
Best Of
10 Algoritmet më të Mirë të Mësimit të Makinerisë
Megjithëse po jetojmë një kohë inovacioni të jashtëzakonshëm në mësimin e makinerive të përshpejtuar nga GPU, punimet më të fundit kërkimore shpesh (dhe në mënyrë të dukshme) paraqesin algoritme që janë dekada, në raste të caktuara 70 vjeç.
Disa mund të pretendojnë se shumë nga këto metoda më të vjetra hyjnë në kampin e 'analizës statistikore' dhe jo në mësimin e makinës dhe preferojnë të datojnë ardhjen e sektorit vetëm në vitin 1957, me shpikja e Perceptronit.
Duke pasur parasysh shkallën në të cilën këta algoritme më të vjetër mbështesin dhe janë të përfshirë në tendencat më të fundit dhe zhvillimet mbresëlënëse në mësimin e makinerive, është një qëndrim i kontestueshëm. Pra, le të hedhim një vështrim në disa nga blloqet e ndërtimit "klasikë" që mbështesin risitë më të fundit, si dhe disa hyrje më të reja që po bëjnë një ofertë të hershme për sallën e famës së AI.
1: Transformatorët
Në vitin 2017 Google Research udhëhoqi një bashkëpunim kërkimor që kulmoi në letër Vëmendja është gjithçka që ju nevojitet. Puna përvijoi një arkitekturë të re që promovonte mekanizmat e vëmendjes nga 'tubacionet' në kodues/dekoder dhe modelet e rrjetit të përsëritur në një teknologji qendrore transformuese më vete.
Qasja u dublua transformator, dhe që atëherë është bërë një metodologji revolucionare në Përpunimin e Gjuhëve Natyrore (NLP), duke fuqizuar, ndër shumë shembuj të tjerë, modelin e gjuhës autoregresive dhe GPT-3 të posterit të AI-së.
![]()
Transformatorët zgjidhën në mënyrë elegante problemin e transduksioni i sekuencës, i quajtur edhe 'transformim', i cili merret me përpunimin e sekuencave hyrëse në sekuenca dalëse. Një transformator gjithashtu merr dhe menaxhon të dhënat në një mënyrë të vazhdueshme, dhe jo në grupe të njëpasnjëshme, duke lejuar një 'qëndrueshmëri të memories' të cilën arkitekturat RNN nuk janë krijuar për ta marrë. Për një përmbledhje më të detajuar të transformatorëve, hidhini një sy artikulli ynë i referencës.
Ndryshe nga Rrjetet Neural Recurrent (RNN) që kishin filluar të dominonin kërkimin e ML në epokën CUDA, arkitektura e Transformerit gjithashtu mund të ishte lehtësisht paralelizuar, duke hapur rrugën për të adresuar në mënyrë produktive një korpus shumë më të madh të dhënash sesa RNN-të.
Përdorimi popullor
Transformers pushtoi imagjinatën e publikut në vitin 2020 me lëshimin e GPT-3 të OpenAI, i cili mburrej me një rekord të atëhershëm. 175 miliardë parametra. Kjo arritje në dukje befasuese u errësua përfundimisht nga projektet e mëvonshme, siç është viti 2021 lirimin i Megatron-Turing NLG 530B i Microsoft, i cili (siç sugjeron emri) përmban mbi 530 miliardë parametra.

Një afat kohor i projekteve të Transformer NLP në shkallë të lartë. Burimi: microsoft
Arkitektura e transformatorëve ka kaluar gjithashtu nga NLP në vizionin kompjuterik, duke fuqizuar a gjeneratë e re të kornizave të sintezës së imazhit si OpenAI KLIP PLLAKA, të cilat përdorin hartën e domenit tekst> imazh për të përfunduar imazhet jo të plota dhe për të sintetizuar imazhe të reja nga domene të trajnuara, midis një numri në rritje të aplikacioneve të lidhura.

DALL-E përpiqet të plotësojë një imazh të pjesshëm të bustit të Platonit. Burimi: https://openai.com/blog/dall-e/
2: Rrjetet kundërshtare gjeneruese (GAN)
Megjithëse transformatorët kanë fituar një mbulim të jashtëzakonshëm mediatik përmes lëshimit dhe miratimit të GPT-3, Rrjeti i kundërshtarëve gjenerues (GAN) është bërë një markë e njohur më vete dhe mund të bashkohet përfundimisht deepfake si folje.
Propozuar së pari në 2014 dhe përdoret kryesisht për sintezën e imazhit, një rrjet kundërshtar gjenerues arkitekturë është i përbërë nga një Gjenerator dhe një Diskriminues. Gjeneratori kalon nëpër mijëra imazhe në një grup të dhënash, duke u përpjekur në mënyrë të përsëritur t'i rindërtojë ato. Për çdo përpjekje, Diskriminuesi vlerëson punën e Gjeneratorit dhe e kthen Gjeneratorin për të bërë më mirë, por pa ndonjë pasqyrë në mënyrën se si gaboi rindërtimi i mëparshëm.

Burimi: https://developers.google.com/machine-learning/gan/gan_structure
Kjo e detyron Gjeneratorin të eksplorojë një sërë rrugësh, në vend që të ndjekë rrugicat e verbëra të mundshme që do të kishin rezultuar nëse Diskriminuesi do t'i kishte treguar se ku po shkonte keq (shih #8 më poshtë). Deri në përfundimin e trajnimit, Gjeneratori ka një hartë të detajuar dhe gjithëpërfshirëse të marrëdhënieve midis pikave në grupin e të dhënave.

Nga letra Përmirësimi i ekuilibrit GAN duke rritur ndërgjegjësimin hapësinor: një kornizë e re qarkullon nëpër hapësirën latente ndonjëherë misterioze të një GAN, duke ofruar instrumentalitet të përgjegjshëm për një arkitekturë të sintezës së imazhit. Burimi: https://genforce.github.io/eqgan/
Për analogji, ky është ndryshimi midis mësimit të një udhëtimi të vetëm me zhurmë në qendër të Londrës, ose blerjes me mundim Dituria.
Rezultati është një koleksion i nivelit të lartë të veçorive në hapësirën latente të modelit të trajnuar. Treguesi semantik për një tipar të nivelit të lartë mund të jetë 'person', ndërsa një zbritje përmes specifikës që lidhet me veçorinë mund të nxjerrë në dritë karakteristika të tjera të mësuara, si 'mashkull' dhe 'femër'. Në nivele më të ulëta, nën-tiparet mund të zbërthehen në, 'bjonde', 'kaukaziane', etj.
Ngatërrimi është një çështje e dukshme në hapësirën latente të GAN-ve dhe kornizave të koduesit/dekoderit: është buzëqeshja në një fytyrë femërore të krijuar nga GAN një tipar i ngatërruar i 'identitetit' të saj në hapësirën latente, apo është një degë paralele?

Fytyrat e krijuara nga GAN nga ky person nuk ekzistojnë. Burimi: https://this-person-does-not-exist.com/en
Dy vitet e fundit kanë sjellë një numër në rritje të nismave të reja kërkimore në këtë drejtim, ndoshta duke hapur rrugën për redaktimin e nivelit të veçorive, të stilit Photoshop për hapësirën latente të një GAN, por për momentin, shumë transformime janë në mënyrë efektive. paketa të gjitha ose asgjë. Veçanërisht, lëshimi EditGAN i NVIDIA i fundit të vitit 2021 arrin një niveli i lartë i interpretueshmërisë në hapësirën latente duke përdorur maska segmentimi semantik.
Përdorimi popullor
Krahas përfshirjes së tyre (në fakt mjaft të kufizuar) në videot e njohura "deepfake", GAN-et me fokus imazhe/video janë përhapur gjatë katër viteve të fundit, duke magjepsur studiuesit dhe publikun. Mbajtja në hap me shpejtësinë marramendëse dhe shpeshtësinë e publikimeve të reja është një sfidë, megjithëse depoja e GitHub Aplikacione të mrekullueshme GAN synon të sigurojë një listë gjithëpërfshirëse.
Rrjetet gjeneruese kundërshtare në teori mund të nxjerrin veçori nga çdo domen i përshtatur mirë, duke përfshirë tekstin.
3: SVM
origjinën në 1963, Makina Vektoriale Mbështetëse (SVM) është një algoritëm thelbësor që shfaqet shpesh në kërkime të reja. Nën SVM, vektorët hartojnë shtrirjen relative të pikave të të dhënave në një grup të dhënash, ndërsa mbështetje vektorët përcaktojnë kufijtë midis grupeve, veçorive ose tipareve të ndryshme.
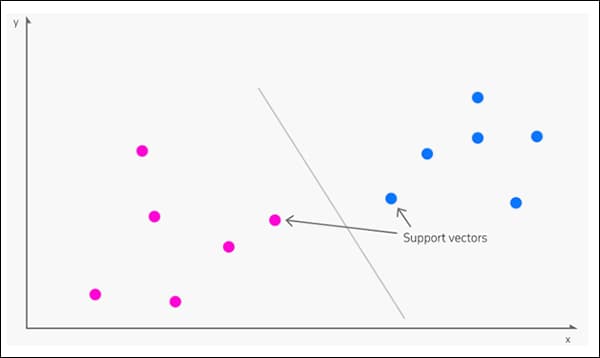
Vektorët mbështetës përcaktojnë kufijtë midis grupeve. Burimi: https://www.kdnuggets.com/2016/07/support-vector-machines-simple-explanation.html
Kufiri i prejardhur quhet a hiperplani.
Në nivele të ulëta të veçorive, SVM është dy dimensionale (imazhi më lart), por aty ku ka një numër më të madh të njohur grupesh ose llojesh, ai bëhet tripërmasor.

Një grup më i thellë pikash dhe grupesh kërkon një SVM tredimensionale. Burimi: https://cml.rhul.ac.uk/svm.html
Përdorimi popullor
Meqenëse Makinat Vektoriale mbështetëse mund të adresojnë në mënyrë efektive dhe agnostike të dhëna me dimensione të larta të shumë llojeve, ato shfaqen gjerësisht në një sërë sektorësh të mësimit të makinerive, duke përfshirë zbulimi i falsifikimit të thellë, klasifikimi i imazhit, klasifikimi i gjuhës së urrejtjes, Analiza e ADN-së parashikimi i strukturës së popullsisë, mes shumë të tjerave.
4: K-Means Clustering
Grumbullimi në përgjithësi është një të mësuarit pa mbikëqyrje qasje që kërkon të kategorizojë pikat e të dhënave përmes vlerësimi i densitetit, duke krijuar një hartë të shpërndarjes së të dhënave që studiohen.

K-Do të thotë grumbullimi i segmenteve, grupeve dhe bashkësive hyjnore në të dhëna. Burimi: https://aws.amazon.com/blogs/machine-learning/k-means-clustering-with-amazon-sagemaker/
K-Means Clustering është bërë zbatimi më i popullarizuar i kësaj qasjeje, duke përcjellë pikat e të dhënave në "Grupe K" të dallueshme, të cilat mund të tregojnë sektorë demografikë, komunitete në internet ose çdo grumbullim tjetër të mundshëm sekret që pret të zbulohet në të dhëna të papërpunuara statistikore.

Grupimet formohen në analizën K-Means. Burimi: https://www.geeksforgeeks.org/ml-determine-the-optimal-value-of-k-in-k-means-clustering/
Vetë vlera K është faktori përcaktues në dobinë e procesit dhe në vendosjen e një vlere optimale për një grup. Fillimisht, vlera K caktohet rastësisht, dhe veçoritë e saj dhe karakteristikat vektoriale krahasohen me fqinjët e saj. Ata fqinjë që i ngjajnë më shumë pikës së të dhënave me vlerën e caktuar rastësisht, i caktohen grupit të tij në mënyrë të përsëritur derisa të dhënat të kenë nxjerrë të gjitha grupimet që lejon procesi.
Grafiku për gabimin në katror, ose 'kosto' e vlerave të ndryshme midis grupimeve do të zbulojë një pikë bërryl për të dhënat:

'Pika e bërrylit' në një grafik grupor. Burimi: https://www.scikit-yb.org/en/latest/api/cluster/elbow.html
Pika e bërrylit është e ngjashme në koncept me mënyrën se si humbja rrafshohet në kthime të pakësuara në fund të një seance trajnimi për një grup të dhënash. Ai përfaqëson pikën në të cilën nuk do të bëhen të dukshme dallimet e mëtejshme midis grupeve, duke treguar momentin për të kaluar në fazat pasuese në tubacionin e të dhënave, ose për të raportuar gjetjet.
Përdorimi popullor
K-Means Clustering, për arsye të qarta, është një teknologji parësore në analizën e klientëve, pasi ofron një metodologji të qartë dhe të shpjegueshme për të përkthyer sasi të mëdha të të dhënave komerciale në njohuri demografike dhe 'drejtime'.
Jashtë këtij aplikacioni, K-Means Clustering është i punësuar edhe për parashikimi i rrëshqitjes së tokës, segmentimi i imazhit mjekësor, sinteza e imazhit me GAN, klasifikimi i dokumentevedhe planifikimi i qytetit, ndër shumë përdorime të tjera potenciale dhe aktuale.
5: Pylli i rastësishëm
Pylli i rastësishëm është një mësimi i ansamblit metodë që mesatarizon rezultatin nga një grup prej pemët e vendimit për të krijuar një parashikim të përgjithshëm për rezultatin.

Burimi: https://www.tutorialandexample.com/wp-content/uploads/2019/10/Decision-Trees-Root-Node.png
Nëse e keni hulumtuar edhe aq pak sa duke parë Back to the Future trilogji, një pemë vendimi në vetvete është mjaft e lehtë për t'u konceptuar: një numër shtigjesh shtrihen përpara jush, dhe secila shteg degëzohet në një rezultat të ri, i cili nga ana tjetër përmban shtigje të tjera të mundshme.
In të mësuarit për përforcim, ju mund të tërhiqeni nga një rrugë dhe të filloni përsëri nga një qëndrim i mëparshëm, ndërsa pemët e vendimeve angazhohen për udhëtimet e tyre.
Kështu, algoritmi Random Forest është në thelb bast për vendime. Algoritmi quhet 'i rastësishëm' sepse bën ad hoc përzgjedhje dhe vëzhgime për të kuptuar mesatare shuma e rezultateve nga grupi i pemës së vendimit.
Meqenëse merr parasysh një sërë faktorësh, një përqasje Random Forest mund të jetë më e vështirë të shndërrohet në grafikë kuptimplotë sesa një pemë vendimi, por ka të ngjarë të jetë dukshëm më produktive.
Pemët e vendimmarrjes i nënshtrohen përshtatjes së tepërt, ku rezultatet e marra janë specifike për të dhënat dhe nuk kanë gjasa të përgjithësohen. Përzgjedhja arbitrare e pikave të të dhënave nga Random Forest e lufton këtë tendencë, duke shpuar drejt tendencave përfaqësuese kuptimplote dhe të dobishme në të dhëna.

Regresioni i pemës së vendimit. Burimi: https://scikit-learn.org/stable/auto_examples/tree/plot_tree_regression.html
Përdorimi popullor
Ashtu si me shumë nga algoritmet në këtë listë, Random Forest zakonisht funksionon si një klasifikues dhe filtër "i hershëm" i të dhënave, dhe si i tillë shfaqet vazhdimisht në punimet e reja kërkimore. Disa shembuj të përdorimit të pyllit të rastësishëm përfshijnë Sinteza e imazhit të rezonancës magnetike, Parashikimi i çmimit të Bitcoin, segmentimi i regjistrimit, klasifikimi i tekstit zbulimi i mashtrimit me karta krediti.
Meqenëse Random Forest është një algoritëm i nivelit të ulët në arkitekturat e mësimit të makinerive, ai gjithashtu mund të kontribuojë në performancën e metodave të tjera të nivelit të ulët, si dhe algoritmeve të vizualizimit, duke përfshirë Grumbullimi induktiv, Transformimet e veçorive, klasifikimi i dokumenteve tekstuale duke përdorur veçori të rralladhe shfaqja e tubacioneve.
6: Naive Bayes
E shoqëruar me vlerësimin e densitetit (shih 4, lart), a naive Bayes klasifikuesi është një algoritëm i fuqishëm, por relativisht i lehtë, i aftë për të vlerësuar probabilitetet bazuar në tiparet e llogaritura të të dhënave.

Marrëdhëniet e veçorive në një klasifikues naiv të Bayes. Burimi: https://www.sciencedirect.com/topics/computer-science/naive-bayes-model
Termi 'naiv' i referohet supozimit në Teorema e Bayes që veçoritë janë të palidhura, të njohura si pavarësia e kushtëzuar. Nëse e përvetësoni këtë pikëpamje, ecja dhe të folurit si rosë nuk mjaftojnë për të vërtetuar se kemi të bëjmë me një rosë dhe asnjë supozim 'e qartë' nuk është miratuar para kohe.
Ky nivel i ashpërsisë akademike dhe hetimore do të ishte i tepruar aty ku është i disponueshëm 'mendimi i shëndoshë', por është një standard i vlefshëm kur kaloni paqartësitë e shumta dhe korrelacionet potencialisht të palidhura që mund të ekzistojnë në një grup të dhënash të mësimit të makinerive.
Në një rrjet origjinal Bayesian, veçoritë i nënshtrohen funksionet e pikëzimit, duke përfshirë gjatësinë minimale të përshkrimit dhe Shënon Bayesian, të cilat mund të vendosin kufizime mbi të dhënat për sa i përket lidhjeve të vlerësuara të gjetura midis pikave të të dhënave dhe drejtimit në të cilin rrjedhin këto lidhje.
Një klasifikues naiv Bayes, anasjelltas, funksionon duke supozuar se tiparet e një objekti të caktuar janë të pavarura, duke përdorur më pas teoremën e Bayes për të llogaritur probabilitetin e një objekti të caktuar, bazuar në veçoritë e tij.
Përdorimi popullor
Filtrat naive Bayes janë të përfaqësuar mirë në parashikimi i sëmundjes dhe kategorizimi i dokumenteve, filtrimi i spamit, klasifikimi i ndjenjave, sistemet rekomanduesedhe zbulimi i mashtrimit, ndër aplikime të tjera.
7: K- Fqinjët më të afërt (KNN)
Propozuar për herë të parë nga Shkolla e Mjekësisë së Aviacionit të Forcave Ajrore të SHBA në 1951, dhe duke u përshtatur me pajisjet kompjuterike moderne të mesit të shekullit të 20-të, K-Fqinjët më të afërt (KNN) është një algoritëm i dobët që ende shfaqet dukshëm në punimet akademike dhe iniciativat kërkimore të mësimit të makinerisë në sektorin privat.
KNN është quajtur 'nxënësi dembel', pasi skanon në mënyrë shteruese një grup të dhënash për të vlerësuar marrëdhëniet midis pikave të të dhënave, në vend që të kërkojë trajnimin e një modeli të plotë të mësimit të makinerive.

Një grupim KNN. Burimi: https://scikit-learn.org/stable/modules/neighbors.html
Megjithëse KNN është arkitektonikisht i hollë, qasja e tij sistematike vendos një kërkesë të dukshme për operacionet e leximit/shkrimit dhe përdorimi i tij në grupe të dhënash shumë të mëdha mund të jetë problematik pa teknologjitë shtesë si Analiza e Komponentit Kryesor (PCA), e cila mund të transformojë grupe të dhënash komplekse dhe me vëllim të lartë në grupimet përfaqësuese që KNN mund ta përshkojë me më pak përpjekje.
A Studimi i fundit vlerësoi efektivitetin dhe ekonominë e një numri algoritmesh të ngarkuara për të parashikuar nëse një punonjës do të largohej nga një kompani, duke gjetur se KNN shtatëvjeçare mbeti superior ndaj pretendentëve më modernë për sa i përket saktësisë dhe efektivitetit parashikues.
Përdorimi popullor
Me gjithë thjeshtësinë e tij popullore të konceptit dhe ekzekutimit, KNN nuk është mbërthyer në vitet 1950 - ai është përshtatur në një qasje më e fokusuar në DNN në një propozim të vitit 2018 nga Universiteti Shtetëror i Pensilvanisë, dhe mbetet një proces qendror i fazës së hershme (ose mjet analitik pas përpunimit) në shumë korniza shumë më komplekse të të mësuarit të makinerive.
Në konfigurime të ndryshme, KNN është përdorur ose për verifikimi i nënshkrimit në internet, klasifikimi i imazhit, nxjerrja e tekstit, parashikimi i të korravedhe njohja e fytyrës, përveç aplikacioneve dhe inkorporimeve të tjera.

Një sistem i njohjes së fytyrës i bazuar në KNN në trajnim. Source: https://pdfs.semanticscholar.org/6f3d/d4c5ffeb3ce74bf57342861686944490f513.pdf
8: Procesi i Vendimit Markov (MDP)
Një kornizë matematikore e prezantuar nga matematikani amerikan Richard Bellman në 1957, Procesi i Vendimit Markov (MDP) është një nga blloqet më themelore të të mësuarit për përforcim arkitekturave. Një algoritëm konceptual më vete, ai është përshtatur në një numër të madh algoritmesh të tjera dhe përsëritet shpesh në kulturën aktuale të kërkimit AI/ML.
PZHK eksploron një mjedis të dhënash duke përdorur vlerësimin e tij të gjendjes aktuale (dmth 'ku' është në të dhëna) për të vendosur se cilën nyje të të dhënave do të eksplorojë më pas.

Burimi: https://www.sciencedirect.com/science/article/abs/pii/S0888613X18304420
Një proces themelor i vendimmarrjes Markov do t'i japë përparësi përparësisë afatshkurtër mbi objektivat më të dëshirueshme afatgjata. Për këtë arsye, ai zakonisht përfshihet në kontekstin e një arkitekture më gjithëpërfshirëse politikash në të mësuarit përforcues dhe shpesh i nënshtrohet faktorëve kufizues si p.sh. shpërblim me zbritje, dhe variabla të tjerë modifikues mjedisorë që do ta pengojnë atë të nxitojë drejt një qëllimi të menjëhershëm pa marrë parasysh rezultatin më të gjerë të dëshiruar.
Përdorimi popullor
Koncepti i nivelit të ulët të MDP-së është i përhapur si në kërkime ashtu edhe në vendosjet aktive të mësimit të makinerive. Është propozuar për Sistemet e mbrojtjes së sigurisë IoT, vjelja e peshkutdhe parashikimi i tregut.
Përveç saj zbatueshmëri e dukshme ndaj shahut dhe lojërave të tjera rreptësisht sekuenciale, MDP është gjithashtu një pretendent i natyrshëm për të trajnim procedural i sistemeve robotike, siç mund ta shohim në videon e mëposhtme.

9: Frekuenca e termit-frekuenca e dokumentit të kundërt
Frekuenca e termave (TF) ndan numrin e herëve që një fjalë shfaqet në një dokument me numrin total të fjalëve në atë dokument. Kështu fjala vulë shfaqja një herë në një artikull me mijëra fjalë ka një frekuencë termash prej 0.001. Në vetvete, TF është kryesisht i padobishëm si një tregues i rëndësisë së termit, për faktin se artikujt e pakuptimtë (si p.sh. a, , ladhe it) mbizotërojnë.
Për të marrë një vlerë kuptimplote për një term, Frekuenca e Dokumentit të kundërt (IDF) llogarit TF-në e një fjale nëpër dokumente të shumta në një grup të dhënash, duke caktuar vlerësim të ulët për frekuencë shumë të lartë ndalesa, të tilla si artikuj. Vektorët e veçorive që rezultojnë normalizohen në vlera të plota, me çdo fjalë të caktuar një peshë të përshtatshme.

TF-IDF peshon rëndësinë e termave bazuar në frekuencën në një numër dokumentesh, me shfaqjen më të rrallë një tregues të spikatur. Burimi: https://moz.com/blog/inverse-document-frequency-and-the-importance-of-uniqueness
Megjithëse kjo qasje parandalon humbjen e fjalëve të rëndësishme semantike si skajet e jashtme, përmbysja e peshës së frekuencës nuk do të thotë automatikisht se një term me frekuencë të ulët është nuk një i jashtëzakonshëm, sepse disa gjëra janë të rralla pa vlerë. Prandaj, një term me frekuencë të ulët do të duhet të provojë vlerën e tij në kontekstin më të gjerë arkitektonik duke shfaqur (madje edhe me një frekuencë të ulët për dokument) në një numër dokumentesh në grupin e të dhënave.
Megjithë saj moshë, TF-IDF është një metodë e fuqishme dhe popullore për kalimet fillestare të filtrimit në kornizat e përpunimit të gjuhës natyrore.
Përdorimi popullor
Për shkak se TF-IDF ka luajtur të paktën një pjesë në zhvillimin e algoritmit kryesisht okult të PageRank të Google gjatë njëzet viteve të fundit, është bërë miratuar shumë gjerësisht si një taktikë manipuluese SEO, pavarësisht 2019 të John Mueller mohim rëndësinë e tij për rezultatet e kërkimit.
Për shkak të fshehtësisë rreth PageRank, nuk ka asnjë provë të qartë se TF-IDF është nuk aktualisht një taktikë efektive për t'u ngritur në renditjen e Google. Ndezëse diskutim në mesin e profesionistëve të IT kohët e fundit tregon një kuptim popullor, korrekt apo jo, se abuzimi me termin mund të rezultojë ende në vendosje të përmirësuar të SEO (megjithëse shtesë akuza për shpërdorim monopoli reklama e tepruar mjegulloni kufijtë e kësaj teorie).
10: Zbritja e gradientit stokastik
Zbritja Stokastike e Gradientit (SGD) është një metodë gjithnjë e më popullore për optimizimin e trajnimit të modeleve të mësimit të makinerive.
Vetë "Zbritja e gradientit" është një metodë për të optimizuar dhe më pas përcaktimin sasior të përmirësimit që një model po bën gjatë trajnimit.
Në këtë kuptim, 'gradient' tregon një pjerrësi poshtë (në vend të një gradimi të bazuar në ngjyra, shih imazhin më poshtë), ku pika më e lartë e 'kodrës', në të majtë, përfaqëson fillimin e procesit të trajnimit. Në këtë fazë modeli nuk e ka parë ende tërësinë e të dhënave as edhe një herë, dhe nuk ka mësuar mjaftueshëm për marrëdhëniet midis të dhënave për të prodhuar transformime efektive.

Një zbritje gradient në një seancë trajnimi FaceSwap. Mund të shohim se stërvitja ka pësuar një rrafshnaltë në pjesën e dytë, por përfundimisht ka rikuperuar rrugën e saj drejt një konvergjence të pranueshme.
Pika më e ulët, në të djathtë, përfaqëson konvergjencën (pika në të cilën modeli është po aq efektiv sa do të kalojë ndonjëherë nën kufizimet dhe cilësimet e imponuara).
Gradienti vepron si një rekord dhe parashikues për pabarazinë midis shkallës së gabimit (sa saktë modeli i ka hartuar aktualisht marrëdhëniet e të dhënave) dhe peshave (cilësimet që ndikojnë në mënyrën në të cilën modeli do të mësojë).
Ky regjistrim i progresit mund të përdoret për të informuar a orari i normës së mësimit, një proces automatik që i thotë arkitekturës të bëhet më e grimcuar dhe më e saktë ndërsa detajet e hershme të paqarta shndërrohen në marrëdhënie dhe harta të qarta. Në fakt, humbja e gradientit ofron një hartë në kohën e duhur se ku duhet të shkojë më pas trajnimi dhe si duhet të vazhdojë.
Risia e Prejardhjes Stochastic Gradient është se përditëson parametrat e modelit për çdo shembull trajnimi për përsëritje, gjë që në përgjithësi përshpejton udhëtimin drejt konvergjencës. Për shkak të ardhjes së grupeve të të dhënave në shkallë të lartë në vitet e fundit, SGD është rritur në popullaritet kohët e fundit si një metodë e mundshme për të adresuar çështjet logjistike që pasuan.
Nga ana tjetër, SGD ka implikime negative për shkallëzimin e veçorive dhe mund të kërkojë më shumë përsëritje për të arritur të njëjtin rezultat, duke kërkuar planifikim shtesë dhe parametra shtesë, krahasuar me zbritjen e zakonshme të gradientit.
Përdorimi popullor
Për shkak të konfigurimit të tij, dhe pavarësisht nga mangësitë e tij, SGD është bërë algoritmi më i popullarizuar i optimizimit për përshtatjen e rrjeteve nervore. Një konfigurim i SGD që po bëhet dominues në punimet e reja kërkimore AI/ML është zgjedhja e Vlerësimit të Momentit Përshtatës (ADAM, i prezantuar në 2015) optimizues.
ADAM përshtat normën e të mësuarit për çdo parametër në mënyrë dinamike ('shkalla e të mësuarit përshtatës'), si dhe përfshin rezultatet nga përditësimet e mëparshme në konfigurimin pasues ('momentum'). Për më tepër, ai mund të konfigurohet për të përdorur risitë e mëvonshme, si p.sh Momenti Nesterov.
Megjithatë, disa pohojnë se përdorimi i momentit gjithashtu mund të shpejtojë ADAM (dhe algoritme të ngjashme) në a përfundim jo optimal. Ashtu si me pjesën më të madhe të sektorit të kërkimit të mësimit të makinerive, SGD është një punë në progres.
Botuar për herë të parë më 10 shkurt 2022. Ndryshuar më 10 shkurt 20.05 EET – formatimi.















