Inteligență artificială
AudioSep : Separați orice ați descrie
LASS sau Separarea Surselor Audio pe baza Limbajului este noul paradigmă pentru CASA sau Analiza Auditivă Computațională care vizează separarea unui sunet țintă dintr-un amestec de audio folosind o interogare în limbaj natural care oferă o interfață naturală, dar scalabilă, pentru sarcinile și aplicațiile audio digitale. Deși cadrele LASS au evoluat semnificativ în ultimii ani în ceea ce privește realizarea performanței dorite pe surse audio specifice, cum ar fi instrumentele muzicale, acestea nu sunt capabile să separe sunetul țintă în domeniul deschis.
AudioSep, este un model fundamental care vizează rezolvarea limitărilor actuale ale cadrelor LASS, permițând separarea sunetului țintă folosind interogări în limbaj natural. Dezvoltatorii modelului AudioSep au antrenat modelul pe o varietate largă de seturi de date multimodale de mare scară și au evaluat performanța cadrelor pe o gamă largă de sarcini audio, inclusiv separarea instrumentelor muzicale, separarea evenimentelor audio și îmbunătățirea vorbirii, printre altele. Performanța inițială a AudioSep îndeplinește benchmark-urile, demonstrând capacități impresionante de învățare zero-shot și livrând o separare puternică a sunetului.
În acest articol, vom face o analiză mai profundă a funcționării cadrelor AudioSep, vom evalua arhitectura modelului, seturile de date utilizate pentru antrenare și evaluare și conceptele esențiale implicate în funcționarea modelului AudioSep. Așadar, să începem cu o introducere de bază în cadrul CASA.
CASA, USS, QSS, LASS Cadrele : Fundamentul pentru AudioSep
CASA sau Analiza Auditivă Computațională este un cadru utilizat de dezvoltatori pentru a proiecta sisteme de ascultare care au capacitatea de a percepe medii sonore complexe într-un mod similar cu modul în care oamenii percep sunetul folosind sistemele lor auditive. Separarea sunetului, cu un accent special pe separarea sunetului țintă, este o zonă fundamentală de cercetare în cadrul CASA și vizează rezolvarea “problemei cocktail party” sau separarea înregistrărilor audio reale de la surse audio individuale sau fișiere. Importanța separării sunetului poate fi atribuită în principal aplicațiilor sale largi, inclusiv separarea surselor muzicale, separarea surselor audio, îmbunătățirea vorbirii, identificarea sunetului țintă și multe altele.
Majoritatea lucrărilor de separare a sunetului efectuate în trecut se concentrează în principal pe separarea uneia sau mai multor surse audio, cum ar fi separarea muzicii sau a vorbirii. Un model nou, denumit USS sau Separarea Universală a Sunetului, vizează separarea sunetelor arbitrare în înregistrări audio reale. Cu toate acestea, este o sarcină provocatoare și restrictivă să separe fiecare sursă de sunet dintr-un amestec de audio, în principal din cauza gamei largi de surse de sunet diferite care există în lume, ceea ce este motivul principal pentru care metoda USS nu este fezabilă pentru aplicații din lumea reală care funcționează în timp real.
O alternativă fezabilă la metoda USS este metoda QSS sau Separarea Sunetului pe baza Interogării, care vizează separarea unei surse de sunet individuale sau țintă din amestecul de audio pe baza unui set de interogări. Datorită acestui fapt, cadrul QSS permite dezvoltatorilor și utilizatorilor să extragă sursele de audio dorite din amestec pe baza nevoilor lor, ceea ce face ca metoda QSS să fie o soluție mai practică pentru aplicații digitale din lumea reală, cum ar fi editarea conținutului multimedia sau editarea audio.
Mai mult, dezvoltatorii au propus recent o extensie a cadrului QSS, cadrul LASS sau Separarea Surselor Audio pe baza Limbajului, care vizează separarea surselor arbitrare de sunet dintr-un amestec de audio folosind descrieri în limbaj natural ale sursei de sunet țintă. Deoarece cadrul LASS permite utilizatorilor să extragă sursele de audio țintă folosind un set de instrucțiuni în limbaj natural, poate deveni un instrument puternic cu aplicații largi în aplicații audio digitale. În comparație cu metodele tradiționale de interogare audio sau vizuală, utilizarea instrucțiunilor în limbaj natural pentru separarea sunetului oferă un grad mai mare de avantaje, deoarece adaugă flexibilitate și face ca obținerea informațiilor de interogare să fie mult mai ușoară și convenabilă. Mai mult, în comparație cu cadrele de separare a sunetului pe baza etichetelor care utilizează un set predefinit de instrucțiuni sau interogări, cadrul LASS nu limitează numărul de interogări de intrare și are flexibilitatea de a fi generalizat în mod deschis.
Inițial, cadrul LASS se bazează pe învățarea supravegheată, în care modelul este antrenat pe un set de date audio-text etichetate. Cu toate acestea, problema principală cu această abordare este disponibilitatea limitată a datelor audio-text etichetate și annotate. Pentru a reduce dependența cadrului LASS de date audio-text etichetate și annotate, modelele sunt antrenate folosind abordarea de învățare supravegheată multimodală. Scopul principal al utilizării unei abordări de învățare supravegheată multimodală este de a utiliza modele de pre-antrenare contrastivă multimodală, cum ar fi modelul CLIP sau Contrastive Language Image Pre-training, ca encoder de interogare pentru cadru. Deoarece modelul CLIP are capacitatea de a alinia încorporările textului cu alte modalități, cum ar fi audio sau vizual, permite dezvoltatorilor să antreneze modelele LASS folosind date bogate în modalități și să interfereze cu datele textuale într-un mediu zero-shot. Cu toate acestea, cadrele LASS actuale utilizează seturi de date de mică scară pentru antrenare, iar aplicațiile cadrului LASS în sute de domenii potențiale sunt încă de explorat.
Pentru a rezolva limitările actuale cu care se confruntă cadrele LASS, dezvoltatorii au introdus AudioSep, un model fundamental care vizează separarea sunetului dintr-un amestec de audio folosind descrieri în limbaj natural. Focusul actual pentru AudioSep este de a dezvolta un model de separare a sunetului pre-antrenat care să utilizeze seturi de date multimodale de mare scară pentru a permite generalizarea modelelor LASS în aplicații deschise. Pentru a rezuma, modelul AudioSep este: ” Un model fundamental pentru separarea universală a sunetului în domeniul deschis folosind interogări sau descrieri în limbaj natural antrenate pe seturi de date audio și multimodale de mare scară “.
AudioSep : Componente cheie și Arhitectură
Arhitectura cadrului AudioSep cuprinde două componente cheie: un encoder de text și un model de separare.
Encoderul de Text
Cadrul AudioSep utilizează un encoder de text al modelului CLIP sau Contrastive Language Image Pre-training sau al modelului CLAP sau Contrastive Language Audio Pre-training pentru a extrage încorporări de text dintr-o interogare în limbaj natural. Interogarea de text de intrare constă într-o secvență de ” N ” de tokeni care este apoi procesată de encoderul de text pentru a extrage încorporările de text pentru interogarea de limbaj natural dată. Encoderul de text utilizează un stivă de blocuri de transformator pentru a codifica tokenii de text de intrare, iar reprezentările de ieșire sunt agregate după ce sunt trecute prin straturile de transformator care duc la dezvoltarea unei reprezentări vectoriale cu lungime fixă, unde D corespunde dimensiunilor modelului CLAP sau CLIP, în timp ce encoderul de text este înghețat în timpul perioadei de antrenare.
Modelul CLIP este pre-antrenat pe un set de date de mare scară de perechi de imagini și text folosind învățarea contrastivă, ceea ce face ca encoderul de text să învețe să mappeze descrierile textuale pe spațiul semantic care este, de asemenea, împărtășit de reprezentările vizuale. Avantajul pe care AudioSep îl obține prin utilizarea encoderului de text al modelului CLIP este că poate acum să scaleze sau să antreneze modelul LASS din date audio-vizuale neetichetate, utilizând încorporările vizuale ca o alternativă, permițând astfel antrenarea modelelor LASS fără necesitatea datelor audio-text etichetate și annotate.
Modelul CLAP funcționează similar cu modelul CLIP și utilizează un obiectiv de învățare contrastivă, utilizând un encoder de text și un encoder de audio pentru a conecta audio și limbaj, aducând astfel descrierile textuale și audio pe un spațiu latent audio-text comun.
Modelul de Separare
Cadrul AudioSep utilizează un model ResUNet în domeniul frecvenței care este alimentat cu un amestec de clipuri audio ca spatele de separare pentru cadru. Cadrul funcționează prin aplicarea unei transformări Fourier pe scara timpului (STFT) asupra semnalului undei pentru a extrage un spectrogram complex, un spectrogram de magnitudine și faza lui X. Modelul urmează apoi aceeași configurație și construiește o rețea encoder-decoder pentru a procesa spectrogramul de magnitudine.
Rețeaua ResUNet encoder-decoder constă din 6 blocuri reziduale, 6 blocuri decoder și 4 blocuri de gât. Spectrogramul din fiecare bloc encoder utilizează 4 blocuri convenționale reziduale pentru a descărca într-o caracteristică de gât, în timp ce blocurile decoder utilizează 4 blocuri deconvolutionale reziduale pentru a obține componente de separare prin supra-echantionarea caracteristicilor. Ulterior, fiecare bloc encoder și blocul său corespunzător de decoder stabilesc o conexiune de salt care funcționează la același ritm de supra-echantionare sau descărcare. Blocul rezidual al cadrului constă din 2 straturi de activare Leaky-ReLU, 2 straturi de normalizare în batch și 2 straturi CNN, iar cadrul introduce, de asemenea, un scurtcircuit rezidual suplimentar care conectează intrarea și ieșirea fiecărui bloc rezidual individual. Modelul ResUNet ia spectrogramul complex X ca intrare și produce masca de magnitudine M ca ieșire, cu faza reziduală condiționată de încorporările de text care controlează magnitudinea de scalare și rotația unghiului spectrogramului. Spectrogramul separat complex poate fi extras prin înmulțirea măștii de magnitudine prevăzute și a fazei reziduale cu STFT (Transformarea Fourier pe scara timpului) a amestecului.

În cadrul său, AudioSep utilizează un strat FiLm sau Feature-wise Linearly modulated pentru a conecta modelul de separare și encoderul de text după implementarea blocurilor convolutionale în ResUNet.
Antrenare și Pierdere
În timpul antrenării modelului AudioSep, dezvoltatorii utilizează metoda de augmentare a zgomotului și antrenează cadrul AudioSep de la capăt la coadă, utilizând o funcție de pierdere L1 între forma de undă reală și cea prevăzută.
Seturi de Date și Benchmark-uri
Așa cum s-a menționat în secțiunile anterioare, AudioSep este un model fundamental care vizează rezolvarea dependenței actuale a modelelor LASS de seturi de date audio-text etichetate și annotate. Modelul AudioSep este antrenat pe o varietate largă de seturi de date pentru a-i oferi capacități de învățare multimodală, iar aici este o descriere detaliată a setului de date și a benchmark-urilor utilizate de dezvoltatori pentru a antrena cadrul AudioSep.
AudioSet
AudioSet este un set de date audio de mare scară, etichetat slab, care cuprinde peste 2 milioane de fragmente audio de 10 secunde extrase direct din YouTube. Fiecare fragment audio din setul de date AudioSet este categorizat prin prezența sau absența claselor de sunete, fără detalii specifice despre timpul evenimentelor sonore. Setul de date AudioSet are peste 500 de clase de sunete distincte, incluzând sunete naturale, sunete umane, sunete de vehicule și multe altele.
VGGSound
Setul de date VGGSound este un set de date vizual-audio de mare scară, care, la fel ca AudioSet, a fost sursat direct din YouTube și conține peste 200.000 de clipuri video, fiecare cu o lungime de 10 secunde. Setul de date VGGSound este categorizat în peste 300 de clase de sunete, incluzând sunete umane, sunete naturale, sunete de păsări și multe altele. Utilizarea setului de date VGGSound asigură faptul că obiectul responsabil pentru producerea sunetului țintă este, de asemenea, descris în clipul video corespunzător.
AudioCaps
AudioCaps este cel mai mare set de date de captionare audio disponibil public și cuprinde peste 50.000 de clipuri audio de 10 secunde extrase din setul de date AudioSet. Datele din AudioCaps sunt împărțite în trei categorii: date de antrenare, date de testare și date de validare, iar clipurile audio sunt etichetate cu descrieri în limbaj natural utilizând platforma Amazon Mechanical Turk. Este important de remarcat că fiecare clip audio din setul de date de antrenare are o singură legendă, în timp ce datele din seturile de testare și validare au câte 5 legende reale.
ClothoV2
ClothoV2 este un set de date de captionare audio care constă din clipuri sursate din platforma FreeSound, iar, la fel ca AudioCaps, fiecare clip audio este etichetat cu descrieri în limbaj natural utilizând platforma Amazon Mechanical Turk.
WavCaps
La fel ca AudioSet, WavCaps este un set de date audio de mare scară, etichetat slab, care cuprinde peste 400.000 de clipuri audio cu legende, iar timpul de rulare total este de aproximativ 7568 de ore de date de antrenare. Clipurile audio din setul de date WavCaps sunt sursate dintr-o varietate largă de surse audio, incluzând BBC Sound Effects, AudioSet, FreeSound, SoundBible și multe altele.

Detalii de Antrenare
În timpul fazei de antrenare, modelul AudioSep eșantionează aleator două segmente audio sursate din două clipuri audio diferite din setul de date de antrenare și apoi le amestecă pentru a crea un amestec de antrenare, unde lungimea fiecărui segment audio este de aproximativ 5 secunde. Modelul extrage apoi spectrogramul complex din semnalul de undă utilizând o fereastră Hann de dimensiune 1024 cu o dimensiune de salt de 320.
Modelul utilizează apoi encoderul de text al modelelor CLIP/CLAP pentru a extrage încorporările textuale, cu supravegherea textului fiind configurația implicită pentru AudioSep. Pentru modelul de separare, cadrul AudioSep utilizează un strat ResUNet cu 30 de straturi, 6 blocuri encoder și 6 blocuri decoder, asemănător cu arhitectura urmată în cadrul separării universale a sunetului. Mai mult, fiecare bloc encoder are două straturi convolutionale cu o dimensiune a kernelului de 3×3, iar numărul de hărți de caracteristici de ieșire ale blocurilor encoder este de 32, 64, 128, 256, 512 și 1024, respectiv. Blocurile decoder au simetrie cu blocurile encoder, iar dezvoltatorii aplică optimizerul Adam pentru a antrena modelul AudioSep cu o dimensiune a lotului de 96.
Rezultate de Evaluare
Pe Seturi de Date Văzute
Următoarea figură compară performanța cadrului AudioSep pe seturi de date văzute în timpul fazei de antrenare, incluzând seturile de date de antrenare. Figura de mai jos reprezintă rezultatele de evaluare a cadrului AudioSep în comparație cu sistemele de bază, incluzând modele de îmbunătățire a vorbirii, LASS și CLIP. Modelul AudioSep cu encoder de text CLIP este reprezentat ca AudioSep-CLIP, în timp ce modelul AudioSep cu encoder de text CLAP este reprezentat ca AudioSep-CLAP.

Așa cum se poate vedea în figură, cadrul AudioSep funcționează bine atunci când utilizează legende audio sau etichete text ca interogări de intrare, iar rezultatele indică o performanță superioară a cadrului AudioSep în comparație cu modelele de separare a sunetului anterioare, cum ar fi LASS, și poate fi capabil să rezolve limitările actuale ale cadrului de separare a sunetului popular.
Pe Seturi de Date Nevăzute
Pentru a evalua performanța AudioSep într-un mediu zero-shot, dezvoltatorii au continuat să evalueze performanța pe seturi de date nevăzute, iar cadrul AudioSep oferă o separare impresionantă a sunetului într-un mediu zero-shot, iar rezultatele sunt afișate în figura de mai jos.

Mai mult, imaginea de mai jos arată rezultatele evaluării modelului AudioSep împotriva îmbunătățirii vorbirii Voicebank-Demand.

Evaluarea cadrului AudioSep indică o performanță puternică și dorită pe seturi de date nevăzute într-un mediu zero-shot, ceea ce deschide calea pentru efectuarea de sarcini de operare a sunetului pe noi distribuții de date.
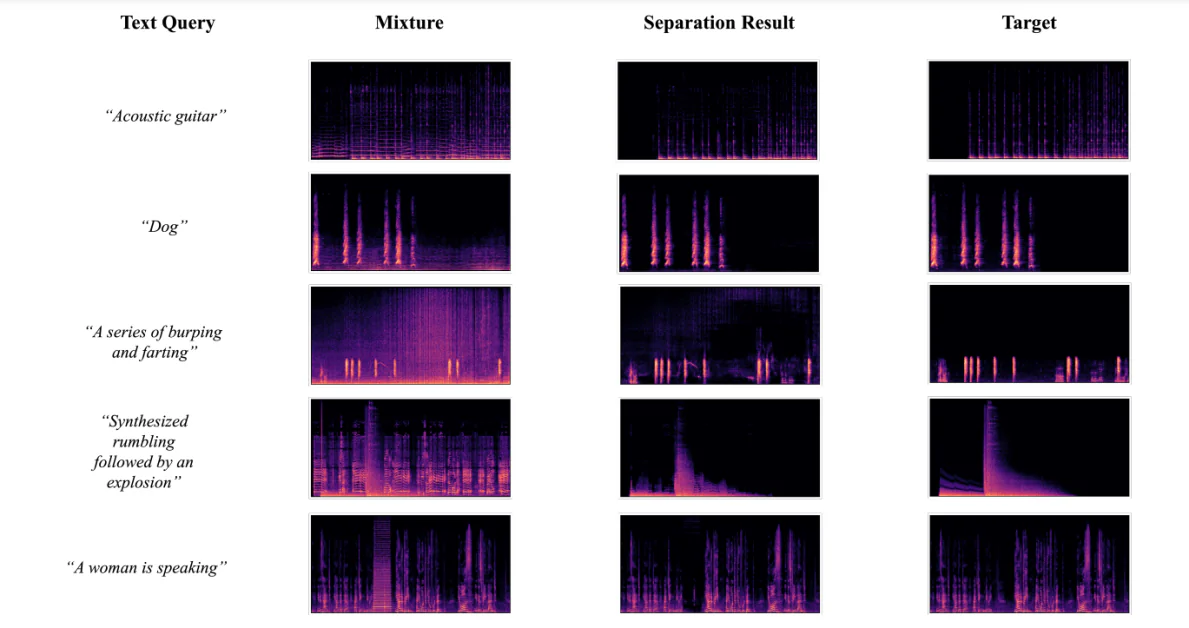
Vizualizarea Rezultatelor de Separare
Figura de mai jos arată rezultatele obținute atunci când dezvoltatorii au utilizat cadrul AudioSep-CLAP pentru a efectua vizualizări ale spectrogramelor pentru surse de sunet țintă reale, amestecuri de sunet și surse de sunet separate utilizând interogări textuale diverse de sunete. Rezultatele au permis dezvoltatorilor să observe că modelul spectrogramului sursă separat este aproape de sursa reală, ceea ce sprijină în continuare rezultatele obiective obținute în timpul experimentelor.
Comparația Interogărilor Textuale
Dezvoltatorii evaluează performanța AudioSep-CLAP și AudioSep-CLIP pe AudioCaps Mini, iar dezvoltatorii utilizează etichetele de evenimente AudioSet, legendele AudioCaps și descrierile în limbaj natural re-annotate pentru a examina efectele diferitelor interogări, iar figura de mai jos arată un exemplu al AudioCaps Mini în acțiune.

Concluzie
AudioSep este un model fundamental dezvoltat cu scopul de a fi un cadru universal de separare a sunetului în domeniul deschis care utilizează descrieri în limbaj natural pentru separarea sunetului. Așa cum s-a observat în timpul evaluării, cadrul AudioSep este capabil să efectueze învățare zero-shot și nesupravegheată fără probleme, utilizând legende audio sau etichete text ca interogări. Rezultatele și performanța de evaluare a AudioSep indică o performanță puternică care depășește cadrele actuale de separare a sunetului, cum ar fi LASS, și poate fi capabil să rezolve limitările actuale ale cadrului de separare a sunetului popular.












