
Kunstig intelligens
YOLOv7: Den mest avanserte objektdeteksjonsalgoritmen?

6. juli 2022 vil bli markert som et landemerke i AI-historien fordi det var på denne dagen da YOLOv7 ble utgitt. Helt siden lanseringen har YOLOv7 vært det heteste emnet i Computer Vision-utviklerfellesskapet, og av de rette grunnene. YOLOv7 blir allerede sett på som en milepæl i objektdeteksjonsindustrien.
Kort tid etter at YOLOv7-oppgaven ble publisert, den viste seg som den raskeste og mest nøyaktige modellen for gjenkjenning av innvendinger i sanntid. Men hvordan utkonkurrerer YOLOv7 sine forgjengere? Hva gjør YOLOv7 så effektiv til å utføre datasynsoppgaver?
I denne artikkelen skal vi prøve å analysere YOLOv7-modellen, og prøve å finne svaret på hvorfor YOLOv7 nå er i ferd med å bli industristandard? Men før vi kan svare på det, må vi ta en titt på den korte historien om gjenstandsdeteksjon.
Hva er objektdeteksjon?
Objektdeteksjon er en gren innen datasyn som identifiserer og lokaliserer objekter i et bilde eller en videofil. Objektdeteksjon er byggesteinen i en rekke applikasjoner, inkludert selvkjørende biler, overvåket overvåking og til og med robotikk.
En objektdeteksjonsmodell kan klassifiseres i to forskjellige kategorier, enkeltskuddsdetektorer, og flerskuddsdetektorer.
Sanntidsgjenkjenning av objekter
For å virkelig forstå hvordan YOLOv7 fungerer, er det viktig for oss å forstå YOLOv7s hovedmål, "Sanntidsgjenkjenning av objekter". Sanntidsgjenkjenning av objekter er en nøkkelkomponent i moderne datasyn. Sanntidsobjektdeteksjonsmodellene prøver å identifisere og lokalisere objekter av interesse i sanntid. Real Time Object Detection-modeller gjorde det veldig effektivt for utviklere å spore objekter av interesse i en bevegelig ramme som en video, eller en direkte overvåkingsinngang.

Sanntidsobjektgjenkjenningsmodeller er i hovedsak et skritt foran de konvensjonelle bildegjenkjenningsmodellene. Mens førstnevnte brukes til å spore objekter i videofiler, lokaliserer og identifiserer sistnevnte objekter innenfor en stasjonær ramme som et bilde.
Som et resultat er Real Time Object Detection-modeller veldig effektive for videoanalyse, autonome kjøretøy, objekttelling, multi-objektsporing og mye mer.
Hva er YOLO?
YOLO eller "Du ser bare en gang” er en familie av sanntids objektdeteksjonsmodeller. YOLO-konseptet ble først introdusert i 2016 av Joseph Redmon, og det ble snakk om byen nesten umiddelbart fordi det var mye raskere og mye mer nøyaktig enn de eksisterende objektdeteksjonsalgoritmene. Det tok ikke lang tid før YOLO-algoritmen ble en standard i datasynsindustrien.

Det grunnleggende konseptet som YOLO-algoritmen foreslår er å bruke et ende-til-ende nevralt nettverk ved å bruke grensebokser og klassesannsynligheter for å lage spådommer i sanntid. YOLO var forskjellig fra den forrige objektdeteksjonsmodellen i den forstand at den foreslo en annen tilnærming for å utføre objektdeteksjon ved å gjenbruke klassifikatorer.
Endringen i tilnærming fungerte ettersom YOLO snart ble bransjestandarden ettersom ytelsesgapet mellom seg selv og andre sanntidsobjektdeteksjonsalgoritmer var betydelige. Men hva var grunnen til at YOLO var så effektiv?
Sammenlignet med YOLO brukte objektdeteksjonsalgoritmer den gang Region Proposal Networks for å oppdage mulige områder av interesse. Anerkjennelsesprosessen ble deretter utført på hver region separat. Som et resultat utførte disse modellene ofte flere iterasjoner på det samme bildet, og derav mangelen på nøyaktighet og høyere utførelsestid. På den annen side bruker YOLO-algoritmen et enkelt fullt tilkoblet lag for å utføre prediksjonen på en gang.
Hvordan fungerer YOLO?
Det er tre trinn som forklarer hvordan en YOLO-algoritme fungerer.
Reframing objektdeteksjon som et enkelt regresjonsproblem
De YOLO-algoritmen prøver å omforme objektdeteksjon som et enkelt regresjonsproblem, inkludert bildepiksler, til klassesannsynligheter og grensebokskoordinater. Algoritmen må derfor kun se på bildet én gang for å forutsi og lokalisere målobjektene i bildene.
Årsaker til bildet globalt
Dessuten, når YOLO-algoritmen lager spådommer, begrunner den bildet globalt. Det er forskjellig fra regionforslagsbaserte og skyveteknikker ettersom YOLO-algoritmen ser hele bildet under trening og testing på datasettet, og er i stand til å kode kontekstuell informasjon om klassene og hvordan de vises.
Før YOLO var Fast R-CNN en av de mest populære objektdeteksjonsalgoritmene som ikke kunne se den større konteksten i bildet fordi den pleide å forveksle bakgrunnsflekker i et bilde for et objekt. Sammenlignet med Fast R-CNN-algoritmen er YOLO 50 % mer nøyaktig når det gjelder bakgrunnsfeil.
Generaliserer representasjon av objekter
Til slutt tar YOLO-algoritmen også som mål å generalisere representasjonene av objekter i et bilde. Som et resultat, når en YOLO-algoritme ble kjørt på et datasett med naturlige bilder, og testet for resultatene, utkonkurrerte YOLO eksisterende R-CNN-modeller med stor margin. Det er fordi YOLO er svært generaliserbart, sjansene for at det bryter ned når det implementeres på uventede innganger eller nye domener var små.
YOLOv7: Hva er nytt?
Nå som vi har en grunnleggende forståelse av hva sanntidsobjektdeteksjonsmodeller er, og hva som er YOLO-algoritmen, er det på tide å diskutere YOLOv7-algoritmen.
Optimalisering av opplæringsprosessen
YOLOv7-algoritmen prøver ikke bare å optimalisere modellarkitekturen, men den tar også sikte på å optimalisere treningsprosessen. Den tar sikte på å bruke optimaliseringsmoduler og metoder for å forbedre nøyaktigheten av objektdeteksjon, styrke kostnadene for trening, samtidig som interferenskostnadene opprettholdes. Disse optimaliseringsmodulene kan refereres til som en trenbar pose med gratissaker.
Grov til fin Lead Guided Label Assignment
YOLOv7-algoritmen planlegger å bruke en ny guidet etiketttilordning fra grov til fin bly i stedet for den konvensjonelle Dynamisk etiketttildeling. Det er slik fordi med dynamisk etiketttilordning forårsaker trening av en modell med flere utgangslag noen problemer, det vanligste er hvordan man tildeler dynamiske mål for forskjellige grener og deres utganger.
Re-parameterisering av modellen
Modellreparametrisering er et viktig konsept i objektdeteksjon, og bruken av den følges generelt med noen problemer under trening. YOLOv7-algoritmen planlegger å bruke konseptet gradientforplantningsvei for å analysere modellens re-parametriseringspolicyer gjelder for ulike lag i nettverket.
Forleng og sammensatt skalering
YOLOv7-algoritmen introduserer også utvidede og sammensatte skaleringsmetoder å utnytte og effektivt bruke parametrene og beregningene for sanntidsgjenkjenning av objekter.

YOLOv7 : Relatert arbeid
Sanntidsgjenkjenning av objekter
YOLO er for tiden industristandarden, og de fleste sanntidsobjektdetektorer implementerer YOLO-algoritmer og FCOS (Fully Convolutional One-Stage Object-Detection). En toppmoderne sanntidsobjektdetektor har vanligvis følgende egenskaper
- Sterkere og raskere nettverksarkitektur.
- En effektiv funksjonsintegrasjonsmetode.
- En nøyaktig gjenstandsdeteksjonsmetode.
- En robust tapsfunksjon.
- En effektiv metode for etiketttildeling.
- En effektiv treningsmetode.
YOLOv7-algoritmen bruker ikke selvstyrte lærings- og destillasjonsmetoder som ofte krever store datamengder. Omvendt bruker YOLOv7-algoritmen en trenbar bag-of-freebie-metode.
Re-parameterisering av modellen
Modellreparameteriseringsteknikker blir sett på som en ensembleteknikk som slår sammen flere beregningsmoduler i et interferensstadium. Teknikken kan videre deles inn i to kategorier, ensemble på modellnivå, og ensemble på modulnivå.
Nå, for å oppnå den endelige interferensmodellen, bruker reparametriseringsteknikken på modellnivå to praksiser. Den første øvelsen bruker forskjellige treningsdata for å trene mange identiske modeller, og deretter gjennomsnittlig vektene til de trente modellene. Alternativt tar den andre praksisen gjennomsnittlig vekt på modellene under forskjellige iterasjoner.
Re-parametrisering på modulnivå har fått enorm popularitet nylig fordi den deler en modul i forskjellige modulgrener, eller forskjellige identiske grener under treningsfasen, og fortsetter deretter med å integrere disse forskjellige grenene i en ekvivalent modul mens interferens.
Re-parametriseringsteknikker kan imidlertid ikke brukes på alle typer arkitektur. Det er grunnen til at YOLOv7-algoritmen bruker nye modellreparameteriseringsteknikker for å designe relaterte strategier egnet for ulike arkitekturer.
Modellskalering
Modellskalering er prosessen med å skalere opp eller ned en eksisterende modell slik at den passer på tvers av forskjellige dataenheter. Modellskalering bruker vanligvis en rekke faktorer som antall lag(dybde), størrelse på inndatabilder (oppløsning), antall funksjonspyramider(scene), og antall kanaler(bredde). Disse faktorene spiller en avgjørende rolle for å sikre en balansert avveining for nettverksparametere, interferenshastighet, beregning og nøyaktighet av modellen.
En av de mest brukte skaleringsmetodene er NAS eller Network Architecture Search som automatisk søker etter passende skaleringsfaktorer fra søkemotorer uten noen kompliserte regler. Den største ulempen med å bruke NAS er at det er en kostbar tilnærming for å søke etter passende skaleringsfaktorer.
Nesten hver modellreparameteriseringsmodell analyserer individuelle og unike skaleringsfaktorer uavhengig, og optimaliserer til og med disse faktorene uavhengig. Det er fordi NAS-arkitekturen fungerer med ikke-korrelerte skaleringsfaktorer.
Det er verdt å merke seg at sammenkoblingsbaserte modeller liker VoVNet or DenseNet endre inngangsbredden til noen få lag når dybden på modellene skaleres. YOLOv7 jobber med en foreslått sammenkoblingsbasert arkitektur, og bruker derfor en sammensatt skaleringsmetode.

Figuren nevnt ovenfor sammenligner utvidede effektive lagaggregeringsnettverk (E-ELAN) av forskjellige modeller. Den foreslåtte E-ELAN-metoden opprettholder gradientoverføringsbanen til den opprinnelige arkitekturen, men tar sikte på å øke kardinaliteten til de ekstra funksjonene ved å bruke gruppekonvolusjon. Prosessen kan forbedre funksjonene som er lært av forskjellige kart, og kan ytterligere gjøre bruken av beregninger og parametere mer effektiv.
YOLOv7 arkitektur
YOLOv7-modellen bruker YOLOv4-, YOLO-R- og Scaled YOLOv4-modellene som base. YOLOv7 er et resultat av eksperimentene utført på disse modellene for å forbedre resultatene og gjøre modellen mer nøyaktig.
Extended Efficient Layer Aggregation Network eller E-ELAN
E-ELAN er den grunnleggende byggesteinen i YOLOv7-modellen, og den er avledet fra allerede eksisterende modeller for nettverkseffektivitet, hovedsakelig ELAN.
Hovedhensynene ved utforming av en effektiv arkitektur er antall parametere, beregningstetthet og mengden av beregninger. Andre modeller vurderer også faktorer som påvirkning av inngangs-/utgangskanalforhold, grener i arkitekturnettverket, nettverksinterferenshastighet, antall elementer i tensorene til konvolusjonelt nettverk og mer.
De CSPvoNet Modellen vurderer ikke bare de ovennevnte parameterne, men den analyserer også gradientbanen for å lære flere forskjellige funksjoner ved å aktivere vektene til forskjellige lag. Tilnærmingen gjør at interferensene kan være mye raskere og nøyaktige. De ELAN arkitektur tar sikte på å designe et effektivt nettverk for å kontrollere den korteste lengste gradientveien slik at nettverket kan være mer effektivt i læring og konvergering.
ELAN har allerede nådd et stabilt stadium uavhengig av stablingsantallet av beregningsblokker og gradientbanelengde. Den stabile tilstanden kan bli ødelagt hvis beregningsblokker stables ubegrenset, og parameterutnyttelsesgraden vil avta. De foreslått E-ELAN-arkitektur kan løse problemet ettersom den bruker utvidelse, stokking og sammenslåingskardinalitet å kontinuerlig forbedre nettverkets læringsevne og samtidig beholde den opprinnelige gradientbanen.
Videre, når man sammenligner arkitekturen til E-ELAN med ELAN, den eneste forskjellen er i beregningsblokken, mens overgangslagets arkitektur er uendret.
E-ELAN foreslår å utvide kardinaliteten til beregningsblokkene, og utvide kanalen ved å bruke gruppekonvolusjon. Funksjonskartet vil deretter bli beregnet og blandet inn i grupper i henhold til gruppeparameteren, og vil deretter settes sammen. Antall kanaler i hver gruppe vil forbli det samme som i den opprinnelige arkitekturen. Til slutt vil gruppene med funksjonskart legges til for å utføre kardinalitet.
Modellskalering for sammenkoblingsbaserte modeller
Modellskalering hjelper på justere attributter til modellene som hjelper med å generere modeller i henhold til kravene, og av forskjellige skalaer for å møte de forskjellige interferenshastighetene.

Figuren snakker om modellskalering for ulike sammenkoblingsbaserte modeller. Som du kan i figur (a) og (b), øker utgangsbredden til beregningsblokken med en økning i dybdeskaleringen til modellene. Som et resultat økes inngangsbredden til overføringslagene. Hvis disse metodene er implementert på sammenkoblingsbasert arkitektur, utføres skaleringsprosessen i dybden, og den er avbildet i figur (c).
Det kan derfor konkluderes med at det ikke er mulig å analysere skaleringsfaktorene uavhengig for sammenkoblingsbaserte modeller, og snarere må de vurderes eller analyseres sammen. Derfor, for en sammenkoblingsbasert modell, det er egnet å bruke den tilsvarende sammensatte modellskaleringsmetoden. I tillegg, når dybdefaktoren skaleres, må utgangskanalen til blokken også skaleres.
Trenbar bag med gratissaker
En pose gratis er et begrep som utviklere bruker for å beskrive et sett med metoder eller teknikker som kan endre treningsstrategien eller kostnadene i et forsøk på å øke modellens nøyaktighet. Så hva er disse trenbare sekkene med gratissaker i YOLOv7? La oss se.
Planlagt re-parameterisert konvolusjon
YOLOv7-algoritmen bruker gradientflyt-utbredelsesbaner for å bestemme hvordan man ideelt sett kombinerer et nettverk med den re-parametriserte konvolusjonen. Denne tilnærmingen til YOLov7 er et forsøk på å motvirke RepConv-algoritme som selv om den har prestert rolig på VGG-modellen, yter dårlig når den brukes direkte på DenseNet- og ResNet-modellene.
For å identifisere forbindelsene i et konvolusjonslag, RepConv-algoritmen kombinerer 3×3 konvolusjon og 1×1 konvolusjon. Hvis vi analyserer algoritmen, ytelsen og arkitekturen vil vi observere at RepConv ødelegger sammenkobling i DenseNet, og resten i ResNet.

Bildet ovenfor viser en planlagt re-parameterisert modell. Det kan sees at YOLov7-algoritmen fant at et lag i nettverket med sammenkobling eller restforbindelser ikke skulle ha en identitetsforbindelse i RepConv-algoritmen. Resultatet er at det er akseptabelt å bytte med RepConvN uten identitetsforbindelser.
Grov for Auxiliary og Fin for Lead Tap
Dyp tilsyn er en gren innen informatikk som ofte finner sin bruk i treningsprosessen til dype nettverk. Det grunnleggende prinsippet for dypt tilsyn er at det legger til et ekstra hjelpehode i de midtre lagene av nettverket sammen med de grunne nettverksvektene med assistenttap som guide. YOLOv7-algoritmen refererer til hodet som er ansvarlig for den endelige utgangen som hovedhodet, og hjelpehodet er hodet som hjelper til med trening.
YOLOv7 bruker en annen metode for etiketttildeling. Konvensjonelt har etiketttilordning blitt brukt til å generere etiketter ved å referere direkte til grunnsannheten, og på grunnlag av et gitt sett med regler. De siste årene har imidlertid distribusjonen og kvaliteten på prediksjonsinnspillet spilt en viktig rolle for å generere en pålitelig etikett. YOLOv7 genererer en myk etikett av objektet ved å bruke spådommene om grenseramme og grunnsannhet.
Videre bruker den nye etiketttilordningsmetoden til YOLOv7-algoritmen prediksjonshodets spådommer for å veilede både ledningen og hjelpehodet. Etiketttildelingsmetoden har to foreslåtte strategier.
Lead Head Guided Label Assigner
Strategien gjør beregninger på grunnlag av lederhodets prediksjonsresultater, og grunnsannheten, og bruker deretter optimalisering for å generere myke etiketter. Disse myke etikettene brukes deretter som treningsmodell for både hovedhodet og hjelpehodet.
Strategien fungerer ut fra en antagelse om at fordi hovedhodet har større læringsevne, bør etikettene den genererer være mer representative og korrelere mellom kilden og målet.
Grov-til-Fin Lead Head Guided Label Assigner
Denne strategien gjør også beregninger på grunnlag av lederhodets prediksjonsresultater, og grunnsannheten, og bruker deretter optimalisering for å generere myke etiketter. Det er imidlertid en nøkkelforskjell. I denne strategien er det to sett med myke etiketter, grovt nivå, og fin etikett.
Den grove etiketten genereres ved å slappe av begrensningene til den positive prøven
oppdragsprosess som behandler flere rutenett som positive mål. Det er gjort for å unngå risikoen for å miste informasjon på grunn av hjelpehodets svakere læringsstyrke.

Figuren ovenfor forklarer bruken av en trenbar pose med gratissaker i YOLOv7-algoritmen. Den viser grovt for hjelpehodet, og fint for blyhodet. Når vi sammenligner en modell med hjelpehode(b) med normalmodellen (a), vil vi se at skjemaet i (b) har et hjelpehode, mens det ikke er i (a).
Figur (c) viser den vanlige uavhengige etiketttildeleren, mens figur (d) og figur (e) representerer henholdsvis Lead Guided Assigner og Coarse-toFine Lead Guided Assigner brukt av YOLOv7.
Annen trenbar pose gratis
I tillegg til de som er nevnt ovenfor, bruker YOLOv7-algoritmen ekstra poser med gratissaker, selv om de ikke ble foreslått av dem opprinnelig. De er
- Batchnormalisering i Conv-Bn-Activation Technology: Denne strategien brukes til å koble et konvolusjonslag direkte til batchnormaliseringslaget.
- Implisitt kunnskap i YOLOR: YOLOv7 kombinerer strategien med Convolutional funksjonskart.
- EMA-modell: EMA-modellen brukes som en endelig referansemodell i YOLOv7, selv om dens primære bruk skal brukes i middellærermetoden.
YOLOv7 : Eksperimenter
Eksperimentell oppsett
YOLOv7-algoritmen bruker Microsoft COCO-datasett for opplæring og validering deres objektdeteksjonsmodell, og ikke alle disse eksperimentene bruker en forhåndstrent modell. Utviklerne brukte 2017-togdatasettet til opplæring, og brukte 2017-valideringsdatasettet for å velge hyperparametrene. Til slutt sammenlignes ytelsen til YOLOv7-objektdeteksjonsresultatene med toppmoderne algoritmer for objektdeteksjon.
Utviklere designet en grunnleggende modell for edge GPU (YOLOv7-liten), normal GPU (YOLOv7) og sky GPU (YOLOv7-W6). Videre bruker YOLOv7-algoritmen også en grunnleggende modell for modellskalering i henhold til ulike tjenestekrav, og får ulike modeller. For YOLOv7-algoritmen gjøres stabelskaleringen på halsen, og foreslåtte forbindelser brukes for å oppskalere dybden og bredden til modellen.
linjene
YOLOv7-algoritmen bruker tidligere YOLO-modeller, og YOLOR-objektdeteksjonsalgoritmen som grunnlinje.

Figuren ovenfor sammenligner grunnlinjen til YOLOv7-modellen med andre objektdeteksjonsmodeller, og resultatene er ganske tydelige. Sammenlignet med YOLOv4-algoritmen, YOLOv7 bruker ikke bare 75 % færre parametere, men den bruker også 15 % mindre beregning, og har 0.4 % høyere nøyaktighet.
Sammenligning med moderne objektdetektormodeller

Figuren ovenfor viser resultatene når YOLOv7 sammenlignes med toppmoderne objektdeteksjonsmodeller for mobile og generelle GPUer. Det kan observeres at metoden foreslått av YOLOv7-algoritmen har den beste avveiningsscore for hastighet og nøyaktighet.
Ablasjonsstudie: Foreslått sammensatt skaleringsmetode

Figuren vist ovenfor sammenligner resultatene ved bruk av ulike strategier for å skalere opp modellen. Skaleringsstrategien i YOLOv7-modellen skalerer opp dybden av beregningsblokken med 1.5 ganger, og skalerer bredden med 1.25 ganger.
Sammenlignet med en modell som bare skalerer opp dybden, yter YOLOv7-modellen bedre med 0.5 % mens den bruker færre parametere og regnekraft. På den annen side, sammenlignet med modeller som bare skalerer opp dybden, er YOLOv7s nøyaktighet forbedret med 0.2 %, men antallet parametere må skaleres med 2.9 % og beregningen med 1.2 %.
Foreslått planlagt re-parameterisert modell
For å bekrefte generaliteten til den foreslåtte re-parameteriserte modellen, YOLOv7-algoritmen bruker den på restbaserte og sammenkoblingsbaserte modeller for verifisering. For verifiseringsprosessen bruker YOLOv7-algoritmen 3-stablet ELAN for den sammenkoblingsbaserte modellen, og CSPDarknet for restbasert modell.
For den sammenkoblingsbaserte modellen erstatter algoritmen de 3×3 konvolusjonslagene i det 3-stablede ELANet med RepConv. Figuren nedenfor viser den detaljerte konfigurasjonen av Planned RepConv og 3-stablet ELAN.
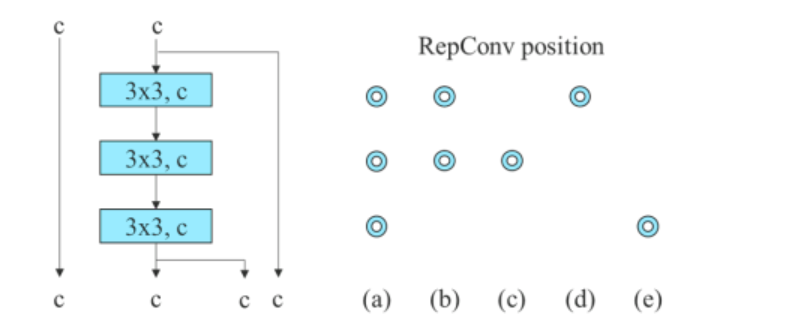
Videre, når man arbeider med den restbaserte modellen, bruker YOLOv7-algoritmen en reversert mørk blokk fordi den opprinnelige mørke blokken ikke har en 3×3 konvolusjonsblokk. Figuren nedenfor viser arkitekturen til Reversed CSPDarknet som reverserer posisjonene til 3×3 og 1×1 konvolusjonslaget. 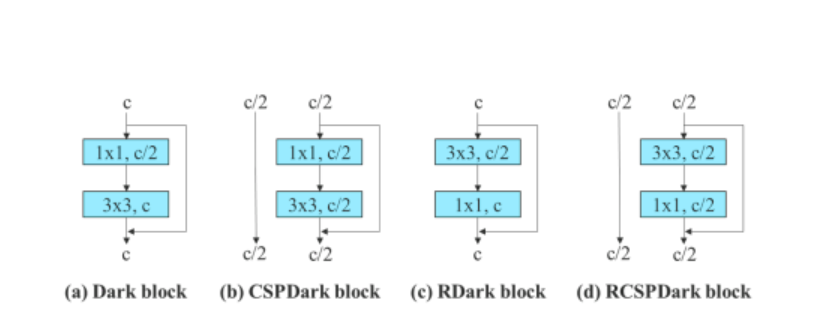
Foreslått assistenttap for hjelpeleder
For assistenttapet for hjelpehode, sammenligner YOLOv7-modellen den uavhengige etiketttilordningen for hjelpehode- og ledningshodemetodene.

Figuren ovenfor inneholder resultatene av studien på det foreslåtte hjelpehodet. Det kan sees at den generelle ytelsen til modellen øker med en økning i assistenttapet. Videre gir den veiledede etiketttildelingen som foreslås av YOLOv7-modellen bedre resultater enn uavhengige strategier for tildeling av ledere.
YOLOv7 resultater
Basert på eksperimentene ovenfor, her er resultatet av YOLov7s ytelse sammenlignet med andre objektdeteksjonsalgoritmer.

Figuren ovenfor sammenligner YOLOv7-modellen med andre objektdeteksjonsalgoritmer, og det kan tydelig observeres at YOLOv7 overgår andre innvendingsdeteksjonsmodeller mht. Gjennomsnittlig presisjon (AP) v/s batch interferens.
Videre sammenligner figuren nedenfor ytelsen til YOLOv7 v/s andre sanntidsinnvendingsdeteksjonsalgoritmer. Nok en gang, YOLOv7 etterfølger andre modeller når det gjelder den generelle ytelsen, nøyaktigheten og effektiviteten.

Her er noen tilleggsobservasjoner fra YOLOv7-resultatene og forestillingene.
- YOLOv7-Tiny er den minste modellen i YOLO-familien, med over 6 millioner parametere. YOLOv7-Tiny har en gjennomsnittlig presisjon på 35.2 %, og den overgår YOLOv4-Tiny-modellene med sammenlignbare parametere.
- YOLOv7-modellen har over 37 millioner parametere, og den overgår modeller med høyere parametere som YOLov4.
- YOLOv7-modellen har den høyeste mAP- og FPS-hastigheten i området 5 til 160 FPS.
konklusjonen
YOLO eller You Only Look Once er toppmoderne objektdeteksjonsmodell i moderne datasyn. YOLO-algoritmen er kjent for sin høye nøyaktighet og effektivitet, og som et resultat finner den omfattende bruk i sanntids-objektdeteksjonsindustrien. Helt siden den første YOLO-algoritmen ble introdusert tilbake i 2016, har eksperimenter gjort det mulig for utviklere å forbedre modellen kontinuerlig.
YOLOv7-modellen er det siste tilskuddet i YOLO-familien, og det er den kraftigste YOLo-algoritmen til dags dato. I denne artikkelen har vi snakket om det grunnleggende ved YOLOv7, og prøvd å forklare hva som gjør YOLOv7 så effektiv.















