Inteligență artificială
Spre Oameni AI în Timp Real Cu Rendarea Neurală Lumigraph

În ciuda valului actual de interes pentru Neural Radiance Fields (NeRF), o tehnologie capabilă să creeze medii și obiecte 3D generate de inteligență artificială, această nouă abordare a tehnologiei de sinteză a imaginilor încă necesită mult timp de antrenament și lipsește o implementare care să permită interfețe în timp real, foarte receptive.
Cu toate acestea, o colaborare între câteva nume impresionante din industrie și academia oferă o nouă abordare a acestei provocări (cunoscută generic sub numele de Sinteză de Vederi Noi, sau NVS).
Cercetarea articolului, intitulat Rendarea Neurală Lumigraph, afirmă o îmbunătățire a stadiului actual al tehnologiei cu aproximativ două ordine de mărime, reprezentând câteva pași spre renderarea în timp real a graficii computerizate prin intermediul conductelor de învățare automată.

Rendarea Neurală Lumigraph (dreapta) oferă o rezoluție mai bună a artefactelor de amestec și o gestionare îmbunătățită a ocluziunii față de metodele anterioare. Sursă.
Deși creditele pentru articolul menționat citează doar Universitatea Stanford și compania de tehnologie de afișare holografică Raxium (care operează în prezent în mod stealth), contributorii includ un arhitect principal de învățare automată la Google, un om de știință computerizat la Adobe și directorul tehnic la StoryFile (care a făcut știri recent cu o versiune AI a lui William Shatner).
În ceea ce privește recenta campanie de publicitate Shatner, StoryFile pare să utilizeze NLR în noul său proces de creare a entităților interactive generate de inteligență artificială, bazate pe caracteristicile și narativele individuale ale oamenilor.
StoryFile își imaginează utilizarea acestei tehnologii în expoziții de muzeu, narative interactive online, afișaje holografice, realitate augmentată (AR) și documentare patrimonială – și pare să vadă, de asemenea, aplicații potențiale noi ale NLR în interviuri de recrutare și aplicații de întâlniri virtuale:

Utilizări propuse dintr-un videoclip online de la StoryFile. Sursă: https://www.youtube.com/watch?v=2K9J6q5DqRc
Captură Volumetrică Pentru Interfețe De Sinteză De Vederi Noi Și Video
Principiul capturii volumetrice, de-a lungul gamei de articole care se adună pe această temă, este ideea de a lua imagini statice sau videoclipuri ale unui subiect și de a utiliza învățarea automată pentru a “umple” punctele de vedere care nu au fost acoperite de matricea originală de camere.
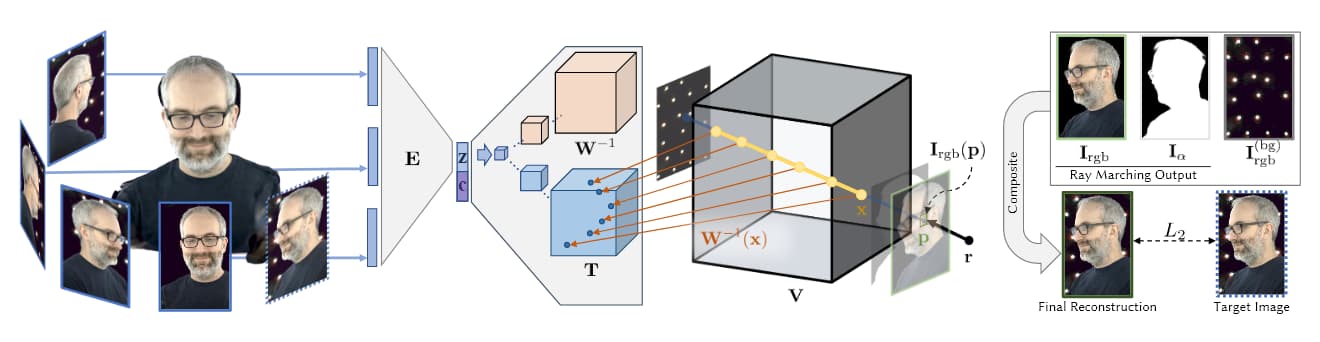
Sursă: https://research.fb.com/wp-content/uploads/2019/06/Neural-Volumes-Learning-Dynamic-Renderable-Volumes-from-Images.pdf
În imaginea de mai sus, preluată din cercetarea AI a Facebook din 2019 (a se vedea mai jos), vedem cele patru etape ale capturii volumetrice: multiple camere obțin imagini/videoclipuri; arhitectura encoder/decoder (sau alte arhitecturi) calculează și concatenează relația dintre vederi; algoritmii de marșare a razelor calculează voxelii (sau alte unități geometrice spațiale XYZ) ale fiecărui punct din spațiul volumetric; și (în cele mai recente articole) se realizează antrenament pentru a sintetiza o entitate completă care poate fi manipulată în timp real.
Este această fază de antrenament, adesea extinsă și încărcată cu date, care a ținut până acum sinteza de vederi noi în afara domeniului de timp real sau de captură foarte receptivă.
Faptul că sinteza de vederi noi creează o hartă 3D completă a unui spațiu volumetric înseamnă că este relativ trivial să coase aceste puncte împreună într-o rețea computerizată tradițională, capturând și articulând efectiv un om CGI (sau orice alt obiect relativ limitat) pe loc.
Abordările care utilizează NeRF se bazează pe nori de puncte și hărți de adâncime pentru a genera interpolările dintre punctele de vedere rare ale dispozitivelor de captură:

NeRF poate genera adâncime volumetrică prin calculul hărților de adâncime, și nu prin generarea de rețele CGI. Sursă: https://www.youtube.com/watch?v=JuH79E8rdKc
Deși NeRF este capabil să calculeze rețele, majoritatea implementărilor nu utilizează acest lucru pentru a genera scene volumetrice.
În schimb, abordarea Implicit Differentiable Renderer (IDR), publicată de Institutul Weizmann de Știință în octombrie 2020, se bazează pe exploatarea informațiilor despre rețeaua 3D generată automat din matricea de captură:

Exemple de capturi IDR transformate în rețele CGI interactive. Sursă: https://www.youtube.com/watch?v=C55y7RhJ1fE
Deși NeRF lipsește de capacitatea IDR de estimare a formei, IDR nu poate egala calitatea imaginii NeRF, și ambele necesită resurse extinse pentru antrenament și colectare (deși inovațiile recente în NeRF sunt începând să adreseze acest lucru).

Dispozitivul de cameră personalizat NLR, cu 16 camere GoPro HERO7 și 6 camere centrale Back-Bone H7PRO. Pentru renderizarea în timp real, acestea funcționează la o rată minimă de 60fps. Sursă: https://arxiv.org/pdf/2103.11571.pdf
În schimb, Rendarea Neurală Lumigraph utilizează SIREN (Rețele Sinusoidale) pentru a incorpora punctele forte ale fiecărei abordări în propriul său cadru, care este destinat să genereze ieșiri direct utilizabile în conductele grafice în timp real existente.
SIREN a fost utilizat pentru implementări similare de-a lungul anului trecut și reprezintă acum o apel API popular pentru notebook-urile Colab ale entuziaștilor din comunitățile de sinteză a imaginilor; cu toate acestea, inovația NLR constă în aplicarea SIREN-ilor la supravegherea imaginilor bidimensionale cu multiple vederi, ceea ce este problematic din cauza gradului în care SIREN produce ieșiri supraantrenate și nu generalizate.
După ce rețeaua 3D este extrasă din imaginile matricei, rețeaua este rasterizată prin OpenGL, iar pozițiile verticalelor rețelei sunt mapate la pixelii corespunzători, după care se calculează amestecul hărților contributive.
Rețeaua rezultată este mai generalizată și reprezentativă decât cea a NeRF (a se vedea imaginea de mai jos), necesită mai puține calcule și nu aplică detalii excesive în zone (cum ar fi pielea facială netedă) care nu pot beneficia de aceasta:

Sursă: https://arxiv.org/pdf/2103.11571.pdf
Pe partea negativă, NLR nu are încă nicio capacitate pentru iluminare dinamică sau reluminare, și ieșirea este limitată la hărți de umbră și alte considerații de iluminare obținute la momentul capturii. Cercetătorii intenționează să abordeze acest lucru în lucrările viitoare.
În plus, articolul recunoaște că formele generate de NLR nu sunt la fel de precise ca unele abordări alternative, cum ar fi Selectarea Vederii Pixel cu Pixel pentru Stereo Multi-Vederi Neordonate, sau cercetarea Institutului Weizmann menționată mai devreme.
Ascensiunea Sintezei de Imagini Volumetrice
Ideea de a crea entități 3D dintr-o serie limitată de fotografii cu rețele neuronale precede NeRF, cu articole vizionare care datează din 2007 sau mai devreme. În 2019, departamentul de cercetare AI al Facebook a produs un articol de cercetare seminal, Volumetrii Neuronale: Învățarea Volumelor Renderabile Dinamice din Imagini, care a permis pentru prima dată interfețe receptive pentru oameni sintetici generați de captura volumetrică bazată pe învățarea automată.

Cercetarea Facebook din 2019 a permis crearea unei interfețe utilizator receptive pentru o persoană volumetrică. Sursă: https://research.fb.com/publications/neural-volumes-learning-dynamic-renderable-volumes-from-images/












