Capacitatea de a genera active digitale 3D din promturi de text reprezintă una dintre cele mai interesante evoluții recente în domeniul inteligenței artificiale și al graficii pe calculator. Pe măsură ce piața activelor digitale 3D este prognozată să crească de la $28,3 miliarde în 2024 la $51,8 miliarde până în 2029, modelele de inteligență artificială text-3D sunt pregătite să joace un rol major în revoluționarea creației de conținut în industrii precum jocurile, filmul, comerțul electronic și multe altele. Dar cum funcționează exact aceste sisteme de inteligență artificială? În acest articol, vom face o analiză detaliată a aspectelor tehnice din spatele generării 3D din text.
Provocarea generării 3D
Generarea de active 3D din text este o sarcină semnificativ mai complexă decât generarea de imagini 2D. În timp ce imaginile 2D sunt esențialmente grile de pixeli, activele 3D necesită reprezentarea geometriei, texturilor, materialelor și adesea a animațiilor în spațiu tridimensional. Această dimensiune adițională și complexitate face ca sarcina de generare să fie mult mai dificilă.
Unele dintre provocările cheie în generarea text-3D includ:
Reprezentarea geometriei și structurii 3D
Generarea de texturi și materiale consistente pe suprafața 3D
Asigurarea plauzibilității și coerenței fizice din multiple puncte de vedere
Capturarea detaliilor fine și a structurii globale în același timp
Generarea de active care pot fi ușor renderizate sau imprimate 3D
Pentru a aborda aceste provocări, modelele text-3D folosesc mai multe tehnologii și tehnici cheie.
Componentele cheie ale sistemelor text-3D
Majoritatea sistemelor de generație text-3D de ultimă generație au câteva componente de bază comune:
Encodarea textului: Conversia promptului de text de intrare într-o reprezentare numerică
Reprezentarea 3D: O metodă pentru reprezentarea geometriei și a aspectului 3D
Modelul generativ: Modelul de inteligență artificială de bază pentru generarea activului 3D
Renderizarea: Conversia reprezentării 3D în imagini 2D pentru vizualizare
Să explorăm fiecare dintre acestea în mai multe detalii.
Encodarea textului
Primul pas este conversia promptului de text de intrare într-o reprezentare numerică cu care modelul de inteligență artificială poate lucra. Acest lucru se realizează de obicei folosind modele de limbaj mari precum BERT sau GPT.
Reprezentarea 3D
Există mai multe moduri comune de a reprezenta geometria 3D în modelele de inteligență artificială:
Grile de voxel: Matrice 3D de valori care reprezintă ocuparea sau caracteristicile
Nor de puncte: Seturi de puncte 3D
Rețele: Vârfuri și fețe care definesc o suprafață
Funcții implicite: Funcții continue care definesc o suprafață (de exemplu, funcții de distanță semnată)
Fiecare are compromisuri în ceea ce privește rezoluția, utilizarea memoriei și ușurința generării. Multe modele recente folosesc funcții implicite sau NeRF, deoarece permit rezultate de înaltă calitate cu cerințe computaționale rezonabile.
De exemplu, putem reprezenta o sferă simplă ca o funcție de distanță semnată:
import numpy as np
def sphere_sdf(x, y, z, radius=1.0):
return np.sqrt(x**2 + y**2 + z**2) - radius
# Evaluarea SDF la un punct 3D
point = [0.5, 0.5, 0.5]
distance = sphere_sdf(*point)
print(f"Distanța până la suprafața sferei: {distance}")
Modelul generativ
Nucleul unui sistem text-3D este modelul generativ care produce reprezentarea 3D din încorporarea textului. Majoritatea modelelor de ultimă generație folosesc o variație a unui model de difuzie, similar cu cele utilizate în generarea de imagini 2D.
Modelele de difuzie funcționează prin adăugarea treptată de zgomot la date, apoi prin învățarea inversării acestui proces. Pentru generarea 3D, acest proces are loc în spațiul reprezentării 3D alese.
Un pseudocod simplificat pentru o etapă de antrenare a unui model de difuzie ar putea arăta astfel:
def diffusion_training_step(model, x_0, text_embedding):
# Eșantionarea unui timp de pas aleator
t = torch.randint(0, num_timesteps, (1,))
# Adăugarea de zgomot la intrare
noise = torch.randn_like(x_0)
x_t = add_noise(x_0, noise, t)
# Predictia zgomotului
predicted_noise = model(x_t, t, text_embedding)
# Calculul pierderii
loss = F.mse_loss(noise, predicted_noise)
return loss
# Buclă de antrenare
for batch in dataloader:
x_0, text = batch
text_embedding = encode_text(text)
loss = diffusion_training_step(model, x_0, text_embedding)
loss.backward()
optimizer.step()
În timpul generării, începem de la zgomot pur și iterăm denoisingul, condiționat de încorporarea textului.
Renderizarea
Pentru a vizualiza rezultatele și a calcula pierderile în timpul antrenamentului, avem nevoie să renderizăm reprezentarea noastră 3D în imagini 2D. Acest lucru se realizează de obicei folosind tehnici de renderizare diferențiale care permit gradientelor să curgă înapoi prin procesul de renderizare.
Pentru reprezentări bazate pe rețele, am putea folosi un renderer bazat pe rasterizare:
Pentru reprezentări implicite precum NeRF, de obicei folosim tehnici de mers pe raze pentru a renderiza vederi.
Punerea tuturor laolaltă: Pipeline-ul text-3D
Acum că am acoperit componentele cheie, să trecem prin modul în care acestea se reunesc într-un pipeline tipic de generare text-3D:
Encodarea textului: Promptul de intrare este încodat într-o reprezentare vectorială densă folosind un model de limbaj.
Generarea inițială: Un model de difuzie, condiționat de încorporarea textului, generează o reprezentare 3D inițială (de exemplu, un NeRF sau o funcție implicită).
Consistența multi-vizuală: Modelul renderizează multiple vederi ale activului 3D generat și asigură coerența dintre punctele de vedere.
Rafinarea: Rețele suplimentare pot rafina geometria, adăuga texturi sau îmbunătăți detalii.
Ieșirea finală: Reprezentarea 3D este convertită într-un format dorit (de exemplu, o rețea texturată) pentru utilizare în aplicații downstream.
Iată un exemplu simplificat de cum ar putea arăta acest lucru în cod:
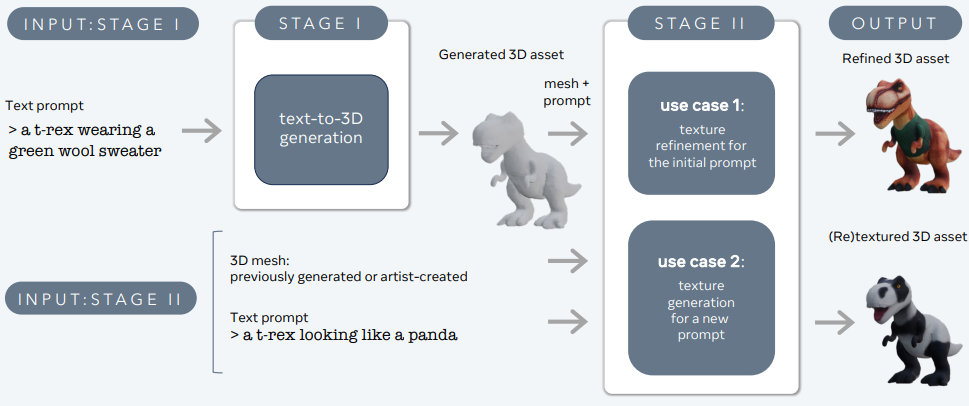
3DGen suportă renderizarea bazată pe fizică (PBR), esențială pentru realistul iluminat al activelor 3D în aplicații din lumea reală. De asemenea, permite generarea de texturi pentru forme 3D generate anterior sau create de artiști, utilizând noi intrări textuale. Pipeline-ul integrează două componente de bază: Meta 3D AssetGen și Meta 3D TextureGen, care gestionează generarea text-3D și text-textură, respectiv.
Meta 3D AssetGen
Meta 3D AssetGen (Siddiqui et al., 2024) este responsabil pentru generarea inițială a activelor 3D din promturi de text. Acest component produce o rețea 3D cu texturi și hărți de material PBR în aproximativ 30 de secunde.
Meta 3D TextureGen
Meta 3D TextureGen (Bensadoun et al., 2024) rafinează texturile generate de AssetGen. De asemenea, poate fi utilizat pentru a genera noi texturi pentru rețele 3D existente, pe baza unor descrieri textuale suplimentare. Această etapă durează aproximativ 20 de secunde.
Point-E (OpenAI)
Point-E, dezvoltat de OpenAI, este un alt model notabil de generare text-3D. În contrast cu DreamFusion, care produce reprezentări NeRF, Point-E generează nori de puncte 3D.
Caracteristici cheie ale Point-E:
a) Pipeline în două etape: Point-E generează mai întâi o vedere 2D sintetică folosind un model de difuzie text-imagine, apoi folosește această imagine pentru a condiționa un al doilea model de difuzie care produce norul de puncte 3D.
b) Eficiență: Point-E este proiectat pentru a fi eficient din punct de vedere computațional, capabil să genereze nori de puncte 3D în secunde pe o singură GPU.
c) Informații de culoare: Modelul poate genera nori de puncte colorate, păstrând atât informația geometrică, cât și cea de aspect.
Limitări:
Fidelitate mai scăzută în comparație cu abordările bazate pe rețele sau NeRF
Nori de puncte necesită procesare suplimentară pentru multe aplicații downstream
Shap-E (OpenAI):
Extinzând Point-E, OpenAI a introdus Shap-E, care generează rețele 3D în loc de nori de puncte. Acest lucru abordează unele dintre limitările Point-E, menținând în același timp eficiența computațională.
Caracteristici cheie ale Shap-E:
a) Reprezentare implicită: Shap-E învață să genereze reprezentări implicite (funcții de distanță semnată) ale obiectelor 3D.
b) Extracția rețelei: Modelul folosește o implementare diferențială a algoritmului de cuburi marchează pentru a converti reprezentarea implicită într-o rețea poligonală.
c) Generarea texturii: Shap-E poate genera, de asemenea, texturi pentru rețelele 3D, rezultând ieșiri mai atractive din punct de vedere vizual.
Avantaje:
Timp de generare rapid (secunde până la minute)
Ieșire directă a rețelei potrivită pentru renderizare și aplicații downstream
Capacitatea de a genera atât geometrie, cât și textură
GET3D (NVIDIA):
GET3D, dezvoltat de cercetători NVIDIA, este un alt model puternic de generare text-3D care se concentrează pe producerea de rețele 3D texturate de înaltă calitate.
Caracteristici cheie ale GET3D:
a) Reprezentare de suprafață explicită: În contrast cu DreamFusion sau Shap-E, GET3D generează direct reprezentări de suprafață explicite (rețele) fără reprezentări implicite intermediare.
b) Generarea texturii: Modelul include o tehnică de renderizare diferențială pentru a învăța și genera texturi de înaltă calitate pentru rețelele 3D.
c) Arhitectură GAN: GET3D folosește o abordare de rețea generativă adversarială (GAN), care permite generarea rapidă odată ce modelul este antrenat.
Avantaje:
Geometrie și texturi de înaltă calitate
Timp de inferență rapid
Integrare directă cu motoare de renderizare 3D
Limitări:
Necesită date de antrenament 3D, care pot fi rare pentru unele categorii de obiecte
Concluzie
Generarea 3D din text cu ajutorul inteligenței artificiale reprezintă o schimbare fundamentală în modul în care creăm și interacționăm cu conținutul 3D. Prin utilizarea unor tehnici avansate de învățare profundă, aceste modele pot produce active 3D complexe și de înaltă calitate din descrieri textuale simple. Pe măsură ce tehnologia continuă să evolueze, putem să ne așteptăm la sisteme text-3D din ce în ce mai sofisticate și capabile, care vor revoluționa industrii de la jocuri și film la design de produs și arhitectură.
Am petrecut ultimii cinci ani scufundându-mă în lumea fascinantă a Învățării Automate și a Învățării Profunde. Pasiunea și expertiza mea m-au condus să contribui la peste 50 de proiecte diverse de inginerie software, cu un accent deosebit pe AI/ML. Curiozitatea mea continuă m-a atras și spre Procesarea Limbajului Natural, un domeniu pe care sunt dornic să-l explorez mai departe.