
Inteligjenca artificiale
Gjuha e krijuar nga AI po fillon të ndotë literaturën shkencore

Studiuesit nga Franca dhe Rusia kanë publikuar një studim që tregon se përdorimi i gjeneratorëve probabilist të tekstit të drejtuar nga AI si GPT-3 po prezanton 'gjuhën e torturuar', citimet e literaturës joekzistente dhe ripërdorimin ad hoc, të pakredituar të imazheve në kanale të respektuara më parë për botimi i literaturës së re shkencore.
Ndoshta më shqetësuesja është se punimet e studiuara përmbajnë gjithashtu përmbajtje shkencore të pasakta ose jo të riprodhueshme të paraqitura si fryt i kërkimit objektiv dhe sistematik, që tregon se modelet gjeneruese të gjuhës po përdoren jo vetëm për të forcuar aftësitë e kufizuara në anglisht të autorëve të punimeve. por në fakt për të bërë punën e vështirë të përfshirë (dhe, pa ndryshim, për ta bërë atë keq).
La raportojnë, me titull Fraza të torturuara: Një stil i dyshimtë i të shkruarit që shfaqet në shkencë, është përpiluar nga studiues nga Departamenti i Shkencave Kompjuterike në Universitetin e Toulouse dhe studiuesi i Yandex Alexander Magazinov, aktualisht në Universitetin e Tel Avivit.
Studimi fokusohet veçanërisht në rritjen e botimeve shkencore të pakuptimta të gjeneruara nga AI në Elsevier Journal Mikroprocesorët dhe mikrosistemet.
Me çdo emër tjetër
Modelet e gjuhës autoregresive si GPT-3 janë trajnuar me vëllime të larta të dhënash dhe janë krijuar për të parafrazuar, përmbledhur, renditur dhe interpretuar ato të dhëna kontribuuese në modele gjuhësore gjeneruese kohezive që janë të afta të riprodhojnë modele natyrore të të folurit dhe shkrimit, duke ruajtur origjinalin. synimi i të dhënave të trajnimit.
Meqenëse korniza të tilla shpesh ndëshkohen në fazën e trajnimit të modelit për ofrimin e regurgitimit të drejtpërdrejtë dhe 'të paabsorbuar' të të dhënave origjinale, ato në mënyrë të pashmangshme kërkojnë sinonime – madje edhe për fraza të mirëpërcaktuara.
Parashtresat shkencore të krijuara/ndihmuara nga AI, të zbuluara nga studiuesit, përfshijnë një numër të jashtëzakonshëm përpjekjesh të dështuara për sinonime krijuese për frazat e njohura në sektorin e mësimit të makinerive:
rrjeti nervor i thellë: 'organizim i thellë nervor'
rrjet nervor artificialk: 'organizatë nervore (e rreme | e falsifikuar)'
Rrjeti celular: 'organizim i gjithanshëm'
sulm në rrjet: 'organizim (pritë | sulm)'
lidhje rrjeti: 'shoqata e organizates'
të dhëna të mëdha: 'informacion (i madh | i madh | i madh | kolosal)'
depo e te dhenave: 'informacion (magazina | qendra e shpërndarjes)'
inteligjenca artificiale (AI): 'ndërgjegje (të falsifikuara | e krijuar nga njeriu)'
llogaritje me performancë të lartë: 'përfytyrimi i elitës'
mjegull/mjegull/ informatikë në re: 'përfytyrimi i mjegullës'
Njësia e përpunimit të grafikës (GPU): "njësia e përgatitjes së dizajnit"
njësia qendrore e përpunimit (CPU): 'njësia e përgatitjes fokale'
motori i rrjedhës së punës: "motor i procesit të punës"
njohja e fytyrës: 'pranim i fytyrës'
njohja e zërit: 'mirënjohje ligjërimi'
gabimi mesatar katror: 'katror mesatar (gabim | gabim)'
gabim do të thotë absolut: 'mesatar (i plotë | suprem) (gabim | gabim)'
sinjal ndaj zhurmës: "(lëvizje | flamur | tregues | shenjë | sinjal) në (bujë | zhurmë | zhurmë)
Parametrat globale: 'parametrat në mbarë botën'
qasje e rastësishme: '(arbitrare | e parregullt) merrni të drejtën e kalimit në'
pyll i rastësishëm: "(arbitrare | e parregullt) (pyje të pasme | tokë druri | territor i harlisur)"
vlera e rastësishme: 'vlerësim (arbitrar | i parregullt)'
kolonia e milingonave: 'insekt nëntokësor (shtet | krahinë | zonë | rajon | vendbanim)'
kolonia e milingonave: "nëntokësore kacavjerrëse rrëqethëse (shtet | krahinë | zonë | rajon | vendbanim)'
energjia e mbetur: 'vitalitet i mbetur'
energjia kinetike: "vitaliteti motorik"
Bayes naiv: "(i besueshëm | i pafajshëm | sylesh) Bayes"
asistent personal dixhital (PDA): 'bashkëpunëtor individual i kompjuterizuar'
Në maj të vitit 2021, studiuesit e pyetën përmasat motor kërkimi akademik në kërkim të këtij lloji të gjuhës së ngatërruar, të automatizuar, duke u kujdesur për të përjashtuar frazat legjitime si 'informacion i madh' (e cila është një frazë e vlefshme dhe jo një sinonim i dështuar për 'të dhëna të mëdha'). Në këtë pikë ata vërejtën se Mikroprocesorët dhe mikrosistemet kishte numrin më të madh të dukurive të parafrazimit të keqtrajtuar.
Për momentin, është ende e mundur rifitoj (fotografi e arkivit, 15/07/2021) një numër punimesh shkencore për frazën e pakuptimtë 'organizim i thellë nervor' (dmth. 'rrjet nervor i thellë'), dhe të tjera në listën e mësipërme japin suksese të ngjashme.
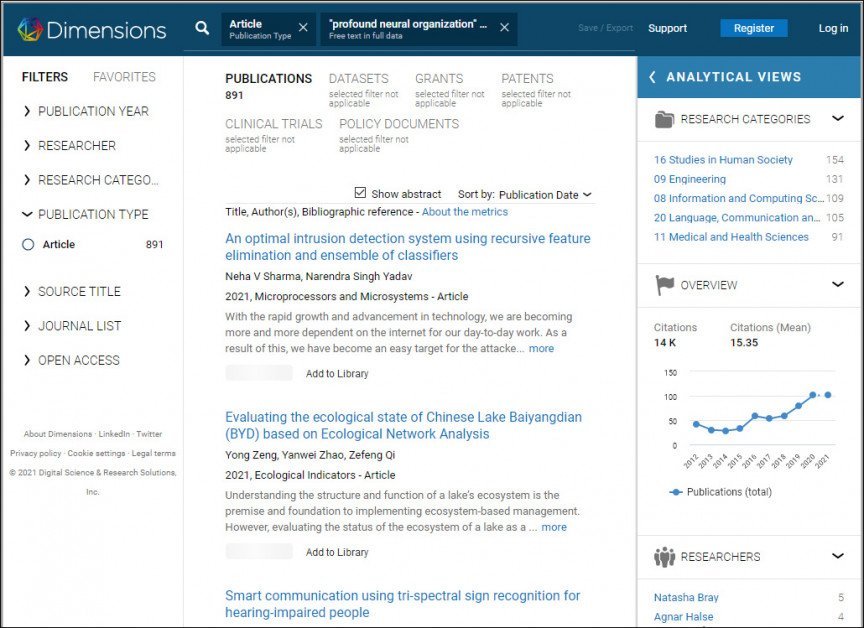
Rezultatet e kërkimit për 'organizim të thellë nervor' ('rrjet nervor i thellë') në Dimensions. Burimi: https://app.dimensions.ai/
La Mikroprocesorët revista u themelua në vitin 1976 dhe u riemërua në Mikroprocesorët dhe mikrosistemet dy vjet më vonë.
Një rritje e gjuhës së pakuptimtë
Studiuesit studiuan një periudhë që përfshinte shkurtin 2018 deri në qershor të 2021 dhe vunë re një rritje të madhe të vëllimit të paraqitjeve gjatë dy viteve të fundit, dhe veçanërisht gjatë 6-8 muajve të fundit:
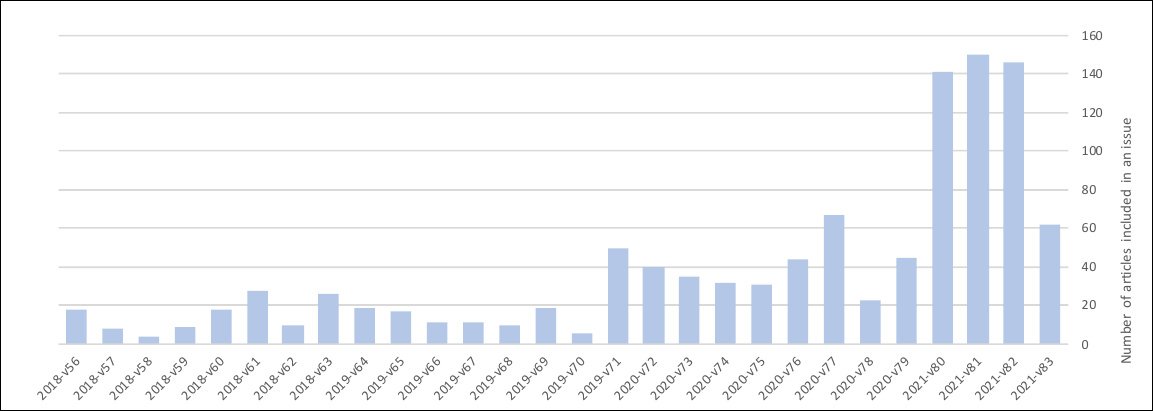
Korrelacion apo shkakësi? Rritja e dërgesave në revistën Microprocessors and Microsystems duket se përkon me rritjen e teksteve "të pakuptimta" dhe sinonimeve në paraqitjet në dukje të respektueshme. Burimi: https://arxiv.org/pdf/2107.06751.pdf
Të dhënat përfundimtare të mbledhura nga bashkëpunëtorët përmban 1,078 artikuj me gjatësi të plotë të marrë nëpërmjet abonimit Elsevier të Universitetit të Toulouse.
Zvogëlimi i mbikëqyrjes editoriale për punimet shkencore kineze
Gazeta vëren se periudha kohore e caktuar për vlerësimin editorial të paraqitjeve të shënuara shkurtohet rrënjësisht në vitin 2021, duke rënë nën 40 ditë; një rënie gjashtëfish në kohën standarde për rishikim nga kolegët, e dukshme nga shkurti i vitit 2021.
Numri më i madh i letrave të shënuara vjen nga autorë me përkatësi të Kinës kontinentale: nga 404 letra të pranuara në më pak se 30 ditë, 97.5% janë të lidhura me Kinën. Anasjelltas, në rastet kur procesi editorial i kaloi 40 ditë (615 letra), paraqitjet e lidhura me Kinën përfaqësonin vetëm 9.5% të asaj kategorie - një çekuilibër dhjetëfish.
Raporti ia atribuon infiltrimin e gazetave të shënuara me mangësitë në procesin editorial dhe mungesën e mundshme të burimeve përballë një numri në rritje të parashtresave.
Studiuesit supozojnë se modelet gjeneruese të stilit GPT, dhe lloje të ngjashme të kornizave të gjenerimit të gjuhës, janë përdorur për të prodhuar një pjesë të madhe të tekstit në letrat e shënuara; megjithatë, mënyra se si një model gjenerues abstrakton burimet e tij e bën këtë të vështirë për t'u vërtetuar dhe prova kryesore qëndron në një vlerësim me sens të përbashkët të sinonimeve të dobëta dhe të panevojshme dhe një ekzaminim të përpiktë të koherencës logjike të parashtresës.
Studiuesit vërejnë më tej se modelet e gjuhës gjeneruese për të cilat ata besojnë se po kontribuojnë në këtë vërshim marrëzish janë në gjendje jo vetëm të krijojnë tekste problematike, por edhe t'i njohin ato dhe t'i shënjojnë ato në mënyrë sistematike, në të njëjtën mënyrë që kanë kryer vetë studiuesit. me dorë. Puna detajon një zbatim të tillë, duke përdorur GPT-2, dhe ofron një kornizë për sistemet e ardhshme për të identifikuar paraqitjet problematike shkencore.
Incidenca e paraqitjeve 'të ndotura' është shumë më e lartë në revistën Elsevier (72.1%) krahasuar me revistat e tjera të studiuara (maksimumi 13.6%).
Jo vetëm Semantikë
Studiuesit theksojnë se shumë nga revistat në fjalë nuk përdorin thjesht gjuhën e gabuar, por përmbajnë pohime të pasakta shkencërisht, duke treguar mundësinë që modelet e gjuhës gjeneruese të mos përdoren vetëm për të përmirësuar aftësitë e kufizuara gjuhësore të shkencëtarëve kontribues, por në fakt mund të jenë duke u përdorur për të formuluar të paktën disa nga teoremat dhe të dhënat thelbësore në punim.
Në raste të tjera, studiuesit parashtrojnë një 'risintezë' ose 'tjerr' efektive të punës së mëparshme të abstraktuar (dhe superiore), me qëllim që të përballen me presionet e kulturave kërkimore akademike 'publikoni ose zhdukni', dhe ndoshta për të përmirësuar renditjen kombëtare për para eminenca në kërkimin e AI, përmes vëllimit të madh.

Përmbajtje e pakuptimtë në një punim të dorëzuar. Në këtë rast, studiuesit zbuluan se teksti është nxjerrë, ad hoc, nga një artikull EDN, nga ku është grabitur edhe ilustrimi shoqërues pa atribut. Rishkrimi i përmbajtjes origjinale është aq ekstrem sa e bën atë të pakuptimtë.
Duke analizuar disa nga letrat e dorëzuara të Elsevier, studiuesit gjetën fjali për të cilat nuk arritën të nxirrnin ndonjë kuptim; referenca për literaturë që nuk ekziston; referenca ndaj variablave dhe teoremave në formula që në fakt nuk u shfaqën në materialin mbështetës (duke sugjeruar abstraksion të bazuar në gjuhë, ose 'halucinacion' e të dhënave në dukje faktike); dhe ripërdorimin e imazheve pa njohje të burimeve të tyre (të cilat studiuesit i kritikojnë jo nga pikëpamja e të drejtës së autorit, por më tepër si një tregues i ashpërsisë së pamjaftueshme shkencore).
Dështimet e citimit
Citimet që synonin të mbështesnin argumentet në një punim shkencor u gjetën në shumë nga shembujt e shënuar si 'ose të prishura ose të çonin në botime të palidhura'.
Për më tepër, referencat për 'punën e lidhur' me sa duket shpesh përfshijnë autorë që studiuesit besojnë se janë 'halucinuar' nga një sistem i stilit GPT.
Vëmendje endacake
Një mangësi tjetër edhe e modeleve gjuhësore më të avancuara si GPT-3 është tendenca e tyre për të humbur fokusin gjatë një diskursi të gjatë. Studiuesit zbuluan se letrat e shënuara shpesh sjellin një temë në fillim të gazetës, e cila në fakt nuk kthehet më kurrë pasi të jetë hapur fillimisht në shënimet paraprake ose diku tjetër.
Ata gjithashtu teorizojnë se disa nga shembujt më të këqij ndodhin përmes udhëtimeve të shumta të tekstit burimor përmes një serie motorësh përkthimi, ku secili e shtrembëron më tej kuptimin.
Burimet dhe arsyet
Në përpjekje për të dalluar se çfarë qëndron pas këtij fenomeni, autorët e punimit sugjerojnë një sërë mundësish: që përmbajtja nga fabrika letre po përdoren si material burimor, duke futur pasaktësi shumë herët në një proces që në mënyrë të pashmangshme do të prodhojë pasaktësi të mëtejshme; se mjetet e tjerrjes së artikujve si Spinbot po përdoren për të maskuar plagjiaturën; dhe se presioni dërrmues për të botuar rregullisht po i shtyn studiuesit me burime të pamjaftueshme të përdorin sisteme të stilit GPT-3 ose për të shtuar ose për të gjeneruar tërësisht punime të reja akademike.
Studiuesit mbyllen me një thirrje për veprim për mbikëqyrje më të madhe dhe standarde të përmirësuara në një fushë të botimit akademik, e cila po provon, me sa duket, të bëhet ushqim për lëndën e saj - sistemet e mësimit të makinerive. Ata gjithashtu kërkojnë Elsevier dhe botues të tjerë të prezantojnë procedura më rigoroze të shqyrtimit dhe rishikimit, dhe të kritikojnë gjerësisht standardet dhe praktikat aktuale në këtë drejtim, duke sugjeruar që 'Mashtrimi me tekste sintetike kërcënon integritetin e literaturës shkencore.'















