Inteligență artificială
Andrew Ng Critică Cultura Supraajustării în Învățarea Automată
Andrew Ng, una dintre vocile cele mai influente în învățarea automată în ultimul deceniu, exprimă în prezent îngrijorări cu privire la măsura în care sectorul accentuează inovațiile în arhitectura modelului peste date – și, în special, la măsura în care permite rezultate “supraajustate” să fie prezentate ca soluții generalizate sau progrese.
Acestea sunt critici cuprinzătoare ale culturii actuale de învățare automată, provenind de la una dintre autoritățile sale cele mai înalte, și au implicații pentru încrederea într-un sector bântuit de temeri cu privire la o a treia prăbușire a încrederii comerciale în dezvoltarea IA într-un spațiu de șaizeci de ani.
Ng, profesor la Universitatea Stanford, este, de asemenea, unul dintre fondatorii deeplearning.ai, și în martie a publicat un articol pe site-ul organizației care a distilat o discurs recent al său la câteva recomandări de bază:
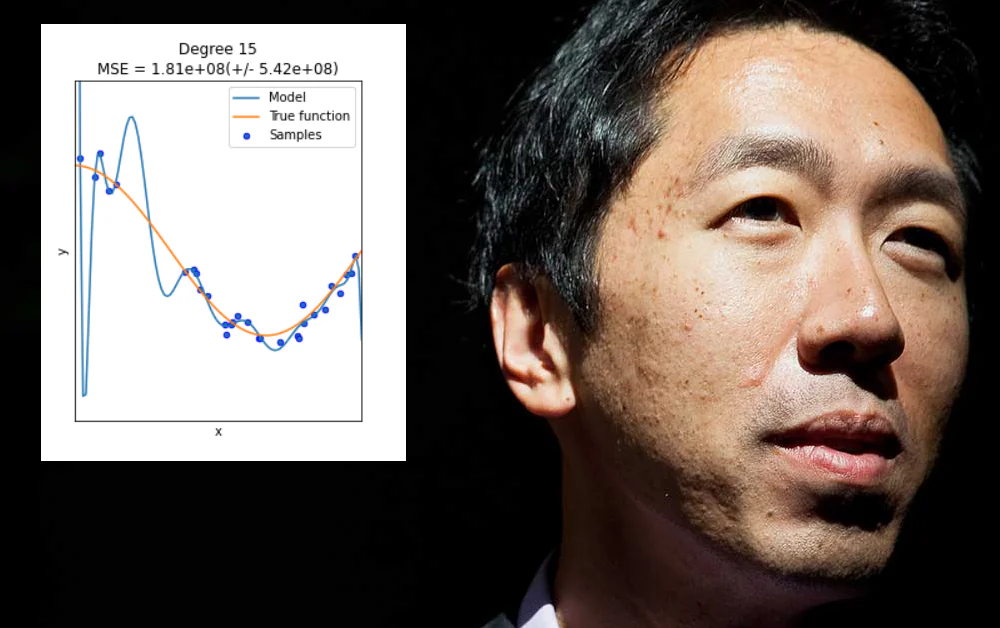
În primul rând, că comunitatea de cercetare ar trebui să înceteze să se plângă că curățarea datelor reprezintă 80% din provocările învățării automate și să se apuce de treabă pentru a dezvolta metodologii și practici robuste MLOps.
În al doilea rând, că ar trebui să se îndepărteze de “câștigurile ușoare” care pot fi obținute prin supraajustarea datelor la un model de învățare automată, astfel încât să funcționeze bine pe acel model, dar să nu generalizeze sau să nu producă un model larg utilizabil.
Aceptarea Provocării Arhitecturii și Curățirii Datelor
“Punctul meu de vedere”, a scris Ng, “este că, dacă 80 la sută din munca noastră este pregătirea datelor, atunci asigurarea calității datelor este o muncă importantă a unei echipe de învățare automată.”
El a continuat:
“În loc să ne bazăm pe ingineri să găsească întâmplător cel mai bun mod de a îmbunătăți un set de date, sper că putem dezvolta unelte MLOps care să ajute la construirea sistemelor de inteligență artificială, inclusiv construirea seturilor de date de înaltă calitate, mai repetitive și sistematice.
“MLOps este un domeniu în curs de dezvoltare, și diferiți oameni îl definesc în moduri diferite. Dar cred că principiul de organizare cel mai important al echipelor și uneltelor MLOps ar trebui să fie acela de a asigura fluxul constant și de înaltă calitate a datelor în toate etapele unui proiect. Acest lucru va ajuta multe proiecte să decurgă mai lin.”
Vorbind pe Zoom, într-o sesiune de întrebări și răspunsuri transmisă live la sfârșitul lunii aprilie, Ng a abordat problema lipsei de aplicabilitate în sistemele de analiză a învățării automate pentru radiologie:
“Se dovedește că, atunci când colectăm date de la Spitalul Stanford, apoi le antrenăm și le testăm pe date de la același spital, într-adevăr, putem publica articole care arată [algoritmii] sunt comparabili cu radiologii umani în detectarea anumitor afecțiuni.
“…[Când] iei același model, același sistem de inteligență artificială, la un spital mai vechi de pe stradă, cu o mașină mai veche, și tehnicianul folosește un protocol de imagistică ușor diferit, datele se deplasează și cauzează performanța sistemului de inteligență artificială să se degradeze semnificativ. În contrast, orice radiolog uman poate merge pe stradă la spitalul mai vechi și să facă foarte bine.”
Subspecificarea Nu Este O Soluție
Supraajustarea are loc atunci când un model de învățare automată este proiectat în mod special pentru a se potrivi cu excentricitățile unui anumit set de date (sau modul în care datele sunt formate). Acest lucru poate implica, de exemplu, specificarea greutăților care vor produce rezultate bune din acel set de date, dar nu vor “generaliza” pe alte date.
În multe cazuri, astfel de parametri sunt definiți pe “aspecte non-date” ale setului de antrenare, cum ar fi rezoluția specifică a informațiilor colectate sau alte idiosincrazii care nu sunt garantate să se repete în alte seturi de date ulterioare.
Deși ar fi frumos, supraajustarea nu este o problemă care poate fi rezolvată prin lărgirea orbirii sau flexibilității arhitecturii datelor sau a proiectării modelului, atunci când ceea ce este necesar într-adevăr sunt caracteristici larg aplicabile și foarte relevante care vor funcționa bine într-o varietate de medii de date – o provocare mai spinosă.
În general, acest tip de “subspecificare” duce doar la problemele pe care Ng le-a descris recent, în care un model de învățare automată eşuează pe date nevizionate. Diferența în acest caz este că modelul eşuează nu pentru că datele sau formatarea datelor este diferită de setul de antrenare original supraajustat, ci pentru că modelul este prea flexibil, în loc de a fi prea fragil.
La sfârșitul anului 2020, articolul Subspecificarea prezintă provocări pentru credibilitatea învățării automate moderne a nivelat critici intense împotriva acestei practici și a purtat numele a nu mai puțin de patruzeci de cercetători și oameni de știință în domeniul învățării automate de la Google și MIT, printre alte instituții.
Articolul critică “învățarea scurtăturilor” și observă modul în care modelele sub-specificate pot să se îndepărteze în direcții sălbatice pe baza punctului de start aleatoriu la care începe antrenamentul modelului. Contributorii observă:
‘Am văzut că subspecificarea este ubicuă în fluxurile practice de învățare automată din multe domenii. Într-adevăr, datorită subspecificării, aspecte importante ale deciziilor sunt determinate de alegeri arbitrare, cum ar fi sămânța aleatorie utilizată pentru inițializarea parametrilor.’
Implicații Economice Ale Schimbării Culturii
În ciuda calificărilor sale academice, Ng nu este un academic aerian, ci are o experiență profundă și de nivel înalt în industrie, ca co-fondator al Google Brain și Coursera, ca fost științific principal pentru Big Data și IA la Baidu și ca fondator al Landing AI, care administrează 175 de milioane de dolari pentru noi startup-uri în sector.
Când spune “Toată IA, nu doar sănătatea, are o prăpastie de la concept la producție”, este menit să fie un apel de trezire pentru un sector a cărui nivel actual de hype și istorie punctată a caracterizat-o din ce în ce mai mult ca o investiție comercială incertă pe termen lung, confruntată cu probleme de definiție și de sferă.
Cu toate acestea, sistemele de învățare automată proprietare care funcționează bine în situații specifice și eşuează în alte medii reprezintă tipul de captură a pieței care ar putea răsplăti investițiile industriale. Prezentarea “problemei de supraajustare” în contextul unui pericol profesional oferă o modalitate de a monetiza investițiile corporative în cercetarea cu sursă deschisă și de a produce (în mod eficient) sisteme proprietare în care replicarea de către concurenți este posibilă, dar problematică.
Dacă acest abordare ar funcționa pe termen lung depinde de măsura în care adevăratele progrese în învățarea automată vor continua să necesite niveluri din ce în ce mai mari de investiții, și dacă toate inițiativele productive vor migra în mod inevitabil către FAANG într-o oarecare măsură, din cauza resurselor uriașe necesare pentru găzduire și operare.












