
Inteligjenca artificiale
LipSync3D i Google ofron sinkronizim të përmirësuar të lëvizjes së gojës 'të thellë'

A bashkëpunim ndërmjet studiuesve të Google AI dhe Institutit Indian të Teknologjisë Kharagpur ofron një kornizë të re për të sintetizuar kokat që flasin nga përmbajtja audio. Projekti synon të prodhojë mënyra të optimizuara dhe me burime të arsyeshme për të krijuar përmbajtje video të 'kokës që flet' nga audio, për qëllime të sinkronizimit të lëvizjeve të buzëve me audion e dubluar ose të përkthyer nga makineri, dhe për përdorim në avatarë, në aplikacione interaktive dhe në të tjera mjedise në kohë reale.

Burimi: https://www.youtube.com/watch?v=L1StbX9OznY
Modelet e mësimit të makinerive të trajnuara në këtë proces - të quajtura LipSync3D - kërkojnë vetëm një video të vetme të identitetit të fytyrës së synuar si të dhëna hyrëse. Tubacioni i përgatitjes së të dhënave ndan nxjerrjen e gjeometrisë së fytyrës nga vlerësimi i ndriçimit dhe aspekteve të tjera të një videoje hyrëse, duke lejuar një trajnim më ekonomik dhe më të fokusuar.
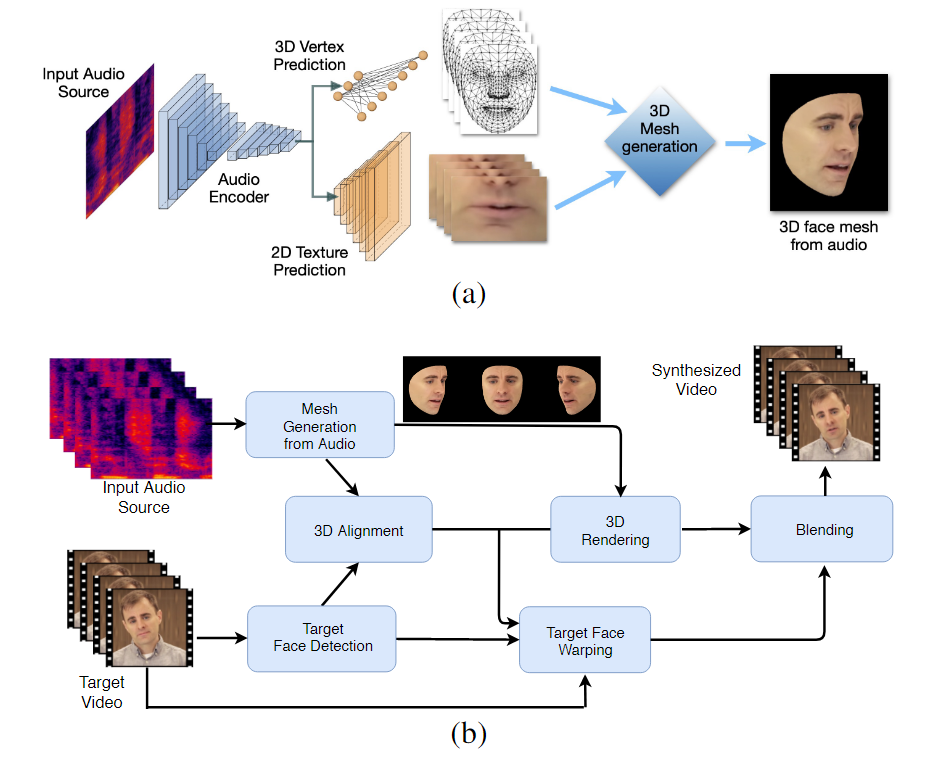
Rrjedha e punës me dy faza të LipSync3D. Më sipër, gjenerimi i një fytyre 3D me teksturë dinamike nga audio 'objektiv'; më poshtë, futja e rrjetës së krijuar në një video të synuar.
Në fakt, kontributi më i dukshëm i LipSync3D në trupin e përpjekjeve kërkimore në këtë fushë mund të jetë algoritmi i tij i normalizimit të ndriçimit, i cili shkëput trajnimin dhe ndriçimin e konkluzioneve.

Shkëputja e të dhënave të ndriçimit nga gjeometria e përgjithshme ndihmon LipSync3D të prodhojë dalje më realiste të lëvizjes së buzëve në kushte sfiduese. Qasje të tjera të viteve të fundit janë kufizuar në kushte ndriçimi 'fikse' që nuk do të zbulojnë kapacitetin e tyre më të kufizuar në këtë drejtim.
Gjatë përpunimit paraprak të kornizave të të dhënave hyrëse, sistemi duhet të identifikojë dhe të heqë pikat spekulare, pasi këto janë specifike për kushtet e ndriçimit në të cilat është realizuar videoja dhe përndryshe do të ndërhyjnë në procesin e rindizimit.

LipSync3D, siç sugjeron emri i tij, nuk po kryen thjesht analiza pixel në fytyrat që vlerëson, por përdor në mënyrë aktive pika referimi të identifikuara të fytyrës për të gjeneruar rrjeta lëvizëse të stilit CGI, së bashku me teksturat 'të shpalosura' që janë mbështjellë rreth tyre në një CGI tradicionale. tubacioni.

Normalizimi i pozës në LipSync3D. Në të majtë janë kornizat hyrëse dhe veçoritë e zbuluara; në mes, kulmet e normalizuara të vlerësimit të rrjetës së gjeneruar; dhe në të djathtë, atlasi përkatës i teksturës, i cili siguron të vërtetën bazë për parashikimin e teksturës. Burimi: https://arxiv.org/pdf/2106.04185.pdf
Përveç metodës së re të ndriçimit, studiuesit pohojnë se LipSync3D ofron tre risi kryesore në punën e mëparshme: ndarjen e gjeometrisë, ndriçimit, pozës dhe teksturës në rrjedha diskrete të të dhënave në një hapësirë të normalizuar; një model parashikimi teksture auto-regresive lehtësisht i trajnueshëm që prodhon sintezë video të qëndrueshme përkohësisht; dhe rritja e realizmit, siç vlerësohet nga vlerësimet njerëzore dhe metrikat objektive.

Ndarja e aspekteve të ndryshme të imazheve të fytyrës video lejon kontroll më të madh në sintezën e videos.
LipSync3D mund të nxjerrë lëvizjen e duhur të gjeometrisë së buzëve drejtpërdrejt nga audio duke analizuar fonema dhe aspekte të tjera të të folurit dhe duke i përkthyer ato në poza të njohura përkatëse të muskujve rreth zonës së gojës.

Ky proces përdor një tubacion parashikues të përbashkët, ku gjeometria dhe tekstura e konkluduar kanë kodues të dedikuar në një konfigurim autoenkoder, por ndajnë një kodues audio me fjalimin që synohet të imponohet në model:

Sinteza e lëvizjes labile të LipSync3D synon gjithashtu të fuqizojë avatarët e stilizuar CGI, të cilët në fakt janë vetëm i njëjti lloj informacioni i rrjetës dhe teksturës si imazhet e botës reale:
Një avatar 3D i stilizuar ka lëvizjet e buzëve të fuqizuara në kohë reale nga një video e altoparlantit burimor. Në një skenar të tillë, rezultatet më të mira do të arriheshin nga para-trajnimi i personalizuar.
Studiuesit gjithashtu parashikojnë përdorimin e avatarëve me një ndjenjë pak më realiste:
![]()
Kohët e mostrës së trajnimit për videot variojnë nga 3-5 orë për një video 2-5 minuta, në një linjë që përdor TensorFlow, Python dhe C++ në një GeForce GTX 1080. Seancat e trajnimit përdorën një madhësi grupi prej 128 kornizash mbi 500-1000 epoka, ku çdo epokë përfaqëson një vlerësim të plotë të videos.

Drejt risinkronizimit dinamik të lëvizjes së buzëve
Fusha e risinkronizimit të buzëve për të akomoduar një pjesë të re audio ka marrë një vëmendje të madhe në kërkimin e vizionit kompjuterik në vitet e fundit (shih më poshtë), jo më pak pasi është një nënprodukt i diskutueshëm teknologji deepfake.
Në 2017 Universiteti i Uashingtonit prezantoi hulumtimin të aftë për të mësuar sinkronizimin e buzëve nga audio, duke e përdorur atë për të ndryshuar lëvizjet e buzëve të presidentit të atëhershëm Obama. Në vitin 2018; i udhëhequr nga Instituti Max Planck për Informatikë një nismë tjetër kërkimore për të mundësuar transferimin e videove të identitetit>identitetit, me sinkronizimin e buzëve a nënprodukt i procesit; dhe në maj të vitit 2021 startupi i AI FlawlessAI zbuloi teknologjinë e tij të pronarit të sinkronizimit të buzëve TrueSync, gjerësisht marrë në shtyp si një mundësues i teknologjive të përmirësuara të dublimit për publikimet kryesore të filmave nëpër gjuhë.
Dhe, sigurisht, zhvillimi i vazhdueshëm i depove me burim të hapur "deepfake" ofron një degë tjetër të kërkimit aktiv të kontribuar nga përdoruesit në këtë sferë të sintezës së imazhit të fytyrës.















