
Artificiell intelligens
InstructIR: Högkvalitativ bildåterställning enligt mänskliga instruktioner

En bild kan förmedla mycket, men den kan också störas av olika problem som rörelseoskärpa, dis, brus och lågt dynamiskt omfång. Dessa problem, vanligtvis kallade försämringar i datorseende på låg nivå, kan uppstå från svåra miljöförhållanden som värme eller regn eller från begränsningar hos själva kameran. Bildåterställning representerar en kärnutmaning inom datorseende, och strävar efter att återställa en högkvalitativ, ren bild från en som uppvisar sådana försämringar. Bildåterställning är komplex eftersom det kan finnas flera lösningar för att återställa en given bild. Vissa tillvägagångssätt riktar sig mot specifika försämringar, som att minska brus eller ta bort oskärpa eller dis.
Även om dessa metoder kan ge goda resultat för särskilda problem, kämpar de ofta för att generalisera över olika typer av försämring. Många ramverk använder ett generiskt neuralt nätverk för ett brett utbud av bildåterställningsuppgifter, men dessa nätverk tränas var för sig. Behovet av olika modeller för varje typ av nedbrytning gör detta tillvägagångssätt beräkningsmässigt dyrt och tidskrävande, vilket leder till fokus på allt-i-ett-återställningsmodeller i den senaste utvecklingen. Dessa modeller använder en enda, djupt blind restaureringsmodell som adresserar flera nivåer och typer av nedbrytning, ofta med användning av nedbrytningsspecifika uppmaningar eller vägledningsvektorer för att förbättra prestandan. Även om Allt-i-ett-modeller vanligtvis visar lovande resultat, står de fortfarande inför utmaningar med omvända problem.
InstructIR representerar ett banbrytande tillvägagångssätt på området, och är den första bildåterställning ram utformad för att vägleda restaureringsmodellen genom mänskliga skrivna instruktioner. Det kan bearbeta naturliga språkuppmaningar för att återställa högkvalitativa bilder från försämrade bilder, med tanke på olika försämringstyper. InstructIR sätter en ny standard för prestanda för ett brett spektrum av bildåterställningsuppgifter, inklusive urtömning, avbrusning, avlusning, suddighet och förstärkning av bilder i svagt ljus.
Den här artikeln syftar till att täcka InstructIR-ramverket på djupet, och vi utforskar mekanismen, metodiken, arkitekturen för ramverket tillsammans med dess jämförelse med toppmoderna ramverk för bild- och videogenerering. Så låt oss börja.
InstructIR: Högkvalitativ bildåterställning
Bildåterställning är ett grundläggande problem inom datorseende eftersom det syftar till att återställa en högkvalitativ ren bild från en bild som visar försämringar. I datorseende på låg nivå är Degradations en term som används för att representera obehagliga effekter som observeras i en bild som rörelseoskärpa, dis, brus, lågt dynamiskt omfång och mer. Anledningen till att bildåterställning är en komplex omvänd utmaning är att det kan finnas flera olika lösningar för att återställa vilken bild som helst. Vissa ramverk fokuserar på specifika försämringar som att reducera instansbrus eller försvaga bilden, medan andra kan fokusera mer på att ta bort suddighet eller suddighet, eller rensa dis eller dedis.
De senaste metoderna för djupinlärning har visat starkare och mer konsekvent prestanda jämfört med traditionella bildåterställningsmetoder. Dessa djuplärande bildåterställningsmodeller föreslår att man ska använda neurala nätverk baserade på transformatorer och konvolutionella neurala nätverk. Dessa modeller kan tränas oberoende för olika bildåterställningsuppgifter, och de har också förmågan att fånga lokala och globala funktionsinteraktioner och förbättra dem, vilket resulterar i tillfredsställande och konsekvent prestanda. Även om vissa av dessa metoder kan fungera adekvat för specifika typer av nedbrytning, extrapolerar de vanligtvis inte bra till olika typer av nedbrytning. Dessutom, medan många befintliga ramverk använder samma neurala nätverk för en mängd bildåterställningsuppgifter, tränas varje neurala nätverksformulering separat. Därför är det uppenbart att det är omöjligt och tidskrävande att använda en separat neural modell för varje tänkbar nedbrytning, vilket är anledningen till att de senaste ramverken för bildåterställning har koncentrerats på allt-i-ett-återställningsproxyer.
Allt-i-ett eller multi-degradering eller multi-task bildåterställningsmodeller vinner popularitet inom datorseendeområdet eftersom de kan återställa flera typer och nivåer av försämringar i en bild utan att behöva träna modellerna oberoende för varje degradering . Allt-i-ett-bildåterställningsmodeller använder en enda djupblinda bildåterställningsmodell för att hantera olika typer och nivåer av bildförsämring. Olika Allt-i-ett-modeller implementerar olika tillvägagångssätt för att vägleda den blinda modellen för att återställa den försämrade bilden, till exempel en hjälpmodell för att klassificera degraderingen eller flerdimensionella styrvektorer eller uppmaningar för att hjälpa modellen att återställa olika typer av försämring inom en bild.
Med det sagt kommer vi fram till textbaserad bildmanipulation eftersom den har implementerats av flera ramverk under de senaste åren för text-till-bild-generering och textbaserade bildredigeringsuppgifter. Dessa modeller använder ofta textuppmaningar för att beskriva åtgärder eller bilder tillsammans med diffusionsbaserade modeller för att generera motsvarande bilder. Den huvudsakliga inspirationen för InstructIR-ramverket är InstructPix2Pix-ramverket som gör det möjligt för modellen att redigera bilden med hjälp av användarinstruktioner som instruerar modellen om vilken åtgärd som ska utföras istället för textetiketter, beskrivningar eller bildtexter för inmatningsbilden. Som ett resultat kan användare använda naturliga skrivna texter för att instruera modellen om vilken åtgärd som ska utföras utan att behöva tillhandahålla exempelbilder eller ytterligare bildbeskrivningar.
Bygger på dessa grunder, är InstructIR-ramverket den första datorseendemodellen någonsin som använder mänskliga skrivna instruktioner för att uppnå bildåterställning och lösa omvända problem. För naturliga språkuppmaningar kan InstructIR-modellen återställa bilder av hög kvalitet från sina försämrade motsvarigheter och tar även hänsyn till flera försämringstyper. InstructIR-ramverket kan leverera toppmodern prestanda för ett brett utbud av bildåterställningsuppgifter, inklusive bildavvänjning, avbrusning, avlusning, suddighet och bildförbättring i svagt ljus. I motsats till befintliga verk som uppnår bildåterställning med hjälp av inlärda vägledningsvektorer eller prompt-inbäddningar, använder InstructIR-ramverket råa användarmeddelanden i textform. InstructIR-ramverket kan generalisera till att återställa bilder med hjälp av mänskliga skrivna instruktioner, och den enda allt-i-ett-modellen som implementeras av InstructIR täcker fler återställningsuppgifter än tidigare modeller. Följande figur visar de olika återställningsexemplen av InstructIR-ramverket.

InstructIR : Metod och arkitektur
I sin kärna består InstructIR-ramverket av en textkodare och en bildmodell. Modellen använder NAFNet-ramverket, en effektiv bildåterställningsmodell som följer en U-Net-arkitektur som bildmodell. Dessutom implementerar modellen uppgiftsdirigeringstekniker för att framgångsrikt lära sig flera uppgifter med en enda modell. Följande figur illustrerar utbildnings- och utvärderingsmetoden för InstructIR-ramverket.

Med inspiration från InstructPix2Pix-modellen antar InstructIR-ramverket mänskliga skrivna instruktioner som kontrollmekanism eftersom det inte finns något behov för användaren att tillhandahålla ytterligare information. Dessa instruktioner erbjuder ett uttrycksfullt och tydligt sätt att interagera så att användare kan peka ut den exakta platsen och typen av försämring i bilden. Att använda användarmeddelanden istället för fasta degraderingsspecifika anvisningar förbättrar dessutom modellens användbarhet och tillämpningar eftersom den även kan användas av användare som saknar den erforderliga domänexpertisen. För att utrusta InstructIR-ramverket med förmågan att förstå olika uppmaningar, använder modellen GPT-4, en stor språkmodell för att skapa olika förfrågningar, med tvetydiga och oklara uppmaningar borttagna efter en filtreringsprocess.
Textkodare
En textkodare används av språkmodeller för att mappa användarmeddelanden till en textinbäddning eller en vektorrepresentation med fast storlek. Traditionellt är textkodaren för en CLIP modell är en viktig komponent för textbaserad bildgenerering och textbaserade bildmanipuleringsmodeller för att koda användaruppmaningar eftersom CLIP-ramverket utmärker sig i visuella uppmaningar. Men de flesta gånger har användaruppmaningar om försämring lite eller inget visuellt innehåll, vilket gör de stora CLIP-kodarna oanvändbara för sådana uppgifter eftersom det kommer att hämma effektiviteten avsevärt. För att ta itu med detta problem väljer InstructIR-ramverket en textbaserad meningskodare som är tränad att koda meningar i ett meningsfullt inbäddningsutrymme. Meningskodare är förutbildade på miljontals exempel och ändå är de kompakta och effektiva i jämförelse med traditionella CLIP-baserade textkodare samtidigt som de har förmågan att koda semantiken i olika användarmeddelanden.
Textvägledning
En viktig aspekt av InstructIR-ramverket är implementeringen av den kodade instruktionen som en kontrollmekanism för bildmodellen. Byggande på detta, och inspirerat av uppgiftsdirigering för många uppgiftsinlärning, föreslår InstructIR-ramverket ett Instruction Construction Block eller ICB för att möjliggöra uppgiftsspecifika transformationer inom modellen. Konventionell uppgiftsdirigering tillämpar uppgiftsspecifika binära masker på kanalfunktioner. Men eftersom InstructIR-ramverket inte känner till degraderingen, implementeras inte denna teknik direkt. Vidare, för bildfunktioner och de kodade instruktionerna, tillämpar InstructIR-ramverket uppgiftsdirigering, och producerar masken med hjälp av ett linjärt lager aktiverat med Sigmoid-funktionen för att producera en uppsättning vikter beroende på textinbäddning, vilket ger en c-dimensionell per kanal binär mask. Modellen förbättrar ytterligare de betingade särdragen med användning av ett NAFBlock och använder NAFBlock och Instruction Conditioned Block för att konditionera särdragen vid både kodarblocket och avkodarblocket.
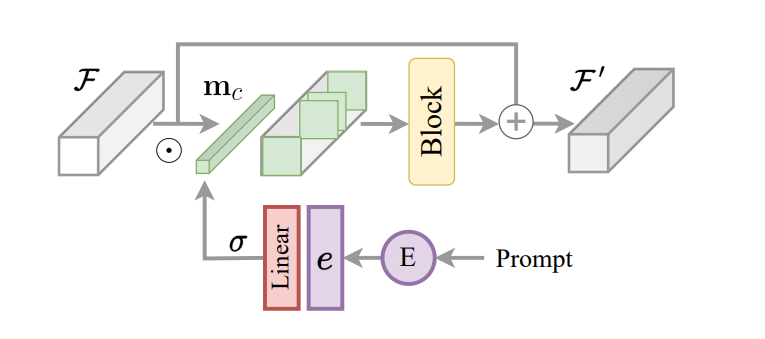
Även om InstructIR-ramverket inte uttryckligen villkorar de neurala nätverksfiltren, underlättar masken modellen att välja de kanaler som är mest relevanta på basis av bildinstruktionen och informationen.
InstructIR: Implementering och resultat
InstructIR-modellen är end-to-end-träningsbar, och bildmodellen kräver ingen förträning. Det är bara textinbäddningsprojektioner och klassificeringshuvud som behöver tränas. Textkodaren initieras med hjälp av en BGE-kodare, en BERT-liknande kodare som är förtränad på en enorm mängd övervakad och oövervakad data för generisk meningskodning. InstructIR-ramverket använder NAFNet-modellen som bildmodell, och NAFNets arkitektur består av en 4-nivå kodaravkodare med varierande antal block på varje nivå. Modellen lägger också till 4 mittblock mellan kodaren och dekodern för att ytterligare förbättra funktionerna. Dessutom, istället för att sammanfoga för överhoppningsanslutningarna, implementerar avkodaren addition, och InstructIR-modellen implementerar endast ICB eller Instruction Conditioned Block för uppgiftsdirigering endast i kodare och avkodare. När vi går vidare optimeras InstructIR-modellen genom att använda förlusten mellan den återställda bilden och den rena bilden från marken, och korsentropiförlusten används för avsiktsklassificeringshuvudet för textkodaren. InstructIR-modellen använder AdamW-optimeraren med en batchstorlek på 32 och en inlärningshastighet på 5e-4 under nästan 500 epoker, och implementerar även cosinusglödgningens inlärningshastighet. Eftersom bildmodellen i InstructIR-ramverket endast omfattar 16 miljoner parametrar, och det bara finns 100 tusen inlärda textprojektionsparametrar, kan InstructIR-ramverket enkelt tränas på standard-GPU:er, vilket minskar beräkningskostnaderna och ökar tillämpbarheten.
Flera nedbrytningsresultat
För flera nedbrytningar och återställningar med flera uppgifter, definierar InstructIR-ramverket två initiala inställningar:
- 3D för tre-nedbrytningsmodeller för att ta itu med nedbrytningsproblem som avlusning, avbrusning och avränning.
- 5D för fem nedbrytningsmodeller för att ta itu med försämringsproblem som bildnedsättning, förbättringar i svagt ljus, avlusning, nedbrytning och avrening.
Prestandan för 5D-modeller visas i följande tabell och jämför den med toppmodern bildrestaurering och allt-i-ett-modeller.

Som det kan observeras kan InstructIR-ramverket med en enkel bildmodell och bara 16 miljoner parametrar hantera fem olika bildåterställningsuppgifter framgångsrikt tack vare den instruktionsbaserade vägledningen, och levererar konkurrenskraftiga resultat. Följande tabell visar ramverkets prestanda på 3D-modeller, och resultaten är jämförbara med ovanstående resultat.

Huvudhöjdpunkten i InstructIR-ramverket är instruktionsbaserad bildåterställning, och följande figur visar InstructIR-modellens otroliga förmåga att förstå ett brett utbud av instruktioner för en given uppgift. För en kontradiktorisk instruktion utför InstructIR-modellen en identitet som inte är framtvingad.

Avslutande tankar
Bildåterställning är ett grundläggande problem inom datorseende eftersom det syftar till att återställa en högkvalitativ ren bild från en bild som visar försämringar. I datorseende på låg nivå är Degradations en term som används för att representera obehagliga effekter som observeras i en bild som rörelseoskärpa, dis, brus, lågt dynamiskt omfång och mer. I den här artikeln har vi pratat om InstructIR, världens första ramverk för bildåterställning som syftar till att vägleda bildåterställningsmodellen med hjälp av mänskliga skrivna instruktioner. För naturliga språkuppmaningar kan InstructIR-modellen återställa bilder av hög kvalitet från sina försämrade motsvarigheter och tar även hänsyn till flera försämringstyper. InstructIR-ramverket kan leverera toppmodern prestanda för ett brett utbud av bildåterställningsuppgifter, inklusive bildavvänjning, avbrusning, avlusning, suddighet och bildförbättring i svagt ljus.















