Artificiell intelligens
AudioSep : Separera Allt Du Beskriver
LASS eller Language-queried Audio Source Separation är den nya paradigmen för CASA eller Computational Auditory Scene Analysis som syftar till att separera en målljud från en given blandning av ljud med hjälp av en naturligt språkfråga som tillhandahåller ett naturligt men skalbart gränssnitt för digitala ljuduppgifter och applikationer. Även om LASS-ramverken har utvecklats avsevärt under de senaste åren när det gäller att uppnå önskad prestanda på specifika ljudkällor som musikinstrument, kan de inte separera målljudet i det öppna området.
AudioSep, är ett grundläggande modell som syftar till att lösa de nuvarande begränsningarna i LASS-ramverken genom att möjliggöra målljudseparation med hjälp av naturligt språkfrågor. Utvecklarna av AudioSep-ramverket har tränat modellen omfattande på en stor mängd stora multimodala datamängder och har utvärderat prestandan för ramverket på en stor mängd ljuduppgifter, inklusive musikinstrumentseparation, ljudhändelseseparation och förbättring av tal, bland många andra. Den initiala prestandan för AudioSep tillfredsställer benchmarken eftersom den visar imponerande nollskottslärande förmågor och levererar stark ljudseparationsprestanda.
I den här artikeln kommer vi att ta en djupare titt på hur AudioSep-ramverket fungerar, eftersom vi kommer att utvärdera modellens arkitektur, de datamängder som används för träning och utvärdering, och de viktigaste begreppen som är involverade i AudioSep-modellens funktion. Så låt oss börja med en grundläggande introduktion till CASA-ramverket.
CASA, USS, QSS, LASS-ramverk : Grundvalen för AudioSep
CASA eller Computational Auditory Scene Analysis-ramverket är ett ramverk som används av utvecklare för att konstruera maskinlyssningssystem som kan uppfatta komplexa ljudmiljöer på ett sätt som liknar hur människor uppfattar ljud med hjälp av sina auditiva system. Ljudseparation, med särskild fokus på målljudseparation, är ett grundläggande område för forskning inom CASA-ramverket, och det syftar till att lösa “cocktail party-problemet” eller separera riktiga ljudinspelningar från individuella ljudkällinspelningar eller filer. Vikten av ljudseparation kan huvudsakligen tillskrivas dess omfattande tillämpningar, inklusive musikkällseparation, ljudkällseparation, talförbättring, målljudidentifiering och mycket mer.
Det mesta av arbetet med ljudseparation som har gjorts i det förflutna kretsar huvudsakligen kring separationen av en eller flera ljudkällor, som musikseparation eller talseparation. En ny modell som kallas USS eller Universal Sound Separation syftar till att separera godtyckliga ljud i riktiga ljudinspelningar. Men det är en utmanande och restriktiv uppgift att separera varje ljudkälla från en ljudblandning, huvudsakligen på grund av den stora mängden olika ljudkällor som finns i världen, vilket är den viktigaste anledningen till att USS-metoden inte är genomförbar för verkliga tillämpningar som fungerar i realtid.
En genomförbar alternativ till USS-metoden är QSS eller Query-based Sound Separation-metoden som syftar till att separera en individuell eller målljudkälla från ljudblandningen baserat på en viss uppsättning frågor. Tack vare detta tillåter QSS-ramverket utvecklare och användare att extrahera önskade ljudkällor från blandningen baserat på deras krav, vilket gör QSS-metoden till en mer praktisk lösning för digitala verkliga tillämpningar som multimediainnehållsredigering eller ljudredigering.
Dessutom har utvecklare nyligen föreslagit en utvidgning av QSS-ramverket, LASS-ramverket eller Language-queried Audio Source Separation-ramverket som syftar till att separera godtyckliga ljudkällor från en ljudblandning genom att använda naturligt språkbeskrivningar av målljudkällan. Eftersom LASS-ramverket tillåter användare att extrahera målljudkällor med hjälp av en uppsättning naturligt språkinstruktioner, kan det bli ett kraftfullt verktyg med omfattande tillämpningar i digitala ljudapplikationer. När det jämförs med traditionella ljudfrågade eller vision-frågade metoder erbjuder användning av naturligt språkinstruktioner för ljudseparation en större grad av fördel, eftersom det lägger till flexibilitet och gör det lättare och bekvämare att skaffa frågeinformation. Dessutom, när det jämförs med etikettfråga-baserade ljudseparationsramverk som använder en fördefinierad uppsättning instruktioner eller frågor, begränsar LASS-ramverket inte antalet indatafrågor och har flexibiliteten att generaliseras till öppet område utan ansträngning.
Ursprungligen bygger LASS-ramverket på övervakat lärande, där modellen tränas på en uppsättning märkta ljud-textparade data. Men det viktigaste problemet med denna metod är den begränsade tillgängligheten av annoterade och märkta ljud-textdata. För att minska LASS-ramverkets beroende av annoterade ljud-textmärkta data, tränas modellerna med hjälp av multimodalt övervakat lärande. Det primära syftet med att använda ett multimodalt övervakat tillvägagångssätt är att använda multimodala kontrastiva förträningsmodeller som CLIP eller Contrastive Language Image Pre Training-modellen som frågekodare för ramverket. Eftersom CLIP-ramverket har förmågan att anpassa textinbäddningar med andra modaliteter som ljud eller syn, tillåter det utvecklare att träna LASS-modellerna med hjälp av datarika modaliteter och tillåter interferens med textdata i en nollskottinställning. De nuvarande LASS-ramverken använder dock småskaliga datamängder för träning, och tillämpningar av LASS-ramverket över hundratals potentiella domäner återstår att utforskas.
För att lösa de nuvarande begränsningarna som LASS-ramverken står inför, har utvecklare introducerat AudioSep, ett grundläggande modell som syftar till att separera ljud från en ljudblandning med hjälp av naturligt språkbeskrivningar. Den nuvarande fokusen för AudioSep är att utveckla en förtränad ljudseparationsmodell som utnyttjar befintliga stora multimodala datamängder för att möjliggöra generalisering av LASS-modeller i öppet domänapplikationer. För att sammanfatta, AudioSep-modellen är: “En grundläggande modell för universell ljudseparation i öppet område med hjälp av naturligt språkfrågor eller beskrivningar tränad på stora multimodala datamängder”.
AudioSep : Nyckelkomponenter och Arkitektur
Arkitekturen för AudioSep-ramverket består av två nyckelkomponenter: en textkodare och en separationsmodell.
Textkodaren
AudioSep-ramverket använder en textkodare från CLIP eller Contrastive Language Image Pre Training-modellen eller CLAP eller Contrastive Language Audio Pre Training-modellen för att extrahera textinbäddningar inom en naturligt språkfråga. Indata-textfrågan består av en sekvens av “N” token som sedan bearbetas av textkodaren för att extrahera textinbäddningarna för den givna indata-språkfrågan. Textkodaren använder en stapel av transformerblock för att koda indata-texttoken och utdatarepresentationerna sammanfogas efter att de har passerat transformerlagren, vilket resulterar i utvecklingen av en D-dimensionell vektorrepresentation med fast längd, där D motsvarar dimensionerna för CLAP eller CLIP-modellerna, medan textkodaren är frusen under träningsperioden.
CLIP-modellen är förtränad på en stor datamängd av bild-textparade data med hjälp av kontrastivt lärande, vilket är den primära anledningen till att dess textkodare lär sig att mappa textbeskrivningar på det semantiska utrymmet som också delas av de visuella representationerna. Fördelen som AudioSep får genom att använda CLIP:s textkodare är att den nu kan skala upp eller träna LASS-modellen från oannoterad ljud-visualiserad data med hjälp av de visuella inbäddningarna som en alternativ, vilket möjliggör träning av LASS-modeller utan krav på annoterad eller märkt ljud-textdata.
CLAP-modellen fungerar på samma sätt som CLIP-modellen och använder kontrastivt lärandemål och använder en text- och ljudkodare för att ansluta ljud och språk, vilket bringar text- och ljudbeskrivningar till ett ljud-textlatentsutrymme som är förenat.
Separationsmodell
AudioSep-ramverket använder en frekvensdomän ResUNet-modell som matas med en blandning av ljudklipp som separationsryggrad för ramverket. Ramverket fungerar genom att först applicera en STFT eller Short-Time Fourier Transform på vågformen för att extrahera en komplex spektrogram, magnitudspektrogram och fasen av X. Modellen följer sedan samma inställning och konstruerar en encoder-decoder-nätverk för att bearbeta magnitudspektrogrammet.
ResUNet-encoder-decoder-nätverket består av 6 residualblock, 6 decoderblock och 4 flaskhalsblock. Spektrogrammet i varje encoderblock använder 4 residuala konventionella block för att nedsample sig till en flaskhalsfunktion, medan decoderblocken använder 4 residuala dekonvolutionsblock för att erhålla separationskomponenterna genom att översample funktionerna. Efter detta etablerar varje encoderblock och dess motsvarande decoderblock en hoppanslutning som fungerar vid samma översampling eller nedsampletakt. Residualblocket i ramverket består av 2 Leaky-ReLU-aktiveringslager, 2 batchnormaliseringslager och 2 CNN-lager, och dessutom introducerar ramverket en ytterligare residualgenväg som ansluter ingången och utgången av varje enskild residualblock. ResUNet-modellen tar den komplexa spektrogrammet X som indata och producerar magnitudmasken M som utdata med fasresiduen som villkorsstyrs av textinbäddningar som kontrollerar magnituden av skalning och rotationen av spektrogrammets vinkel. Det separerade komplexa spektrogrammet kan sedan extraheras genom att multiplicera den förutsagda magnitudmasken och fasresiduen med STFT (Short-Time Fourier Transform) av blandningen.

I sin ramverk använder AudioSep en FiLm eller Feature-wise Linearly modulerad lager för att brottas separationsmodellen och textkodaren efter distributionen av de konvolutionsblock i ResUNet.
Träning och Förlust
Under träningsfasen för AudioSep-modellen använder utvecklare ljudförstärkningsmetoden och tränar AudioSep-ramverket från ände till ände med hjälp av en L1-förlustfunktion mellan grundtruth- och förutsagda vågformer.
Datamängder och Benchmark
Som nämndes i tidigare avsnitt är AudioSep ett grundläggande modell som syftar till att lösa den nuvarande beroendet av LASS-modeller på annoterade ljud-textparade datamängder. AudioSep-modellen tränas på en stor mängd datamängder för att utrusta den med multimodalt lärande, och här är en detaljerad beskrivning av datamängden och benchmarken som används av utvecklare för att träna AudioSep-ramverket.
AudioSet
AudioSet är en svagt märkt stor datamängd som består av över 2 miljoner 10-sekunders ljudklipp som extraheras direkt från YouTube. Varje ljudklipp i AudioSet-datamängden är kategoriserad av frånvaron eller närvaron av ljudklasser utan specifika tidningsdetaljer om ljudhändelserna. AudioSet-datamängden har över 500 distinkta ljudklasser, inklusive naturljud, människoljud, fordonsljud och mycket mer.
VGGSound
VGGSound-datamängden är en stor datamängd som liknar AudioSet och har också hämtats direkt från YouTube, och den innehåller över 200 000 videoklipp, var och en med en längd av 10 sekunder. VGGSound-datamängden är kategoriserad i över 300 ljudklasser, inklusive människoljud, naturljud, fågelljud och mer. Användningen av VGGSound-datamängden säkerställer att objektet som ansvarar för att producera målljudet också kan beskrivas i den motsvarande visuella klippen.
AudioCaps
AudioCaps är den största offentligt tillgängliga ljudbeskrivningsdatamängden och består av över 50 000 10-sekunders ljudklipp som extraheras från AudioSet-datamängden. Datamängden i AudioCaps är indelad i tre kategorier: träningsdata, testdata och valideringsdata, och ljudklippen är märkta med naturligt språkbeskrivningar med hjälp av Amazon Mechanical Turk-plattformen. Det är värt att notera att varje ljudklipp i träningsdatamängden har en enda beskrivning, medan datamängden i test- och valideringsuppsättningarna har 5 grundtruth-beskrivningar vardera.
ClothoV2
ClothoV2 är en ljudbeskrivningsdatamängd som består av klipp som hämtats från FreeSound-plattformen, och liknar AudioCaps, där varje ljudklipp är märkt med naturligt språkbeskrivningar med hjälp av Amazon Mechanical Turk-plattformen.
WavCaps
Liksom AudioSet är WavCaps en svagt märkt stor datamängd som består av över 400 000 ljudklipp med beskrivningar, och en total körtid som uppskattas till 7568 timmar av träningsdata. Ljudklippen i WavCaps-datamängden är hämtade från en stor mängd ljudkällor, inklusive BBC Sound Effects, AudioSet, FreeSound, SoundBible och mer.

Träningsdetaljer
Under träningsfasen för AudioSep-modellen slumpmässigt provar utvecklare två ljudsegment från två olika ljudklipp från träningsdatamängden och blandar sedan samman dem för att skapa en träningsblandning där längden på varje ljudsegment är cirka 5 sekunder. Modellen extraherar sedan det komplexa spektrogrammet från vågformssignalen med hjälp av ett Hann-fönster av storlek 1024 med en hopstorlek på 320.
Modellen använder sedan textkodaren från CLIP/CLAP-modellerna för att extrahera textinbäddningarna med textsupervision som standardkonfiguration för AudioSep. För separationsmodellen använder AudioSep-ramverket en ResUNet-lager som består av 30 lager, 6 encoderblock och 6 decoderblock som liknar arkitekturen som följs i den universella ljudseparationsramverket. Dessutom har varje encoderblock två konvolutionslager med en kärnstorlek på 3×3 med antalet utgående funktionella kartor för encoderblocken som är 32, 64, 128, 256, 512 och 1024 respectively. Decoderblocken delar symmetri med encoderblocken, och utvecklarna tillämpar Adam-optimisatorn för att träna AudioSep-modellen med en batchstorlek på 96.
Utvärderingsresultat
På Set Datamängder
Följande figur jämför prestandan för AudioSep-ramverket på set datamängder under träningsfasen, inklusive träningsdatamängderna. Figuren nedan representerar benchmark-utvärderingsresultaten för AudioSep-ramverket när det jämförs med baslinjesystem, inklusive Speech Enhancement-modeller, LASS och CLIP. AudioSep-modellen med CLIP-textkodare representeras som AudioSep-CLIP, medan AudioSep-modellen med CLAP-textkodare representeras som AudioSep-CLAP.

Som det kan ses i figuren, fungerar AudioSep-ramverket bra när det använder ljudbeskrivningar eller textetiketter som indatafrågor, och resultaten indikerar den överlägsna prestandan för AudioSep-ramverket när det jämförs med tidigare benchmark LASS och ljudfrågade ljudseparationsmodeller.
På Osedda Datamängder
För att bedöma prestandan för AudioSep i en nollskottinställning, utvärderade utvecklarna prestandan på osedda datamängder, och AudioSep-ramverket levererar imponerande separationsprestanda i en nollskottinställning, och resultaten visas i figuren nedan.

Dessutom visar bilden nedan resultaten från utvärderingen av AudioSep-modellen mot Voicebank-Demand talförbättring.

Utvärderingen av AudioSep-ramverket indikerar en stark och önskad prestanda på osedda datamängder i en nollskottinställning, och därmed möjliggör utförandet av ljudoperationer på nya datadistributioner.
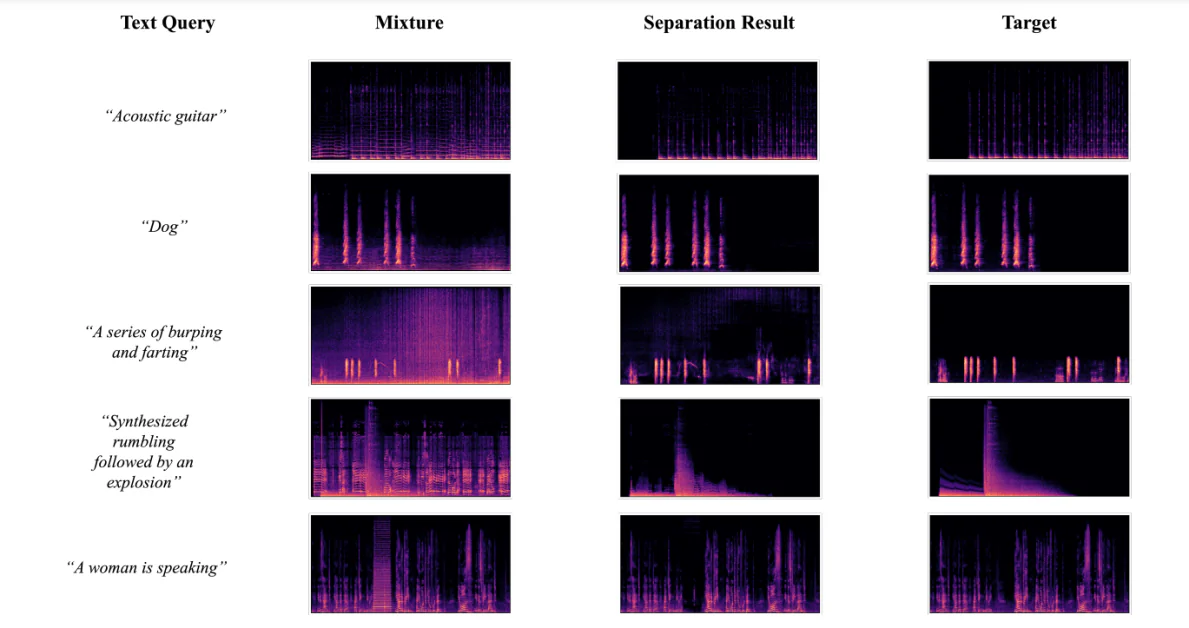
Visualisering av Separationsresultat
Följande figur visar resultaten som erhållits när utvecklarna använde AudioSep-CLAP-ramverket för att visualisera spektrogram för grundtruth-målljudkällor, ljudblandningar och separerade ljudkällor med hjälp av textfrågor av olika ljud eller ljud. Resultaten tillät utvecklare att observera att separerad källspektrograms mönster är nära den källa som är grundtruth, vilket ytterligare stöder de objektiva resultaten som erhållits under experimenten.
Jämförelse av Textfrågor
Utvecklarna utvärderar prestandan för AudioSep-CLAP och AudioSep-CLIP på AudioCaps Mini, och utvecklarna använder AudioSet-händelseetiketter, AudioCaps-beskrivningar och omannoterade naturligt språkbeskrivningar för att undersöka effekterna av olika frågor, och följande figur visar ett exempel på AudioCaps Mini i aktion.

Slutsats
AudioSep är ett grundläggande modell som utvecklats med syftet att vara ett öppet domänuniversellt ljudseparationsramverk som använder naturligt språkbeskrivningar för ljudseparation. Som observerats under utvärderingen, är AudioSep-ramverket kapabelt att utföra nollskott och oövervakat lärande utan ansträngning genom att använda ljudbeskrivningar eller textetiketter som frågor. Resultaten och utvärderingsprestandan för AudioSep indikerar en stark prestanda som överträffar nuvarande tillstånd för ljudseparationsramverk som LASS, och det kan vara kapabelt att lösa de nuvarande begränsningarna för populära ljudseparationsramverk.












