
Cybersäkerhet
Varför motstridiga bildattacker är inget skämt
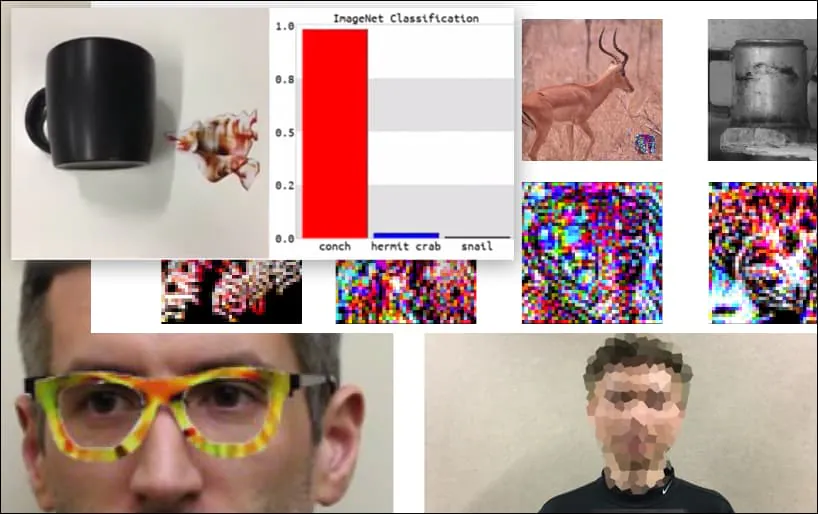
Att attackera bildigenkänningssystem med noggrant utformade motståndsbilder har ansetts vara ett underhållande men trivialt proof-of-concept under de senaste fem åren. Ny forskning från Australien tyder dock på att tillfällig användning av mycket populära bilddatauppsättningar för kommersiella AI-projekt kan skapa ett bestående nytt säkerhetsproblem.
Sedan ett par år tillbaka har en grupp akademiker vid University of Adelaide försökt förklara något riktigt viktigt om framtiden för AI-baserade bildigenkänningssystem.
Det är något som skulle vara svårt (och väldigt dyrt) att fixa just nu, och som skulle bli omedvetet kostsamt att åtgärda när de nuvarande trenderna inom bildigenkänningsforskningen har utvecklats fullt ut till kommersialiserade och industrialiserade implementeringar om 5-10 år.
Innan vi går in på det, låt oss ta en titt på en blomma som klassificeras som president Barack Obama, från en av de sex videor som teamet har publicerat på projektsida:
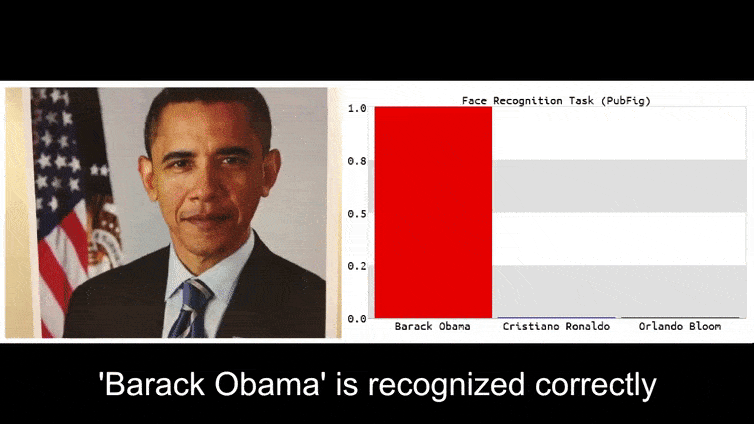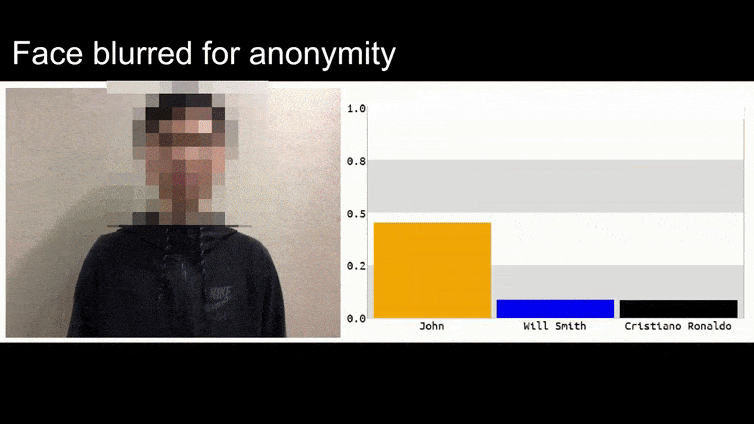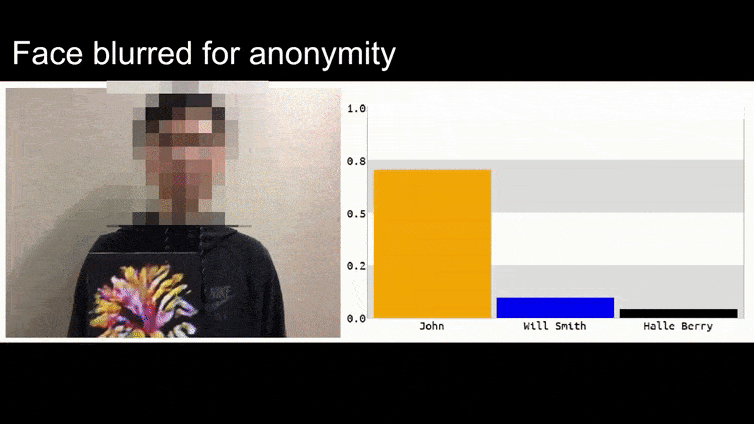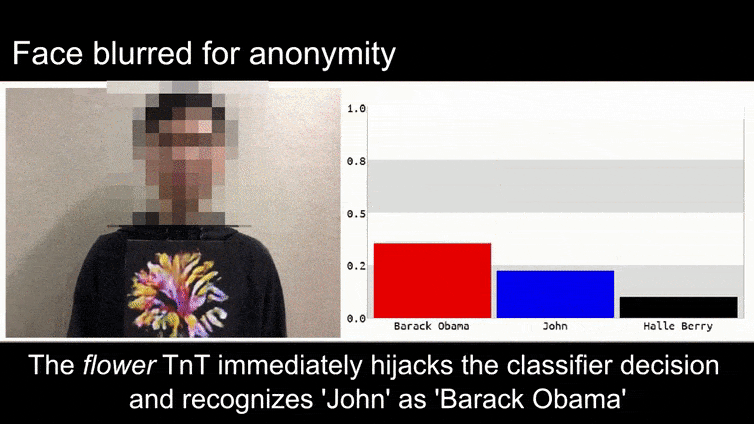
Källa: https://www.youtube.com/watch?v=Klepca1Ny3c
I bilden ovan luras ett ansiktsigenkänningssystem som tydligt vet hur man känner igen Barack Obama till 80 % säkerhet om att en anonymiserad man som håller en tillverkad, tryckt motståndsbild av en blomma också är Barack Obama. Systemet bryr sig inte ens om att det "falska ansiktet" är på personens bröst, istället för på hans axlar.
Även om det är imponerande att forskarna har kunnat åstadkomma denna typ av identitetsfångst genom att generera en sammanhängande bild (en blomma) istället för bara det vanliga slumpmässiga bruset, verkar det som om fåniga bedrifter som denna dyker upp ganska regelbundet i säkerhetsforskning om datorseende . Till exempel de konstigt mönstrade glasögonen som kunde lura ansiktsigenkänning tillbaka i 2016, eller specialgjorda motståndsbilder som försök att skriva om vägmärken.
Om du är intresserad är modellen Convolutional Neural Network (CNN) som attackeras i exemplet ovan VGGFace (VGG-16), utbildad vid Columbia University's PubFig dataset. Andra attackprover utvecklade av forskarna använde olika resurser i olika kombinationer.

Ett tangentbord är omklassat som en snäcka, i en WideResNet50-modell på ImageNet. Forskarna har också säkerställt att modellen inte har någon partiskhet mot koncher. Se hela videon för utökade och ytterligare demonstrationer på https://www.youtube.com/watch?v=dhTTjjrxIcU
Bildigenkänning som en ny attackvektor
De många imponerande attackerna som forskarna skisserar och illustrerar är inte kritik mot enskilda datamängder eller specifika maskininlärningsarkitekturer som använder dem. De kan inte heller lätt försvaras mot genom att byta datauppsättningar eller modeller, omskolningsmodeller eller någon av de andra "enkla" åtgärderna som får ML-utövare att håna sporadiska demonstrationer av denna typ av trick.
Snarare exemplifierar Adelaide-teamets bedrifter ett central svaghet i hela den nuvarande arkitekturen för bildigenkänning AI-utveckling; en svaghet som skulle kunna utsätta många framtida bildigenkänningssystem för enkel manipulation av angripare och att lägga eventuella efterföljande defensiva åtgärder på bakfoten.
Föreställ dig att de senaste bilderna av motståndskraftiga attacker (som blomman ovan) läggs till som "zero-day exploits" till framtidens säkerhetssystem, precis som nuvarande anti-malware- och antivirusramverk uppdaterar sina virusdefinitioner varje dag.
Potentialen för nya motstridiga bildattacker skulle vara outtömlig, eftersom systemets grundarkitektur inte förutsåg nedströmsproblem, som inträffade med internet, den millennium bugg och lutande tornet i Pisa.
På vilket sätt lägger vi då scenen för detta?
Få data för en attack
Motstridiga bilder som "blomma"-exemplet ovan genereras genom att ha tillgång till bilddatauppsättningarna som tränade datormodellerna. Du behöver inte "privilegierad" tillgång till träningsdata (eller modellarkitekturer), eftersom de mest populära datamängderna (och många tränade modeller) är allmänt tillgängliga i en robust och ständigt uppdaterad torrentscen.
Till exempel är den ärevördiga Goliath of Computer Vision dataset, ImageNet tillgänglig för torrent i alla dess många upprepningar, förbigå dess sedvanliga begränsningar, och tillgängliggörande av avgörande sekundära element, som t.ex valideringsuppsättningar.

Källa: https://academictorrents.com
Om du har data kan du (som Adelaide-forskarna observerar) effektivt "reverse-engineer" vilken populär datauppsättning som helst, som t.ex. CityScapes, eller CIFAR.
När det gäller PubFig, datauppsättningen som möjliggjorde "Obama Flower" i det tidigare exemplet, har Columbia University tagit itu med en växande trend i upphovsrättsfrågor kring omfördelning av bilddatauppsättningar genom att instruera forskare hur man reproducera datasetet via kurerade länkar, istället för att göra kompileringen direkt tillgänglig, observera "Det här verkar vara hur andra stora webbaserade databaser verkar utvecklas".
I de flesta fall är det inte nödvändigt: Kaggle uppskattningar att de tio mest populära bilduppsättningarna inom datorseende är: CIFAR-10 och CIFAR-100 (båda direkt nedladdningsbar); CALTECH-101 och 256 (båda tillgängliga och båda för närvarande tillgängliga som torrents); MNIST (officiellt tillgänglig, även på torrents); ImageNet (se ovan); Pascal VOC (tillgänglig, även på torrents); MS COCO (tillgänglig, och på torrents); Sport-1M (tillgänglig); och YouTube-8M (tillgänglig).
Denna tillgänglighet är också representativ för det bredare utbudet av tillgängliga bilddatauppsättningar för datorseende, eftersom otydlighet är döden i en "publicera eller förgås" utvecklingskultur med öppen källkod.
I alla fall bristen på hanterlig nya datamängder, de höga kostnaderna för bilduppsättningsutveckling, beroendet av "gamla favoriter" och tendensen att anpassa helt enkelt äldre datamängder alla förvärrar problemet som beskrivs i det nya Adelaide-dokumentet.
Typisk kritik av kontradiktoriska bildattackmetoder
Den vanligaste och ihållande kritiken från maskininlärningsingenjörer mot effektiviteten av den senaste tekniken för motstridiga bildattacker är att attacken är specifikt för en viss datauppsättning, en viss modell eller båda; att det inte är "generaliserbart" till andra system; och representerar följaktligen bara ett trivialt hot.
Det näst vanligaste klagomålet är att den kontradiktoriska bildattacken är 'vit låda', vilket innebär att du skulle behöva direkt tillgång till träningsmiljön eller data. Detta är verkligen ett osannolikt scenario, i de flesta fall – till exempel om du vill utnyttja träningsprocessen för ansiktsigenkänningssystem av Londons Metropolitan Police, du måste hacka dig in NEC, antingen med en konsol eller en yxa.
Det långsiktiga "DNA" av populära datauppsättningar för datorseende
När det gäller den första kritiken bör vi inte bara tänka på att en handfull datauppsättningar med datorseende dominerar branschen per sektor från år till år (dvs ImageNet för flera typer av objekt, CityScapes för körscener och FFHQ för ansiktsigenkänning); men också att de, som enkla kommenterade bilddata, är "plattforms-agnostiska" och mycket överförbara.
Beroende på dess kapacitet, kommer alla datorseendeträningsarkitekturer att hitta några funktioner för objekt och klasser i ImageNet-datauppsättningen. Vissa arkitekturer kan hitta fler funktioner än andra, eller göra mer användbara kopplingar än andra, men alla bör hitta åtminstone de högsta funktionerna:

ImageNet-data, med minsta möjliga antal korrekta identifieringar – funktioner på hög nivå.
Det är dessa "högnivå"-funktioner som särskiljer och "fingeravtryck" en datauppsättning, och som är de pålitliga "krokarna" på vilka man kan hänga en långsiktig kontradiktorisk bildattackmetodik som kan sträcka sig över olika system och växa i takt med " gammal datauppsättning eftersom den senare vidmakthålls i ny forskning och nya produkter.
En mer sofistikerad arkitektur kommer att producera mer exakta och granulära identifikationer, funktioner och klasser:

Men desto mer förlitar sig en motståndskraftig attackgenerator på dessa lägre funktioner (dvs. "Ung kaukasisk man" istället för "Ansikte"), desto mindre effektivt blir det i cross-over eller senare arkitekturer som använder olika versioner av den ursprungliga datauppsättningen – till exempel en underuppsättning eller filtrerad uppsättning, där många av originalbilderna från hela datauppsättningen inte finns:

Motstridiga attacker på "nollställda", förtränade modeller
Vad sägs om fall där du bara laddar ner en förtränad modell som ursprungligen tränades på en mycket populär datauppsättning och ger den helt ny data?
Modellen har redan tränats på (till exempel) ImageNet, och allt som återstår är vikter, som kan ha tagit veckor eller månader att träna, och är nu redo att hjälpa dig att identifiera liknande objekt som de som fanns i den ursprungliga (nu frånvarande) data.

Med den ursprungliga data borttagen från träningsarkitekturen är det som återstår modellens "anlag" att klassificera objekt på det sätt som den ursprungligen lärde sig att göra, vilket i huvudsak kommer att få många av de ursprungliga "signaturerna" att reformeras och bli sårbara en gång. igen till samma gamla Adversarial Image Attack-metoder.
De vikterna är värdefulla. Utan data or vikterna har du i princip en tom arkitektur utan data. Du kommer att behöva träna den från grunden, till stor kostnad för tid och datorresurser, precis som de ursprungliga författarna gjorde (förmodligen på kraftfullare hårdvara och med en högre budget än du har tillgänglig).
Problemet är att vikterna redan är ganska välformade och spänstiga. Även om de kommer att anpassa sig något i träningen, kommer de att bete sig på samma sätt på din nya data som de gjorde på den ursprungliga data, och producera signaturfunktioner som ett motståndssystem kan slå in igen.
På lång sikt bevarar även detta "DNA" från datauppsättningar för datorseende tolv år eller äldre, och kan ha gått igenom en anmärkningsvärd utveckling från öppen källkodssatsningar till kommersialiserade distributioner – även där den ursprungliga utbildningsdatan var helt övergiven i början av projektet. Vissa av dessa kommersiella distributioner kanske inte kommer att ske på flera år än.
Ingen vit låda behövs
När det gäller den andra vanliga kritiken av kontradiktoriska bildattacksystem, har författarna till det nya dokumentet funnit att deras förmåga att lura igenkänningssystem med skapade bilder av blommor är mycket överförbar till ett antal arkitekturer.
Samtidigt som de observerar att deras 'Universal NaTuralistic adversarial patches' (TnT)-metod är den första som använder igenkännbara bilder (snarare än slumpmässigt störningsbrus) för att lura bildigenkänningssystem, men författarna säger också:
"[TnT] är effektiva mot flera toppmoderna klassificerare, allt från allmänt använda WideResNet50 i uppgiften Storskalig visuell igenkänning av IMAGEnet dataset till VGG-ansiktsmodeller i ansiktsigenkänningsuppgiften PubFig dataset i båda riktade och oriktade attacker.
'TnTs kan ha: i) den naturalism som kan uppnås [med] triggers som används i trojanska attackmetoder; och ii) generaliseringen och överförbarheten av motsatta exempel till andra nätverk.
"Detta väcker säkerhets- och säkerhetsproblem angående redan utplacerade DNN:er såväl som framtida DNN-distributioner där angripare kan använda oansenliga, naturliga objektlappar för att vilseleda neurala nätverkssystem utan att manipulera modellen och riskera upptäckt."
Författarna föreslår att konventionella motåtgärder, såsom försämring av Clean Acc. av ett nätverk, skulle teoretiskt kunna ge ett visst försvar mot TnT-patchar, men det "TnTs kan fortfarande framgångsrikt kringgå dessa SOTA bevisbara försvarsmetoder med de flesta försvarssystem som uppnår 0% robusthet".
Möjliga andra lösningar inkluderar federerat lärande, där härkomsten av bidragande bilder skyddas, och nya tillvägagångssätt som direkt kan "kryptera" data vid träningstid, t.ex. föreslog nyligen av Nanjing University of Aeronautics and Astronautics.
Även i de fallen skulle det vara viktigt att träna på genuint ny bilddata – vid det här laget är bilderna och tillhörande kommentarer i den lilla ramen av de mest populära CV-datauppsättningarna så inbäddade i utvecklingscykler runt om i världen att de liknar programvara mer än data; programvara som ofta inte har uppdaterats särskilt på flera år.
Slutsats
Motstridiga bildattacker möjliggörs inte bara av metoder för maskininlärning med öppen källkod, utan också av en företags AI-utvecklingskultur som är motiverad att återanvända väletablerade datauppsättningar för datorseende av flera skäl: de har redan visat sig effektiva; de är mycket billigare än att "börja från början"; och de underhålls och uppdateras av avantgarde hjärnor och organisationer över akademi och industri, på nivåer av finansiering och bemanning som skulle vara svåra för ett enskilt företag att replikera.
Dessutom, i många fall där uppgifterna inte är original (till skillnad från CityScapes), samlades bilderna innan de senaste kontroverserna kring sekretess och datainsamlingsmetoder, vilket lämnade dessa äldre datamängder i ett slags halvrättslig skärselden som kan se tröstande ut som en "säker hamn", ur ett företags synvinkel.
TnT attacker! Universal Naturalistic Adversarial Patches mot Deep Neural Network Systems är medförfattare av Bao Gia Doan, Minhui Xue, Ehsan Abbasnejad, Damith C. Ranasinghe från University of Adelaide, tillsammans med Shiqing Ma från institutionen för datavetenskap vid Rutgers University.
Uppdaterad 1 december 2021, 7:06 GMT+2 – korrigerat stavfel.















