
Artificiell intelligens
Trohet vs. realism i Deepfake-videor

Alla deepfake-utövare delar inte samma mål: drivkraften från forskningssektorn för bildsyntes – uppbackad av inflytelserika förespråkare som t.ex. Adobe, NVIDIA och Facebook – är att avancera den senaste tekniken så att maskininlärningstekniker så småningom kan återskapa eller syntetisera mänsklig aktivitet med hög upplösning och under de mest utmanande förhållanden (trohet).
Däremot är målet för dem som vill använda djupfalska teknologier för att sprida desinformation att skapa rimliga simuleringar av riktiga människor med många andra metoder än blotta sanningshalten i djupförfalskade ansikten. I det här scenariot är tilläggsfaktorer som sammanhang och rimlighet nästan lika med en videos potential att simulera ansikten (realism).
Den här "smart-of-hand"-metoden sträcker sig till försämringen av den slutliga bildkvaliteten för en djupförfalskad video, så att hela videon (och inte bara den vilseledande delen som representeras av ett djupförfalskat ansikte) har ett sammanhängande "utseende" som är korrekt för förväntad kvalitet för mediet.
"Kohesiv" behöver inte betyda "bra" – det räcker att kvaliteten är konsekvent över originalet och det infogade, förfalskade innehållet och följer förväntningarna. När det gäller VOIP-streaming på plattformar som Skype och Zoom, kan ribban vara anmärkningsvärt låg, med stamning, ryckig video och en hel rad potentiella komprimeringsartefakter, såväl som "utjämnande" algoritmer utformade för att minska deras effekter – vilket i sig utgör en ytterligare rad "oäkta" effekter som vi har accepterat som följder av begränsningarna och excentriciteterna med livestreaming.
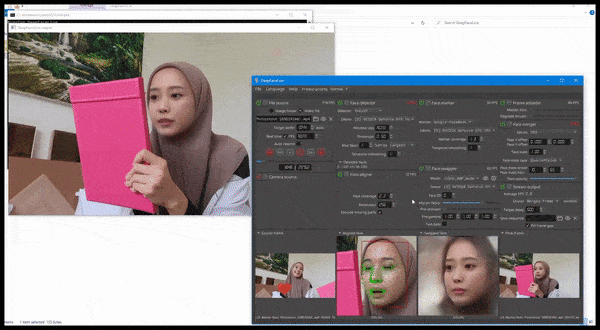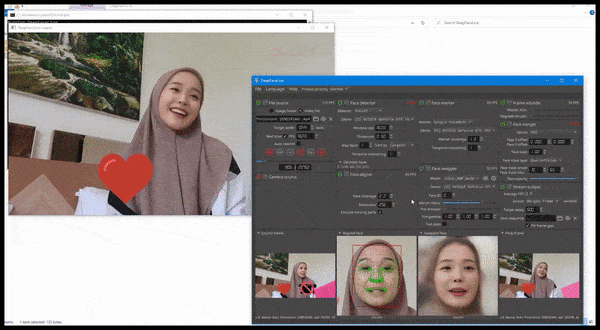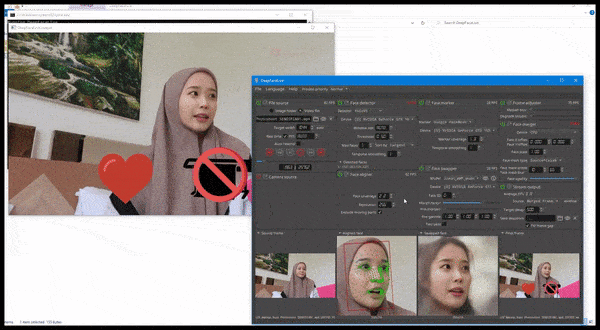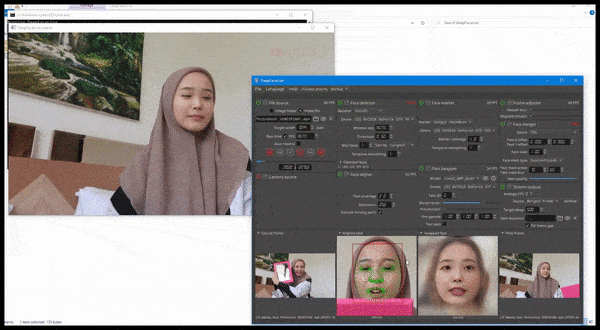
DeepFaceLive i aktion: den här strömmande versionen av den främsta deepfake-mjukvaran DeepFaceLab kan ge kontextuell realism genom att presentera förfalskningar i sammanhanget med begränsad videokvalitet, komplett med uppspelningsproblem och andra återkommande anslutningsartefakter. Källa: https://www.youtube.com/watch?v=IL517EgYH8U
Inbyggd nedbrytning
Faktum är att de två mest populära deepfake-paketen (båda härledda från den kontroversiella källkoden från 2017) innehåller komponenter som är avsedda att integrera det deepfakede ansiktet i sammanhanget med "historisk" eller video av lägre kvalitet genom att förnedra det genererade ansiktet. I DeepFaceLab, den bicubic_degrade_power parametern åstadkommer detta, och in Ansikts byte, "grain"-inställningen i Ffmpeg-konfigurationen hjälper likaså integreringen av det falska ansiktet genom att bevara kornet under kodning*.

Inställningen "korn" i FaceSwap hjälper till med autentisk integrering i videoinnehåll som inte kommer från HQ, och äldre innehåll som kan ha filmkorneffekter som är relativt sällsynta nuförtiden.
Ofta, istället för en komplett och integrerad deepfake-video, kommer deepfakers att mata ut en isolerad serie PNG-filer med alfakanaler, där varje bild endast visar den syntetiska ansiktsutmatningen, så att bildströmmen kan konverteras till video på plattformar med mer sofistikerade 'förnedrande effekter, till exempel Adobe After Effects, innan de falska och riktiga elementen sammanfogas för den slutliga videon.
Förutom dessa avsiktliga försämringar komprimeras ofta innehållet i deepfake-arbeten, antingen algoritmiskt (där sociala medieplattformar försöker spara bandbredd genom att producera lättare versioner av användarnas uppladdningar) på plattformar som YouTube och Facebook, eller genom att omarbeta originalverket till animerade GIF-bilder, detaljsektioner eller andra olika motiverade arbetsflöden som tar den ursprungliga utgåvan som utgångspunkt och sedan introducerar ytterligare komprimering.
Realistiska Deepfake-detekteringskontexter
Med detta i åtanke har en ny artikel från Schweiz föreslagit en förnyelse av metodiken bakom metoder för deepfake-detektering, genom att lära detektionssystem att lära sig egenskaperna hos deepfake-innehåll när det presenteras i avsiktligt försämrade sammanhang.

Stokastisk dataförstärkning tillämpas på en av datamängderna som används i det nya dokumentet, med Gaussiskt brus, gammakorrigering och Gaussisk oskärpa, samt artefakter från JPEG-komprimering. Källa: https://arxiv.org/pdf/2203.11807.pdf
I den nya artikeln hävdar forskarna att avantgarde deepfake-detekteringspaket förlitar sig på orealistiska benchmarkvillkor för sammanhanget för de mätvärden som de tillämpar, och att "försämrad" deepfake-utdata kan falla under minimikvalitetströskeln för upptäckt, även om de realistiskt sett "grungy" innehåll kommer sannolikt att vilseleda tittarna på grund av en korrekt uppmärksamhet på sammanhanget.
Forskarna har inlett en ny "verkliga" datanedbrytningsprocess som lyckas förbättra generaliserbarheten hos ledande deepfake-detektorer, med endast marginell förlust av noggrannhet på de ursprungliga detekteringshastigheterna som erhålls av "rena" data. De erbjuder också ett nytt ramverk för utvärdering som kan utvärdera robustheten hos deepfake-detektorer under verkliga förhållanden, med stöd av omfattande ablationsstudier.
Smakämnen papper har titeln Ett nytt tillvägagångssätt för att förbättra inlärningsbaserad Deepfake-detektion under realistiska förhållanden, och kommer från forskare vid Multimedia Signal Processing Group (MMSPG) och Ecole Polytechnique Federale de Lausanne (EPFL), båda baserade i Lausanne.
Användbar förvirring
Tidigare ansträngningar för att införliva försämrad utdata i metoder för deepfake-detektering inkluderar Mixup neurala nätverk, ett erbjudande 2018 från MIT och FAIR, och AugMix, ett samarbete från 2020 mellan DeepMind och Google, båda dataförstärkningsmetoder som försöker "lera" utbildningsmaterialet på ett sätt som är benäget att hjälpa till att generalisera.
Forskarna av det nya arbetet noterar också innan studier som tillämpade Gaussiskt brus och kompressionsartefakter på träningsdata för att fastställa gränserna för förhållandet mellan en härledd funktion och bruset i vilken den är inbäddad.
Den nya studien erbjuder en pipeline som simulerar de komprometterade förhållandena för både förvärvsprocessen för bildbehandling och komprimeringen och olika andra algoritmer som ytterligare kan försämra bildutdata i distributionsprocessen. Genom att införliva detta verkliga arbetsflöde i ett utvärderande ramverk är det möjligt att producera träningsdata för deepfake-detektorer som är mer resistenta mot artefakter.

Den konceptuella logiken och arbetsflödet för det nya tillvägagångssättet.
Nedbrytningsprocessen tillämpades på två populära och framgångsrika datauppsättningar som används för deepfake-detektering: FaceForensics ++ och Celeb-DFv2. Dessutom ledande ramverk för deepfake-detektorer Kapsel-Forensics och XceptionNet utbildades på de förfalskade versionerna av de två datamängderna.
Detektorerna tränades med Adam optimizer för 25 respektive 10 epoker. För datauppsättningstransformationen togs 100 bildrutor slumpmässigt från varje träningsvideo, med 32 bildrutor extraherade för testning, före tillägget av förnedrande processer.
De snedvridningar som beaktades för arbetsflödet var brus, där noll-medelvärde av Gaussiskt brus applicerades på sex olika nivåer; storleksändring, för att simulera den reducerade upplösningen av typiska utomhusbilder, vilket kan påverkar vanligtvis detektorer; kompression, där olika JPEG-komprimeringsnivåer tillämpades över data; glättning, där tre typiska utjämningsfilter som används i "avbrusning" utvärderas för ramverket; förbättring, där kontrast och ljusstyrka justerades; och kombinationer, där valfri blandning av tre av de ovannämnda metoderna applicerades samtidigt på en enda bild.
Test och resultat
Vid testning av data antog forskarna tre mått: noggrannhet (ACC); Område under mottagarens funktionskarakteristiska kurva (AUC); och F1-poäng.
Forskarna testade de standardtränade versionerna av de två deepfake-detektorerna mot förfalskade data och fann att de saknade:
"I allmänhet är de flesta realistiska förvrängningar och bearbetning ytterst skadliga för normalt tränade inlärningsbaserade deepfake-detektorer. Till exempel visar Capsule-Forensics-metoden mycket höga AUC-poäng på både okomprimerade FFpp- och Celeb-DFv2-testset efter träning på respektive datauppsättning, men lider sedan av drastisk prestandaminskning på modifierad data från vårt bedömningsramverk. Liknande trender har observerats med XceptionNet-detektorn.'
Däremot förbättrades prestandan för de två detektorerna avsevärt genom att de tränades på de transformerade data, med varje detektor nu mer kapabel att upptäcka osynliga vilseledande media.
"Dataförstärkningsschemat förbättrar avsevärt robustheten hos de två detektorerna och under tiden bibehåller de fortfarande hög prestanda på ursprungliga oförändrade data."

Prestandajämförelser mellan de råa och utökade datauppsättningarna som används över de två deepfake-detektorerna som utvärderades i studien.
Tidningen avslutar:
"Nuvarande detektionsmetoder är utformade för att uppnå så hög prestanda som möjligt på specifika riktmärken. Detta resulterar ofta i att generaliseringsförmågan offras till mer realistiska scenarier. I detta dokument föreslås ett noggrant utarbetat dataförstärkningsschema baserat på naturlig bildnedbrytningsprocess.
"Omfattande experiment visar att den enkla men effektiva tekniken avsevärt förbättrar modellens robusthet mot olika realistiska förvrängningar och bearbetningsoperationer i typiska avbildningsarbetsflöden."
* Matchande ådring i det genererade ansiktet är en funktion av stilöverföring under konverteringsprocessen.
Första gången publicerad 29 mars 2022. Uppdaterad 8:33 EST för att förtydliga användningen av spannmål i Ffmpeg.















