
Inteligența artificială
Este DALL-E 2 doar „Lipirea lucrurilor împreună” fără a le înțelege relațiile?

O nouă lucrare de cercetare de la Universitatea Harvard sugerează că cadrul OpenAI DALL-E 2, care captează titlul text-to-image, are dificultăți notabile în a reproduce chiar și relațiile la nivel infantil între elementele pe care le compune în fotografii sintetizate, în ciuda sofisticarii uimitoare a multor dintre ieșirea acestuia.
Cercetătorii au întreprins un studiu asupra utilizatorilor care a implicat 169 de participanți crowdsourcing, cărora li s-au prezentat imagini DALL-E 2 bazate pe cele mai de bază principii umane ale semanticii relațiilor, împreună cu mesajele text care le-au creat. Când a fost întrebat dacă solicitările și imaginile au fost legate, mai puțin de 22% dintre imagini au fost percepute ca fiind pertinente pentru solicitările lor asociate, în ceea ce privește relațiile foarte simple pe care DALL-E 2 a fost rugat să le vizualizeze.

O captură de ecran din studiile efectuate pentru noua lucrare. Participanții au fost însărcinați să selecteze toate imaginile care se potriveau cu solicitarea. În ciuda declinului de responsabilitate din partea de jos a interfeței, în toate cazurile imaginile, fără ca participanții să știe, au fost de fapt generate din promptul asociat afișat. Sursă: https://arxiv.org/pdf/2208.00005.pdf
Rezultatele sugerează, de asemenea, că capacitatea aparentă a lui DALL-E de a combina elemente disparate poate scădea pe măsură ce aceste elemente devin mai puțin probabil să se fi produs în datele de antrenament din lumea reală care alimentează sistemul.
De exemplu, imaginile pentru promptul „copil care atinge un castron” au obținut o rată de acord de 87% (adică participanții au făcut clic pe majoritatea imaginilor ca fiind relevante pentru prompt), în timp ce redări similare fotorealiste ale „o maimuță care atinge o iguană” au fost realizate. doar 11% acord:


DALL-E se străduiește să descrie evenimentul improbabil al unei „maimuțe care atinge o iguană”, probabil pentru că este neobișnuit, mai probabil inexistent, în setul de antrenament.
În cel de-al doilea exemplu, DALL-E 2 greșește frecvent scara și chiar specia, probabil din cauza lipsei de imagini din lumea reală care descriu acest eveniment. În schimb, este rezonabil să ne așteptăm la un număr mare de fotografii de antrenament legate de copii și mâncare și că acest subdomeniu/clasă este bine dezvoltat.
Dificultatea lui DALL-E de a juxtapune elemente de imagine extrem de contrastante sugerează că publicul este în prezent atât de uimit de capacitățile fotorealiste și interpretative ale sistemului, încât să nu fi dezvoltat un ochi critic pentru cazurile în care sistemul a „lipit” efectiv un element de altul. , ca în aceste exemple de pe site-ul oficial DALL-E 2:

Sinteză „cut-and-paste”, din exemplele oficiale pentru DALL-E 2. Sursa: https://openai.com/dall-e-2/
Noua lucrare precizează*:
„Înțelegerea relațională este o componentă fundamentală a inteligenței umane, care se manifestă timpuriu în dezvoltareși este calculat rapid și automat în percepție.
Dificultatea lui DALL-E 2 chiar și cu relațiile spațiale de bază (cum ar fi in, on, în) sugerează că orice a învățat, nu a învățat încă tipurile de reprezentări care permit oamenilor să structureze atât de flexibil și robust lumea.
„O interpretare directă a acestei dificultăți este că sisteme precum DALL-E 2 nu au încă o compoziționalitate relațională”.
Autorii sugerează că sistemele de generare a imaginilor ghidate de text, cum ar fi seria DALL-E, ar putea beneficia de pe urma utilizării algoritmilor comuni roboticii, care modelează identitățile și relațiile simultan, datorită necesității ca agentul să interacționeze efectiv cu mediul, mai degrabă decât să fabrice. un amestec de elemente diverse.
O astfel de abordare, intitulată CLIPort, folosește la fel mecanism CLIP care servește ca element de evaluare a calității în DALL-E 2:
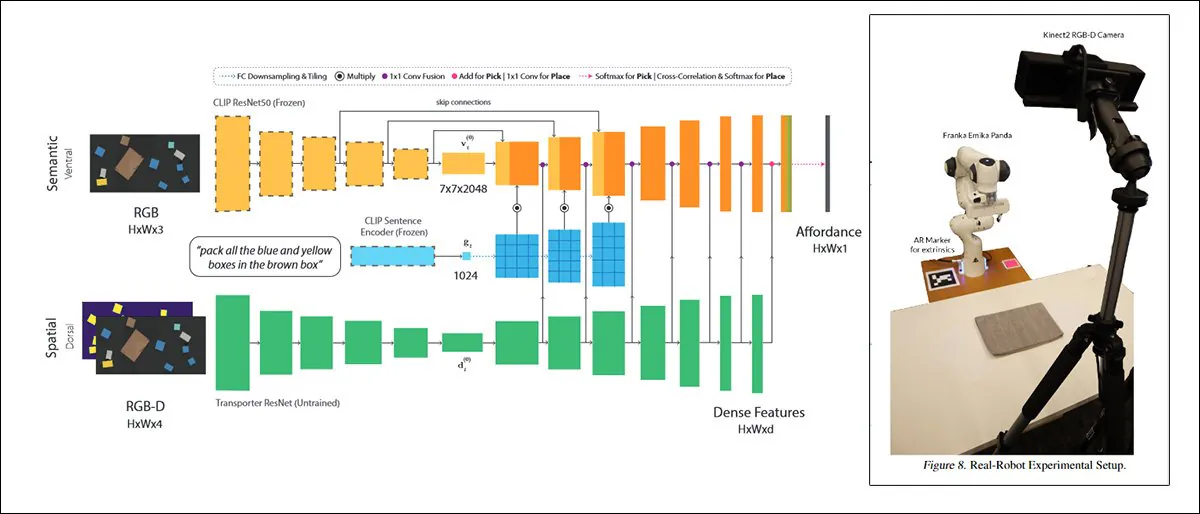
CLIPort, o colaborare din 2021 între Universitatea din Washington și NVIDIA, folosește CLIP într-un context atât de practic încât sistemele instruite pe acesta trebuie neapărat să dezvolte o înțelegere a relațiilor fizice, un motivator care este absent în DALL-E 2 și similar „fantastic” cadre de sinteză a imaginilor. Sursă: https://arxiv.org/pdf/2109.12098.pdf
Autorii mai sugerează că „o altă actualizare plauzibilă” ar putea fi ca arhitectura sistemelor de sinteză a imaginilor, cum ar fi DALL-E, să incorporeze efecte multiplicative într-un singur strat de calcul, permițând calcularea relațiilor într-o manieră inspirată de capacitățile de procesare a informațiilor ale biologic sisteme.
hârtie nouă se intitulează Testarea înțelegerii relaționale în generarea de imagini ghidată de text, și vine de la Colin Conwell și Tomer D. Ullman de la Departamentul de Psihologie de la Harvard.
Dincolo de criticile timpurii
Comentând despre „delectarea mâinii” din spatele realismului și integrității producției DALL-E 2, autorii notează lucrările anterioare care au găsit deficiențe în sistemele de imagini generative în stil DALL-E.
În iunie anul acesta, UoC Berkeley notat dificultatea pe care DALL-E o are în gestionarea reflexiilor și umbrelor; în aceeași lună, un studiu din Coreea a investigat „unicitatea” și originalitatea producției în stil DALL-E 2 cu ochiul critic; la analiza preliminara a imaginilor DALL-E 2, la scurt timp după lansare, de la NYU și Universitatea din Texas, au găsit diverse probleme de compoziție și alți factori esențiali în imaginile DALL-E 2; si luna trecuta, o lucrare comună între Universitatea din Illinois și MIT au oferit sugestii pentru îmbunătățiri arhitecturale aduse unor astfel de sisteme în ceea ce privește compoziția.
Cercetătorii mai notează că luminarii DALL-E, cum ar fi Aditya Ramesh, au a recunoscut problemele cadrului cu caracter obligatoriu, dimensiunea relativă, textul și alte provocări.
Dezvoltatorii din spatele sistemului de sinteză a imaginilor rival al Google, Imagen au propus și ei DrawBench, un nou sistem de comparare care măsoară acuratețea imaginii în cadrul cadrelor cu diverse valori.
În schimb, autorii noii lucrări sugerează că s-ar putea obține un rezultat mai bun prin confruntarea estimărilor umane - mai degrabă decât a unor metrici algoritmice interne - cu imaginile rezultate, pentru a stabili unde se află punctele slabe și ce s-ar putea face pentru a le atenua.
Studiul
În acest scop, noul proiect își bazează abordarea pe principii psihologice și încearcă să se retragă de la actualul creșterea interesului in inginerie promptă (care este, de fapt, o concesie față de deficiențele DALL-E 2 sau ale oricărui sistem comparabil), pentru a investiga și eventual a aborda limitările care fac necesare astfel de „soluții de soluționare”.
Lucrarea afirmă:
„Lucrarea actuală se concentrează pe un set de 15 relații de bază descrise, examinate sau propuse anterior în literatura cognitivă, de dezvoltare sau lingvistică. Setul conține atât relații spațiale fundamentate (de exemplu, „X pe Y”), cât și relații agentice mai abstracte (de exemplu, „X îl ajută pe Y”).
„Indicațiile sunt în mod intenționat simple, fără complexitate sau elaborare a atributelor. Adică, în loc de un prompt ca „un măgar și o caracatiță joacă un joc. Măgarul ține o frânghie la un capăt, caracatița ține de celălalt. Măgarul ține frânghia în gură. O pisică sare peste frânghie”, folosim „o cutie pe cuțit”.
„Simplitatea încă surprinde o gamă largă de relații din diferite subdomenii ale psihologiei umane și face posibilele eșecuri ale modelului mai izbitoare și mai specifice.”
Pentru studiul lor, autorii au recrutat 169 de participanți de la Prolific, toți aflați în SUA, cu o vârstă medie de 33 de ani și 59% femei.
Participanților li s-au arătat 18 imagini organizate într-o grilă de 3×6 cu promptul în partea de sus și o declarație de declinare a răspunderii în partea de jos care afirmă că toate, unele sau niciuna dintre imaginile ar fi putut fi generate din promptul afișat și apoi li sa cerut să selectați imaginile despre care credeau că sunt legate în acest fel.
Imaginile prezentate indivizilor s-au bazat pe literatura lingvistică, de dezvoltare și cognitivă, cuprinzând un set de opt relații fizice și șapte „agentice” (acest lucru va deveni clar într-un moment).
Relații fizice
în, pe, dedesubt, acoperind, aproape, ascuns de, atârnând peste, și legat de.
Relații Agentice
împingerea, tragerea, atingerea, lovirea, piciorul, ajutarea, și împiedicarea.
Toate aceste relații au fost extrase din domeniile de studiu non-CS menționate anterior.
Au fost astfel derivate douăsprezece entități pentru utilizare în prompturi, cu șase obiecte și șase agenți:
Obiecte
cutie, cilindru, pătură, castron, ceașcă de ceai, și cuţit.
Agenți
bărbat, femeie, copil, robot, maimuță, și iguană.
(Cercetătorii admit că includerea iguanei, nu un pilon al cercetării sociologice sau psihologice uscate, a fost „un răsfăț”).
Pentru fiecare relație, au fost create cinci prompturi diferite prin eșantionarea aleatorie a două entități de cinci ori, rezultând un total de 75 de prompturi, fiecare dintre ele trimise la DALL-E 2 și pentru fiecare dintre acestea au fost utilizate cele 18 imagini furnizate inițiale, fără variații. sau a doua șansă permisă.
REZULTATE
Lucrarea precizează*:
„Participanții au raportat, în medie, un nivel scăzut de acord între imaginile DALL-E 2 și solicitările utilizate pentru a le genera, cu o medie de 22.2% [18.3, 26.6] pentru cele 75 de solicitări distincte.
„Promptările agentice, cu o medie de 28.4% [22.8, 34.2] pentru 35 de solicitări, au generat un acord mai mare decât solicitările fizice, cu o medie de 16.9% [11.9, 23.0] pentru 40 de solicitări”.

Rezultatele studiului. Punctele în negru denotă toate solicitările, fiecare punct fiind un prompt individual, iar culoarea se descompune în funcție de faptul dacă subiectul prompt era agent sau fizic (adică un obiect).
Pentru a compara diferența dintre percepția umană și cea algoritmică a imaginilor, cercetătorii și-au rulat randările prin sursa deschisă OpenAI. ViT-L/14 Cadru bazat pe CLIP. Făcând o medie a scorurilor, ei au găsit o „relație moderată” între cele două seturi de rezultate, ceea ce este poate surprinzător, având în vedere măsura în care CLIP însuși ajută la generarea imaginilor.

Rezultatele comparației CLIP (ViT-L/14) față de răspunsurile umane.
Cercetătorii sugerează că alte mecanisme din arhitectură, poate combinate cu o preponderență întâmplătoare (sau lipsă) de date din setul de antrenament, pot explica modul în care CLIP poate recunoaște limitările DALL-E fără a fi capabil, în toate cazurile, să facă nimic. multe despre problema.
Autorii concluzionează că DALL-E 2 are doar o facilitate noțională, dacă există, de a reproduce imagini care încorporează înțelegerea relațională, o fațetă fundamentală a inteligenței umane care se dezvoltă în noi foarte devreme.
„Ideea că sisteme precum DALL-E 2 nu au compoziție poate fi o surpriză pentru oricine care a văzut răspunsurile uimitor de rezonabile ale lui DALL-E 2 la solicitări precum „un desen animat cu un pui de ridiche daikon într-o fustă de balet care plimbă un pudel”. Astfel de indicații generează adesea o aproximare sensibilă a unui concept compozițional, cu toate părțile prompturilor prezente și prezente în locurile potrivite.
„Compoziționalitatea, totuși, nu este doar capacitatea de a lipi lucrurile împreună – chiar și lucruri pe care poate nu le-ați observat niciodată împreună înainte. Compoziționalitatea necesită o înțelegere a norme care leagă lucrurile împreună. Relațiile sunt astfel de reguli.
Un bărbat mușcă T-Rex
Opinie Pe măsură ce OpenAI îmbrățișează un număr mai mare de utilizatori după recenta sa monetizare beta a DALL-E 2 și din moment ce acum trebuie să plătească pentru majoritatea generațiilor, deficiențele în înțelegerea relațională a lui DALL-E 2 pot deveni mai evidente, deoarece fiecare încercare „eșuată” are o greutate financiară, iar rambursările nu sunt disponibile.
Aceia dintre noi care au primit o invitație puțin mai devreme au avut timp (și, până de curând, mai mult timp liber să se joace cu sistemul) să observe unele dintre „efectele relaționale” pe care le poate emite DALL-E 2.
De exemplu, pentru un Parcul Jurassic fan, este foarte dificil să faci ca un dinozaur să urmărească o persoană în DALL-E 2, chiar dacă conceptul de „căutare” nu pare să fie în DALL-E 2 sistem de cenzură, și chiar dacă poveste lungă filmele cu dinozauri ar trebui să ofere exemple abundente de antrenament (cel puțin sub formă de remorci și fotografii publicitare) pentru această întâlnire altfel imposibilă a speciilor.

Un răspuns tipic DALL-E 2 la solicitarea „O fotografie color a unui T-Rex urmărind un bărbat pe drum”. Sursa: DALL-E 2
Am descoperit că imaginile de mai sus sunt tipice pentru variații ale „[dinozaur] urmărește [o persoană]” proiectare promptă și că nicio cantitate de elaborare în prompt nu poate determina T-Rex să se conformeze efectiv. În prima și a doua fotografie, bărbatul urmărește (mai mult sau mai puțin) T-Rex; în al treilea, abordând-o cu o neglijenta casuală pentru siguranță; iar în imaginea finală, aparent alergând în paralel cu marea fiară. În aproximativ 10-15 încercări la această temă, am descoperit că dinozaurul este în mod similar „distras”.
S-ar putea ca singurele date de antrenament pe care DALL-E 2 le-ar putea accesa să fie în linie „omul se luptă cu dinozaur”, de la fotografii publicitare pentru filme mai vechi precum Un milion de ani î.Hr (1966) și a lui Jeff Goldblum zbor celebru de la regele prădătorilor este pur și simplu o valoare anormală în acea tranșă mică de date.
* Conversia mea a citărilor inline ale autorilor în hyperlinkuri.
Prima dată publicată pe 4 august 2022.











