Artificiell intelligens
SofGAN: En GAN-ansiktsgenerator som erbjuder större kontroll
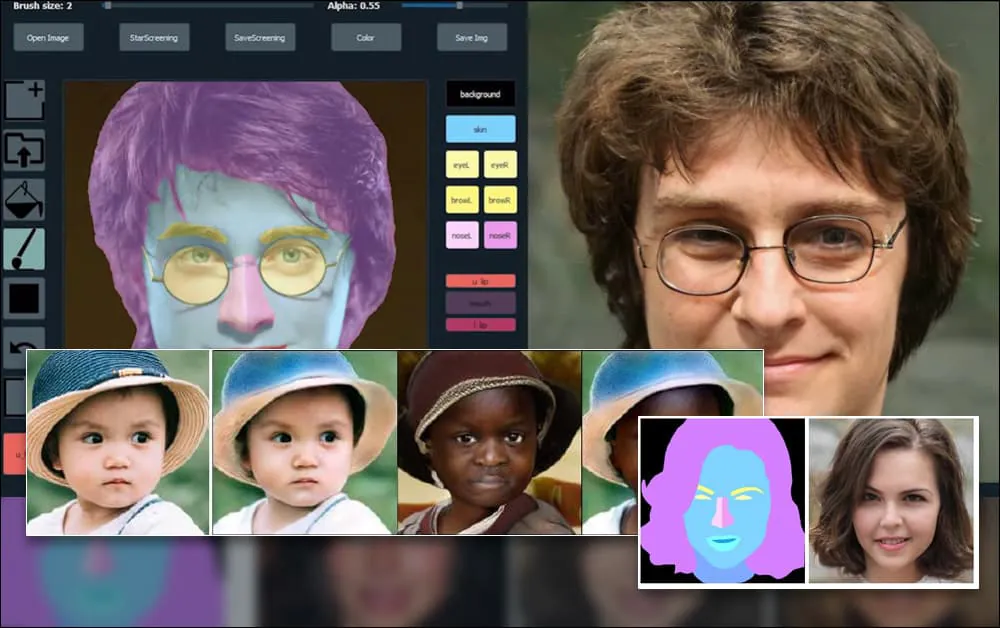
Forskare i Shanghai och USA har utvecklat ett GAN-baserat portraitskapande system som tillåter användare att skapa nya ansikten med en tidigare otillgänglig nivå av kontroll över enskilda aspekter som hår, ögon, glasögon, texturer och färg.
För att demonstrera systemets flexibilitet har skaparna tillhandahållit ett Photoshop-liknande gränssnitt där en användare kan direkt rita semantiska segmenterings-element som kommer att tolkas om till realistiska bilder, och som även kan erhållas genom att rita direkt över befintliga foton.
I exemplet nedan används en bild av skådespelaren Daniel Radcliffe som en spårningsmall (och målet är inte att producera en likhet med honom, utan snarare en allmänt fotorealistisk bild). När användaren fyller i olika element, inklusive diskreta aspekter som glasögon, identifieras och tolkas de i utdata-bilden:
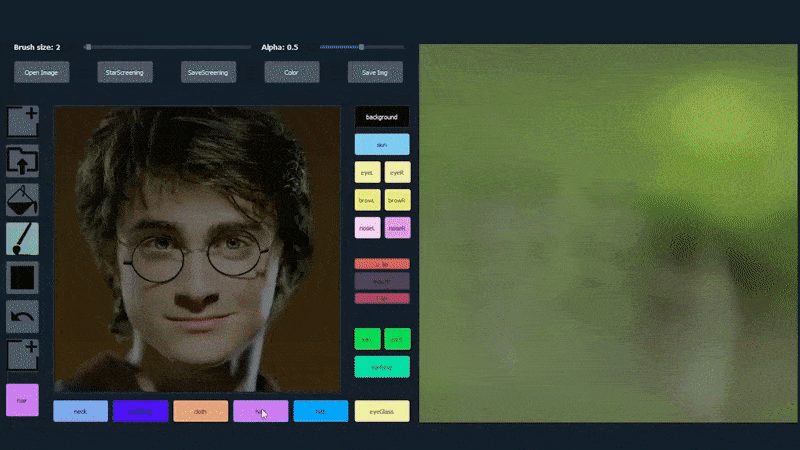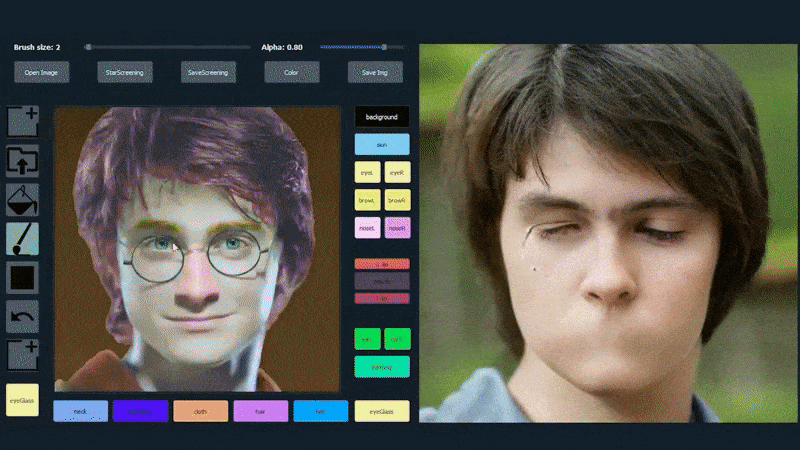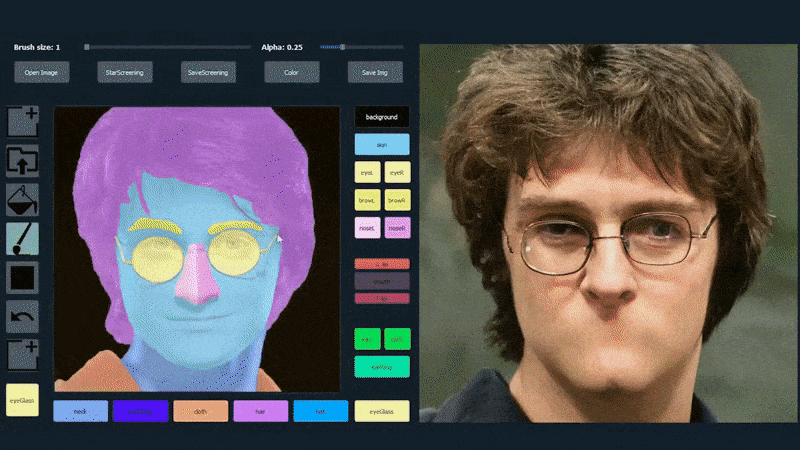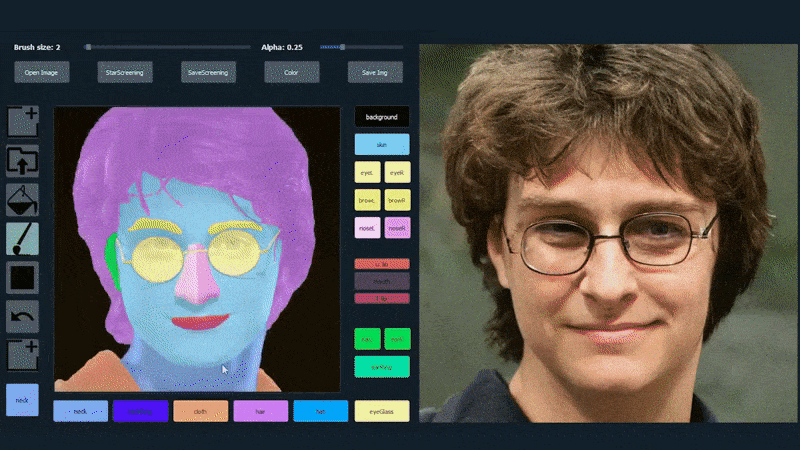
Användning av en bild som spårningsmaterial för en SofGAN-genererad porträtt. Källa: https://www.youtube.com/watch?v=xig8ZA3DVZ8
Den artikeln heter SofGAN: En porträttbildgenerator med dynamisk styling, och leds av Anpei Chen och Ruiyang Liu, tillsammans med två andra forskare från ShanghaiTech University och en från University of California i San Diego.
Att separera funktioner
Den primära bidraget från arbetet är inte så mycket att tillhandahålla ett användarvänligt gränssnitt, utan snarare att “separera” egenskaper hos inlärda ansiktsfunktioner, såsom pose och textur, vilket tillåter SofGAN att också generera ansikten som är indirekta vinklar till kameravyn.

Ovanligt bland ansiktsgenererare baserade på Generative Adversarial Networks, kan SofGAN ändra vyvinkeln efter behag, inom gränserna för den uppsättning vinklar som finns i träningsdata. Källa: https://arxiv.org/pdf/2007.03780.pdf
Eftersom texturer nu är separerade från geometri, kan ansiktsform och textur också manipuleras som separata enheter. I effekt, tillåter detta en rasändring av en källansikte, en skandalös praxis som nu har en potentiellt användbar tillämpning, för skapandet av rasbalanserade maskinläringsdataset.

SofGAN stöder också konstgjord åldrande och attribut-konsekvent stiljustering på en granulär nivå som inte ses i liknande segmenterings>bildsystem som NVIDIA’s GauGAN och Intel’s spelbaserade neuralt renderingsystem system.

SofGAN kan implementera åldrande som en iterativ stil.
En annan genombrott för SofGAN:s metodik är att träningsprocessen inte kräver parade segmenterings/verkliga bilder, utan kan tränas direkt på oparade verkliga världbilder.
Forskarna påstår att den “separerande” arkitekturen i SofGAN inspirerades av traditionella bildrenderingssystem, som bryter ner de enskilda aspekterna av en bild. I visuella effekter-arbetsflöden bryts elementen för en komposit ned till de minsta komponenterna, med specialister dedikerade till varje komponent.
Semantisk ockupationsfält (SOF)
För att uppnå detta i ett maskinlärningsbildsynthesramverk, utvecklade forskarna ett semantiskt ockupationsfält (SOF), en utvidgning av det traditionella ockupationsfältet som individuerar komponentelementen i ansiktsporträtt. SOF tränades på kalibrerade multi-vysemantiska segmenteringskartor, men utan någon grund sanningssupervision.

Flera iterationer från en enda segmenteringskarta (nedre vänster).
Dessutom erhålls 2D-segmenteringskartor genom att spåra utdata från SOF, innan de textureras av en GAN-generator. De “syntetiska” semantiska segmenteringskartorna kodas också i ett lågdimensionellt utrymme via en tre-lagers encoder för att säkerställa kontinuitet i utdata när vyvinkeln ändras.
Träningsplanen spatialt blandar två slumpmässiga stilar för varje semantisk region:

Arkitekturen för SofGAN.
Forskarna hävdar att SofGAN uppnår en lägre Frechet Inception Distance (FID) än den nuvarande alternativa staten av konst (SOTA)-tillvägagångssätt, samt en högre Learned Perceptual Image Patch Similarity (LPIPS)-mått.
Tidigare StyleGAN-tillvägagångssätt har ofta hämmats av funktionssammanflätning, där elementen som utgör en bild är oåterkalleligt bundna till varandra, vilket orsakar oönskade element att dyka upp tillsammans med ett önskat element (t.ex. örhängen kan dyka upp när en öraform återges som informerades vid tränningstiden av en bild som visade örhängen).

Ray marching används för att beräkna volymen av semantiska segmenteringskartor, vilket möjliggör flera vyvinklar.
Dataset och träningsdata
Tre dataset användes i utvecklingen av olika implementeringar av SofGAN: CelebAMask-HQ, ett repository med 30 000 högupplösta bilder tagna från CelebA-HQ-datasetet; NVIDIA’s Flickr-Faces-HQ (FFHQ), som innehåller 70 000 bilder, där forskarna märkte bilderna med en förtränad ansiktsparser; och en självproducerad grupp med 122 porträttscans med manuellt märkta semantiska regioner.
SOF består av tre tränbara undermoduler – hypernätet, en ray marcher (se bild ovan), och en klassificerare. Projektets Semantic Instance Wised (SIW) StyleGAN-generator är konfigurerad liknande StyleGAN2 i vissa aspekter. Dataförstärkning tillämpas genom slumpmässig skalning och beskärning, och träningsfunktioner vägregularisering var fjärde steg. Hela träningsförfarandet tog 22 dagar för att nå 800 000 iterationer på fyra RTX 2080 Ti GPU:er över CUDA 10.1.
Forskarna observerar att acceptabla, allmänt högnivåresultat började dyka upp ganska tidigt i träningsprocessen, vid 1500 iterationer, tre dagar in i träningsprocessen. Resten av träningsprocessen upptogs av den förutsägbara, långsamma krawlen mot att erhålla fina detaljer som hår och ögonfasetter.
SofGAN uppnår i allmänhet mer realistiska resultat från en enda segmenteringskarta än rivaliserande metoder som NVIDIA’s SPADE och Pix2PixHD, och SEAN.

Nedan är videon som släpptes av forskarna. Ytterligare självvärdshållna videor finns tillgängliga på projektsidan.
https://www.youtube.com/watch?v=xig8ZA3DVZ8












