek.
Ancak çoklu belirteçli tahminle model, aynı anda birden fazla gelecekteki kelimeyi tahmin edecek şekilde eğitilecektir. Örneğin, n=4 olarak ayarlarsak model, sonraki 4 kelimeyi aynı anda tahmin edecek şekilde eğitilir. Aynı bağlam göz önüne alındığında, "Hızlı kahverengi tilki üstünden atlar" modele "tembel köpek" dizisini tahmin etme görevi verilecekti. (Cümlenin sonunu belirtmek için “köpek”ten sonraki boşluğa dikkat edin).
Modelin gelecekteki birden fazla belirteci aynı anda tahmin edecek şekilde eğitilmesiyle, uzun vadeli bağımlılıkların yakalanması ve metnin genel yapısı ve tutarlılığının daha iyi anlaşılması teşvik edilir.
Teknik detaylar
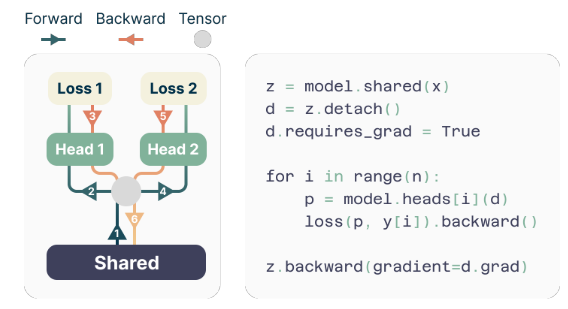
Yazarlar çoklu belirteç tahminini uygulamak için basit ama etkili bir mimari önermektedir. Model, giriş bağlamının gizli bir temsilini üreten paylaşılan bir transformatör hattından ve ardından gelen bilgilerden oluşur. n ilgili gelecekteki jetonları tahmin eden bağımsız transformatör katmanları (çıkış kafaları).
Eğitim sırasında ileri ve geri geçişler, GPU bellek alanını en aza indirmek için dikkatli bir şekilde düzenlenir. Paylaşılan hat, gizli gösterimi hesaplar ve ardından her bir çıkış kafası, hat seviyesindeki eğimleri biriktirerek ileri ve geri geçişini sırayla gerçekleştirir. Bu yaklaşım, tüm logit vektörlerinin ve bunların gradyanlarının aynı anda gerçekleştirilmesini önleyerek en yüksek GPU bellek kullanımını azaltır. O(nV + d) için Ö(V + d), Burada V olduğunu kelime boyutu ve d olduğunu boyut gizli temsil.
Bellek Verimli Uygulama
Çok belirteçli tahmincilerin eğitimindeki zorluklardan biri GPU bellek kullanımının azaltılmasıdır. Beri kelime boyutu (V) genellikle olduğundan çok daha büyüktür boyut gizli temsilin (D)logit vektörleri GPU bellek kullanımında darboğaz haline gelir.
Bu zorluğun üstesinden gelmek için yazarlar, ileri ve geri operasyonların sırasını dikkatli bir şekilde uyarlayan, hafıza açısından verimli bir uygulama önermektedir. Uygulama, tüm logitleri ve bunların gradyanlarını aynı anda gerçekleştirmek yerine, her bir bağımsız çıkış kafası için ileri ve geri geçişleri sırayla hesaplayarak, gradyanları gövde seviyesinde biriktirir.
Bu yaklaşım, tüm logit vektörlerinin ve bunların gradyanlarının aynı anda belleğe kaydedilmesini önleyerek en yüksek GPU bellek kullanımını azaltır. O(nV + d) için Ö(V + d), Burada n tahmin edilen gelecekteki tokenların sayısıdır.
Çoklu Token Tahmininin Avantajları
Araştırma makalesi, büyük dil modellerini eğitmek için çoklu belirteç tahmini kullanmanın bazı ilgi çekici avantajlarını sunuyor:
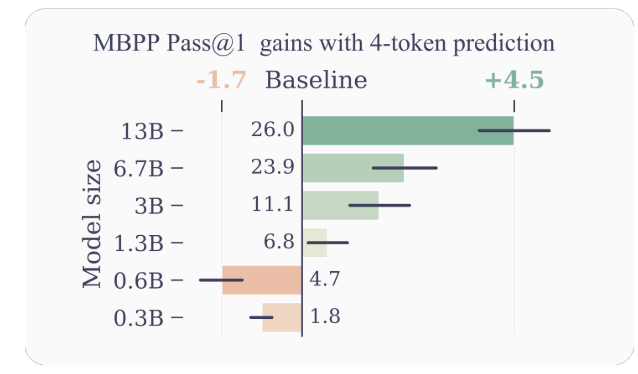
- Geliştirilmiş Numune Verimliliği: Modelin gelecekteki birden fazla jetonu aynı anda tahmin etmesini teşvik eden çoklu jeton tahmini, modeli daha iyi örnek verimliliğine doğru yönlendirir. Yazarlar, 13B'ye kadar parametreye sahip modellerin ortalama %15 daha fazla sorunu çözmesiyle, kod anlama ve oluşturma görevlerinde performansta önemli gelişmeler olduğunu ortaya koyuyor.
- Daha Hızlı Çıkarım: Çoklu jeton tahminiyle eğitilmiş ek çıkış kafaları, paralel jeton tahminine izin veren spekülatif kod çözmenin bir çeşidi olan kendi kendine spekülatif kod çözme için kullanılabilir. Bu, büyük modeller için bile çok çeşitli parti boyutlarında 3 kata kadar daha hızlı çıkarım süreleri sağlar.
- Uzun Menzilli Bağımlılıkları Teşvik Etmek: Çoklu belirteçli tahmin, modelin verilerdeki daha uzun vadeli bağımlılıkları ve kalıpları yakalamasını teşvik eder; bu, özellikle daha geniş bağlamlarda anlayış ve akıl yürütme gerektiren görevler için faydalıdır.
- Algoritmik Akıl Yürütme: Yazarlar, özellikle daha küçük model boyutları için, tümevarım kafaları ve algoritmik akıl yürütme yeteneklerinin geliştirilmesinde çok jetonlu tahmin modellerinin üstünlüğünü gösteren sentetik görevler üzerinde deneyler sunmaktadır.
- Tutarlılık ve Tutarlılık: Modeli gelecekteki birden fazla jetonu aynı anda tahmin edecek şekilde eğiterek, çoklu jeton tahmini tutarlı ve tutarlı temsillerin geliştirilmesini teşvik eder. Bu özellikle hikaye anlatma, yaratıcı yazma veya kullanım kılavuzları oluşturma gibi daha uzun, daha tutarlı metinler oluşturmayı gerektiren görevler için faydalıdır.
- Geliştirilmiş GenellemeYazarların sentetik görevler üzerindeki deneyleri, çoklu belirteç tahmin modellerinin, özellikle dağıtım dışı ortamlarda daha iyi genelleme yetenekleri sergilediğini göstermektedir. Bu, potansiyel olarak modelin daha uzun vadeli örüntüleri ve bağımlılıkları yakalama yeteneğinden kaynaklanmaktadır ve bu da daha önce görülmemiş senaryolara daha etkili bir şekilde genelleme yapmasına yardımcı olabilir.

Örnekler ve Sezgiler
Çoklu belirteç tahmininin neden bu kadar iyi çalıştığına dair daha fazla sezgi sağlamak için birkaç örneği ele alalım:
- Kod Oluşturma: Kod oluşturma bağlamında, birden fazla belirteci aynı anda tahmin etmek, modelin daha karmaşık kod yapılarını anlamasına ve oluşturmasına yardımcı olabilir. Örneğin, bir işlev tanımı oluştururken yalnızca bir sonraki belirteci tahmin etmek, modelin tüm işlev imzasını doğru şekilde oluşturması için yeterli bağlamı sağlamayabilir. Bununla birlikte, model aynı anda birden fazla jetonu tahmin ederek işlev adı, parametreler ve dönüş türü arasındaki bağımlılıkları daha iyi yakalayabilir ve bu da daha doğru ve tutarlı kod üretimine yol açar.
- Doğal Dilde Muhakeme: Bir dil modelinin birden çok adım veya bilgi parçası üzerinde akıl yürütme gerektiren bir soruyu yanıtlamakla görevlendirildiği bir senaryoyu düşünün. Model, aynı anda birden fazla belirteci tahmin ederek, akıl yürütme sürecinin farklı bileşenleri arasındaki bağımlılıkları daha iyi yakalayabilir ve bu da daha tutarlı ve doğru yanıtlara yol açabilir.
- Uzun Biçimli Metin Oluşturma: Hikayeler, makaleler veya raporlar gibi uzun biçimli metinler oluştururken, tutarlılığı ve tutarlılığı uzun bir süre boyunca korumak, sonraki belirteç tahminiyle eğitilmiş dil modelleri için zorlayıcı olabilir. Çoklu belirteçli tahmin, modeli metnin genel yapısını ve akışını yakalayan temsiller geliştirmeye teşvik ederek potansiyel olarak daha tutarlı ve tutarlı uzun biçimli nesillere yol açar.
Sınırlamalar ve Gelecek Yönler
Makalede sunulan sonuçlar etkileyici olsa da, daha fazla araştırmayı gerektiren birkaç sınırlama ve açık soru var:
- Optimum Jeton Sayısı: Makale, n'nin farklı değerlerini (tahmin edilecek gelecekteki jetonların sayısı) araştırıyor ve n=4'ün birçok görev için iyi çalıştığını buluyor. Ancak n'nin optimal değeri belirli göreve, veri kümesine ve model boyutuna bağlı olabilir. Optimum n'yi belirlemek için ilkeli yöntemler geliştirmek, performansın daha da iyileştirilmesine yol açabilir.
- Kelime Boyutu ve Tokenizasyon: Yazarlar, çoklu token tahmin modelleri için optimal kelime dağarcığı boyutunun ve tokenizasyon stratejisinin, sonraki token tahmin modellerinde kullanılanlardan farklı olabileceğini belirtmektedir. Bu yönün araştırılması, sıkıştırılmış dizi uzunluğu ile hesaplama verimliliği arasında daha iyi dengelerin kurulmasına yol açabilir.
- Yardımcı Tahmin Kayıpları: Yazarlar, çalışmalarının, standart sonraki belirteç tahmininin ötesinde, büyük dil modelleri için yeni yardımcı tahmin kayıpları geliştirmeye ilgiyi artırabileceğini öne sürüyorlar. Alternatif yardımcı kayıpları ve bunların çoklu token tahminiyle kombinasyonlarını araştırmak heyecan verici bir araştırma yönüdür.
- Teorik Anlayış: Makale, çoklu belirteçli tahminin etkinliğine ilişkin bazı sezgiler ve ampirik kanıtlar sağlarken, bu yaklaşımın neden ve nasıl bu kadar iyi çalıştığına dair daha derin bir teorik anlayış değerli olacaktır.
Sonuç
Gloeckle ve diğerleri tarafından yazılan "Çok Belirteçli Tahmin Yoluyla Daha İyi ve Daha Hızlı Büyük Dil Modelleri" araştırma makalesi. büyük dil modellerinin performansını ve yeteneklerini önemli ölçüde geliştirme potansiyeline sahip yeni bir eğitim paradigması sunuyor. Çoklu jeton tahmini, gelecekteki birden fazla jetonu aynı anda tahmin etmek için modelleri eğiterek, uzun vadeli bağımlılıkların, algoritmik akıl yürütme yeteneklerinin ve daha iyi örnek verimliliğinin geliştirilmesini teşvik eder.
Yazarlar tarafından önerilen teknik uygulama zarif ve hesaplama açısından verimli olup, bu yaklaşımın büyük ölçekli dil modeli eğitimine uygulanmasını mümkün kılmaktadır. Ayrıca, daha hızlı çıkarım için kendi kendine spekülatif kod çözmeyi kullanma yeteneği, önemli bir pratik avantajdır.
Hala açık sorular ve daha fazla araştırılacak alanlar olsa da, bu araştırma, büyük dil modelleri alanında ileriye doğru atılan heyecan verici bir adımı temsil ediyor. Daha yetenekli ve verimli dil modellerine olan talep artmaya devam ettikçe, çoklu belirteçli tahmin, bu güçlü yapay zeka sistemlerinin yeni neslinde önemli bir bileşen haline gelebilir.
Son beş yılımı, Makine Öğrenimi ve Derin Öğrenmenin büyüleyici dünyasına dalarak geçirdim. Tutkum ve uzmanlığım, özellikle AI/ML'ye odaklanarak 50'den fazla farklı yazılım mühendisliği projesine katkıda bulunmamı sağladı. Devam eden merakım, beni daha fazla keşfetmeye hevesli olduğum bir alan olan Doğal Dil İşleme'ye de çekti.

Beğenebilirsin
-


Yapay Zeka ile Videolardan Nesneleri ve İnsanları Silme
-


Yapay Zekanın Rolü Genişledikçe Vibe Kodlama Zarar Görüyor
-


GPU Duvarı Çatlıyor: Transformatör Sonrası Mimarilerde Görülmemiş Devrim
-


Google NotebookLM Derin Araştırma Özelliğini Sunuyor
-


Meta Baş Yapay Zeka Bilim İnsanı Yann LeCun, Girişimden Ayrılmayı Planlıyor
-


Absürt Bilimsel Makaleler Yapay Zeka İncelemecilerinin Gözünden Nasıl Sızdırılır?











