AI 101
Vad är Bayes sats?
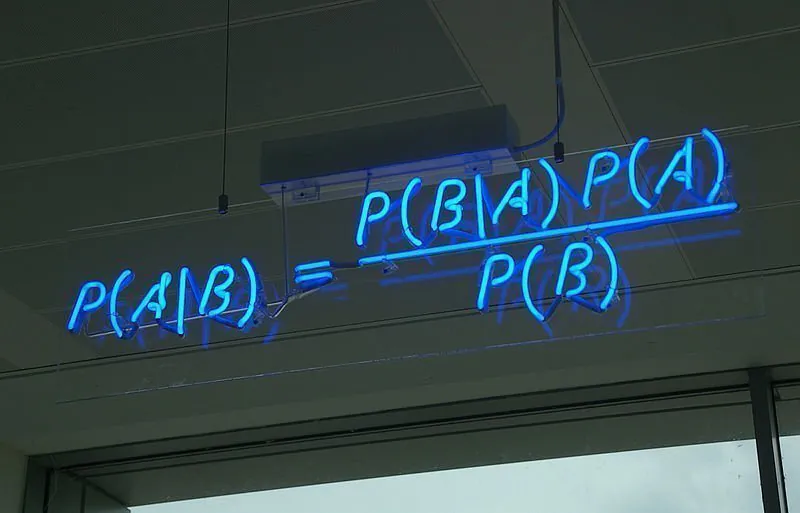
Om du har lärt dig om data science eller maskinlärning, finns det en god chans att du har hört termen “Bayes sats” tidigare, eller en “Bayes-klassificerare”. Dessa begrepp kan vara ganska förvirrande, särskilt om du inte är van att tänka på sannolikhet från ett traditionellt, frekventistiskt statistiskt perspektiv. Den här artikeln kommer att försöka förklara principerna bakom Bayes sats och hur den används i maskinlärning.
Vad är Bayes sats?
Bayes sats är en metod för beräkning av villkorlig sannolikhet. Den traditionella metoden för att beräkna villkorlig sannolikhet (sannolikheten att en händelse inträffar givet att en annan händelse inträffar) är att använda formeln för villkorlig sannolikhet, beräkna den gemensamma sannolikheten för händelse ett och händelse två som inträffar samtidigt, och sedan dividera den med sannolikheten för händelse två som inträffar. Men villkorlig sannolikhet kan också beräknas på ett annat sätt med hjälp av Bayes sats.
När du beräknar villkorlig sannolikhet med Bayes sats, använder du följande steg:
- Bestäm sannolikheten för att villkor B är sant, under förutsättning att villkor A är sant.
- Bestäm sannolikheten för att händelse A är sant.
- Multiplicera de två sannolikheterna.
- Dividera med sannolikheten för att händelse B inträffar.
Detta betyder att formeln för Bayes sats kan uttryckas på följande sätt:
P(A|B) = P(B|A)*P(A) / P(B)
Att beräkna villkorlig sannolikhet på detta sätt är särskilt användbart när den omvända villkorliga sannolikheten kan beräknas lätt, eller när beräkning av den gemensamma sannolikheten skulle vara för utmanande.
Exempel på Bayes sats
Detta kan vara lättare att tolka om vi tillbringar lite tid med att titta på ett exempel på hur du skulle tillämpa bayesiskt resonemang och Bayes sats. Låt oss anta att du spelade ett enkelt spel där flera deltagare berättar en historia och du måste bestämma vilken av deltagarna som ljuger för dig. Låt oss fylla i ekvationen för Bayes sats med variablerna i detta hypotetiska scenario.
Vi försöker förutsäga om varje individ i spelet ljuger eller talar sanning, så om det finns tre spelare förutom dig, kan de kategoriska variablerna uttryckas som A1, A2 och A3. Bevisen för deras lögner/sanning är deras beteende. Som när du spelar poker, skulle du leta efter vissa “tells” som en person ljuger och använda dem som bitar av information för att informera din gissning. Eller om du fick fråga dem, skulle det vara alla bevis som deras historia inte stämmer överens. Vi kan representera bevisen för att en person ljuger som B.
För att förtydliga, vi försöker förutsäga sannolikheten (A ljuger/talar sanning | givet bevisen för deras beteende). För att göra detta skulle vi vilja ta reda på sannolikheten för B givet A, eller sannolikheten för att deras beteende skulle inträffa givet att personen verkligen ljuger eller talar sanning. Du försöker bestämma under vilka förhållanden beteendet du ser skulle ha mest mening. Om det finns tre beteenden du bevittnar, skulle du göra beräkningen för varje beteende. Till exempel P(B1, B2, B3 * A). Du skulle sedan göra detta för varje förekomst av A / för varje person i spelet förutom dig. Det är den här delen av ekvationen ovan:
P(B1, B2, B3,|A) * P|A
Till slut dividerar vi bara med sannolikheten för B.
Om vi fick några bevis om de faktiska sannolikheterna i den här ekvationen, skulle vi återskapa vår sannolikhetsmodell, med hänsyn till det nya beviset. Detta kallas uppdatering av dina priorer, eftersom du uppdaterar dina antaganden om den tidigare sannolikheten för de observerade händelserna.
Maskinlärningsapplikationer för Bayes sats
Den vanligaste användningen av Bayes sats när det gäller maskinlärning är i form av Naive Bayes-algoritmen.
Naive Bayes används för klassificering av både binära och multi-klass dataset, Naive Bayes får sitt namn eftersom de värden som tilldelas vittnesbevisen / attributen – Bs i P(B1, B2, B3 * A) – antas vara oberoende av varandra. Det antas att dessa attribut inte påverkar varandra för att förenkla modellen och göra beräkningar möjliga, istället för att försöka beräkna relationerna mellan varje attribut. Trots denna förenklade modell tenderar Naive Bayes att fungera ganska bra som en klassificeringsalgoritm, även när detta antagande förmodligen inte är sant (vilket är de flesta gånger).
Det finns också vanligt använda varianter av Naive Bayes-klassificeraren, såsom Multinomial Naive Bayes, Bernoulli Naive Bayes och Gaussian Naive Bayes.
Multinomial Naive Bayes-algoritmer används ofta för att klassificera dokument, eftersom det är effektivt för att tolka frekvensen av ord inom ett dokument.
Bernoulli Naive Bayes fungerar på liknande sätt som Multinomial Naive Bayes, men förutsägelserna som algoritmen ger är booleska. Detta betyder att när du förutsäger en klass, kommer värdena att vara binära, nej eller ja. Inom textklassificeringens domän skulle en Bernoulli Naive Bayes-algoritm tilldela parametrarna ett ja eller nej baserat på om ett ord finns i textdokumentet eller inte.
Om värdet på förutsägarna / funktionerna inte är diskreta utan är kontinuerliga, kan Gaussian Naive Bayes användas. Det antas att de kontinuerliga funktionernas värden har sampats från en gaussisk fördelning.












