Inteligência artificial
Dados sintéticos: preenchendo a lacuna de oclusão com Grand Theft Auto
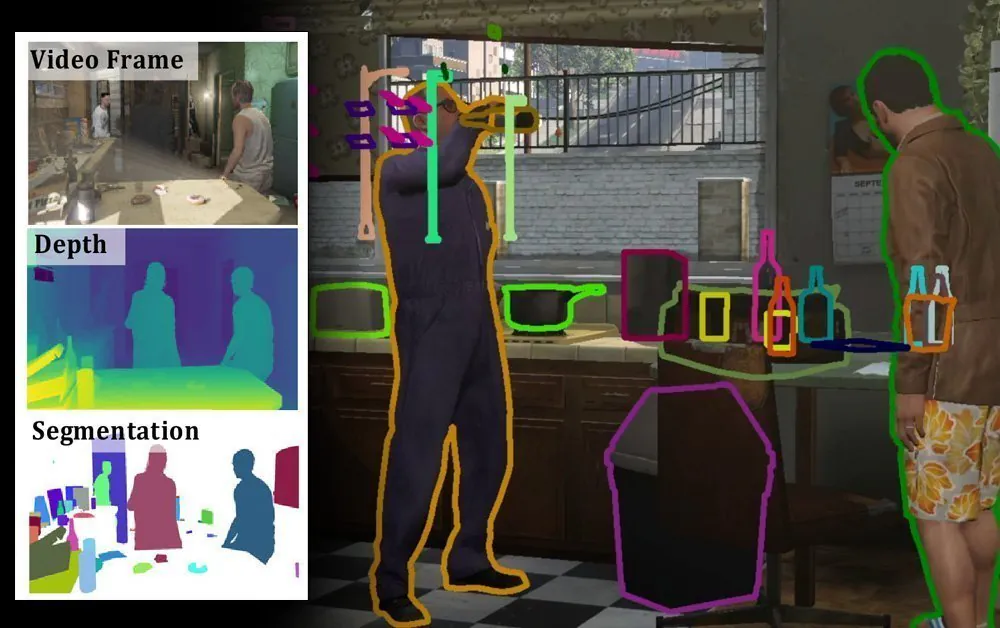
Pesquisadores da Universidade de Illinois criaram um novo conjunto de dados de visão computacional que usa imagens sintéticas geradas por um mecanismo de jogo Grand Theft Auto para ajudar a resolver um dos obstáculos mais espinhosos na segmentação semântica – reconhecer objetos que são apenas parcialmente visíveis nas imagens e vídeos originais.
Para isso, conforme descrito em o papel, os pesquisadores usaram o mecanismo de videogame GTA-V para gerar um conjunto de dados sintético que não apenas apresenta um número recorde de instâncias de oclusão, mas também segmentação semântica e rotulagem perfeitas, além de contabilizar informações temporais de uma maneira que não é abordados por conjuntos de dados de código aberto semelhantes.
Entendimento completo da cena
O vídeo abaixo, publicado como material de apoio à pesquisa, ilustra as vantagens de uma compreensão 3D completa de uma cena, na medida em que objetos obscurecidos são conhecidos e expostos na cena em todas as circunstâncias, permitindo que o sistema avaliador aprenda a associar visões parcialmente ocluídas com todo o objeto (rotulado).
Fonte: http://sailvos.web.illinois.edu/_site/index.html
O conjunto de dados resultante, chamado SAIL-VOS 3D, é reivindicado pelos autores como o primeiro conjunto de dados de malha de vídeo sintético com anotação quadro a quadro, segmentação em nível de instância, profundidade de verdade para visualizações de cena e anotações 2D delineadas por caixas delimitadoras.

fonte (Clique para ampliar)
As anotações do SAIL-VOS 3D incluem profundidade, nível de instância modal e amodal segmentação, rótulos semânticos e malhas 3D. Os dados incluem 484 vídeos totalizando 237,611 quadros em resolução de 1280 × 800, incluindo transições de tiro.

Acima, os quadros CGI originais; segunda linha, segmentação em nível de instância; terceira linha, segmentação amodal, que ilustra a profundidade da compreensão da cena e transparência disponível nos dados. fonte (Clique para ampliar)
O conjunto se divide em 6,807 clipes com uma média de 34.6 quadros cada, e os dados são anotados com 3,460,213 instâncias de objetos originadas de 3,576 modelos de malha no mecanismo de jogo GTA-V. Estes são atribuídos a um total de 178 categorias semânticas.
Reconstrução de malha e rotulagem automatizada
Como é provável que pesquisas posteriores de conjuntos de dados ocorram em imagens do mundo real, as malhas no SAIL-VOS 3D são geradas pela estrutura de aprendizado de máquina, em vez de derivadas do mecanismo GTA-V.

Com uma compreensão programática e essencialmente "holográfica" de toda a representação da cena, as imagens 3D do SAIL-VOS podem sintetizar representações de objetos normalmente ocultos por oclusões, como o braço do personagem voltado para longe se virando aqui, de uma forma que, de outra forma, dependeria de muitas instâncias representativas em filmagens do mundo real. (Clique para ampliar) Fonte: https://arxiv.org/pdf/2105.08612.pdf
Como cada objeto no mundo do GTA-V contém um ID exclusivo, o SAIL-VOS os recupera do mecanismo de renderização usando a biblioteca de ganchos de script do GTA-V. Isso resolve o problema de readquirir o assunto se ele deixar o campo de visão temporariamente, pois a rotulagem é persistente e confiável. São 162 objetos disponíveis no ambiente, que os pesquisadores mapearam para um número correspondente de classes.
Uma variedade de cenas e objetos
Muitos dos objetos no motor GTA-V são comuns na natureza e, portanto, o inventário SAIL-VOS contém 60% das classes presentes no jogo de 2014 mais usado pela Microsoft. conjunto de dados MS-COCO.

O conjunto de dados SAIL-VOS inclui uma grande variedade de cenas internas e externas sob diferentes condições climáticas, com personagens vestindo roupas variadas. (Clique para ampliar)
Aplicabilidade
Para garantir a compatibilidade com o andamento geral da pesquisa nessa área e confirmar que essa abordagem sintética pode beneficiar projetos não sintéticos, os pesquisadores avaliaram o conjunto de dados usando a abordagem de detecção baseada em quadros empregada para o MS-COCO e o 2012 Desafio de Classes de Objetos Visuais (VOC) PASCAL, com precisão média como a métrica.
Os pesquisadores descobriram que o pré-treinamento no conjunto de dados SAIL-VOS melhora o desempenho da interseção sobre a união (IoU) em 19%, com uma melhoria correspondente na VideoMatch desempenho, de 55% para 74% em dados não vistos.
No entanto, em casos de oclusão extrema, houve ocasiões em que todos os métodos mais antigos permaneceram incapazes de identificar um objeto ou pessoa, embora os pesquisadores previssem que isso poderia ser remediado no futuro examinando quadros adjacentes para estabelecer o raciocínio para a máscara amodal. .

Nas duas imagens à direita, algoritmos tradicionais de segmentação não conseguiram identificar a figura feminina a partir da parte muito limitada de sua cabeça que é visível. Inovações posteriores com avaliação de fluxo óptico podem melhorar esses resultados. (Clique para ampliar)












