Kunstig intelligens
Trening av datamodeller for maskinlæring på tilfeldig støy i stedet for ekte bilder

Forskere fra MIT Computer Science & Artificial Intelligence Laboratory (CSAIL) har eksperimentert med å bruke tilfeldig støybilder i datamodeller for maskinlæring til å trene datamodeller for maskinlæring, og har funnet at i stedet for å produsere avfall, er metoden overraskende effektiv:

Generative modeller fra eksperimentet, sortert etter ytelse. Source: https://openreview.net/pdf?id=RQUl8gZnN7O
Å mata inn åpenbart ‘visuelt avfall’ i populære datamodeller for maskinlæring burde ikke resultere i denne type ytelse. På den ytterste høyresiden av bildet ovenfor, representerer de svarte søylene nøyaktighetspoeng (på Imagenet-100) for fire ‘ekte’ datamodeller. Mens ’tilfeldig støy’-datamodellene som kommer før det (avbildet i forskjellige farger, se indeks øverst til venstre) ikke kan matche det, er de nesten alle innen respektabelle øvre og nedre grenser (røde strekte linjer) for nøyaktighet.
I denne forstand betyr ‘nøyaktighet’ ikke at et resultat nødvendigvis ligner et ansikt, en kirke, en pizza eller noe annet bestemt domene for hvilket du måtte være interessert i å lage et bilde-syntese-system, slik som en Generative Adversarial Network eller en encoder/decoder-ramme.
Snarere betyr det at CSAIL-modellene har avledet bredt anvendelige sentrale ‘sannheter’ fra bilde-data som åpenbart er så ustrukturert at det ikke burde være i stand til å levere det.
Mangfold Vs. Naturalisme
Heller kan disse resultater ikke tilskrives over-tilpasning: en livlig diskusjon mellom forfatterne og reviewerne på Open Review avslører at å blande forskjellig innhold fra visuelt mangfoldige datamodeller (slik som ‘døde blader’, ‘fraktaler’ og ‘prosedur-basert støy’ – se bilde under) inn i en trening-dataset forbedrer faktisk nøyaktigheten i disse eksperimentene.
Dette antyder (og det er en litt revolusjonerende forestilling) en ny type ‘under-tilpasning’, hvor ‘mangfold’ slår ‘naturalisme’.
Prosjekt-siden for initiativet lar deg interaktivt se på de forskjellige typene tilfeldige bilde-datasett som ble brukt i eksperimentet. Source: https://mbaradad.github.io/learning_with_noise/
Resultatene som er oppnådd av forskerne, setter spørsmål ved den grunnleggende relasjonen mellom bilde-baserte neurale nettverk og ‘den virkelige verden’-bilder som kastes på dem i alarmingly større volum hvert år, og antyder at behovet for å skaffe, kuratere og på annen måte håndtere hyperskala-bilde-datasett måtte bli redundant. Forfatterne skriver:
‘Aktuelle visjonssystemer er trenet på enorme datasett, og disse datasettene kommer med kostnader: kuratering er dyrt, de arver menneskelige fordommer, og det er bekymringer over personvern og bruksrettigheter. For å motvirke disse kostnadene, har interessen økt i å lære fra billigere datakilder, som ubeskrivende bilder.’
‘I denne artikkelen går vi et skritt videre og spør om vi kan gjøre uten ekte bilde-datasett helt, ved å lære fra prosedyre-basert støy-prosesser.’
Forskerne foreslår at den nåværende avlingen av maskinlærings-arkitekturer måtte kunne slutte noe langt mer grunnleggende (eller, i alle fall, uventet) fra bilder enn det som tidligere var tenkt, og at ‘tull’-bilder potensielt kan gi mye av denne kunnskapen mye billigere, selv med mulig bruk av ad hoc syntetisk data, via datasett-genererings-arkitekturer som genererer tilfeldige bilder under trening:
‘Vi identifiserer to nøkkel-egenskaper som gjør god syntetisk data for å trene visjonssystemer: 1) naturalisme, 2) mangfold. Interessant nok er det mest naturalistiske datasett ikke alltid det beste, siden naturalisme kan komme på bekostning av mangfold.
‘Det faktum at naturalistiske data hjelper, kan ikke være overraskende, og det antyder at større skala virkelig data har verdi. Imidlertid finner vi at det som er avgjørende, er ikke at dataene er ekte, men at de er naturalistiske, dvs. de må fange visse struktur-egenskaper av ekte data.
‘Mange av disse egenskapene kan fanges i enkle støy-modeller.’

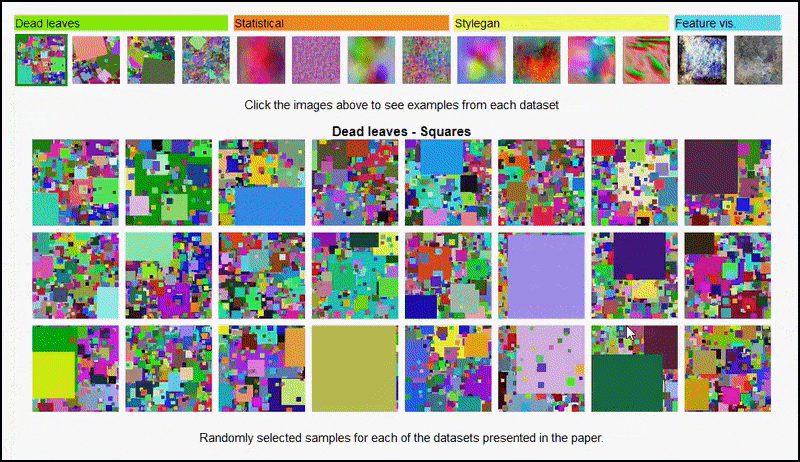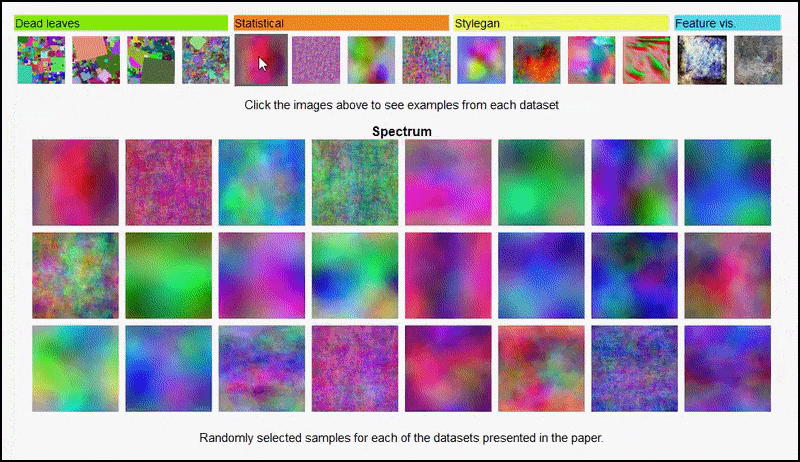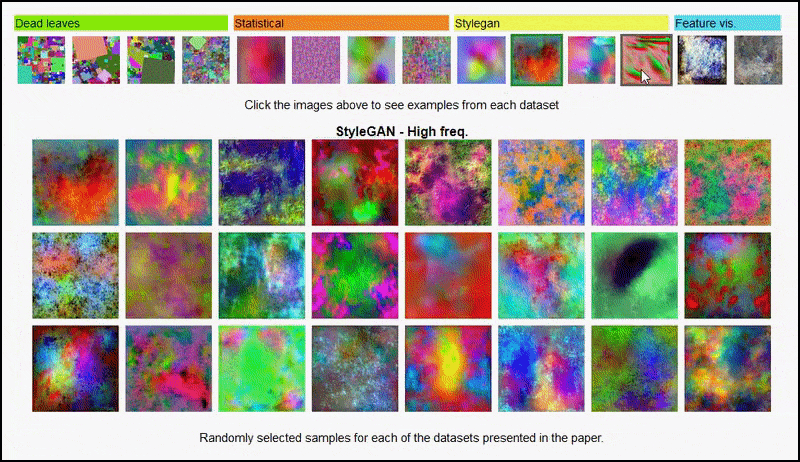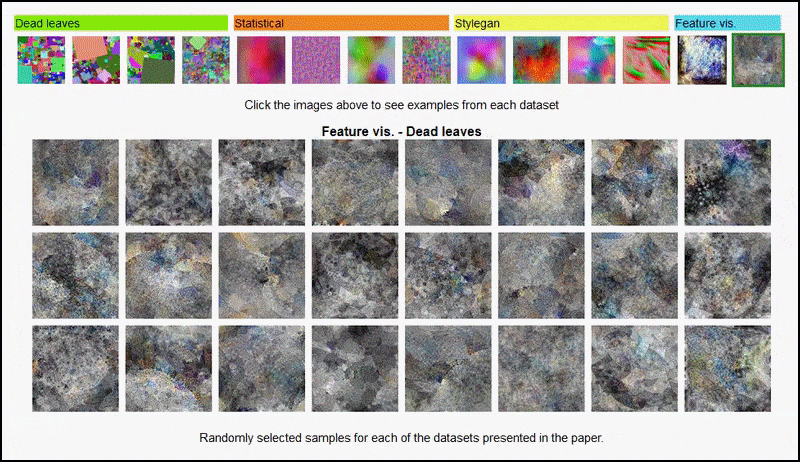
Funksjons-visualiseringer som resulterer fra en AlexNet-avledet encoder på noen av de forskjellige ’tilfeldige bilde’-datasettene som ble brukt av forfatterne, dekkende 3. og 5. (siste) konvolusjonslag. Metodikken som ble brukt her, følger det som er fastsatt i Google AI-forskning fra 2017.
Den artikkelen, presentert på 35. konferansen om neurale informasjonsbehandlings-systemer (NeurIPS 2021) i Sydney, har tittelen Learning to See by Looking at Noise, og kommer fra seks forskere ved CSAIL, med likeverdig bidrag.
Arbeidet ble anbefalt av konsensus for en spotlight-seleksjon på NeurIPS 2021, med peer-kommentatorer som karakteriserer artikkelen som ‘en vitenskapelig gjennombrudd’ som åpner opp et ‘stort studie-område’, selv om det reiser like mange spørsmål som det besvarer.
I artikkelen konkluderer forfatterne:
‘Vi har vist at, når de er designet ved hjelp av resultater fra tidligere forskning på naturlige bilde-statistikk, disse datasettene kan suksessfullt trene visuelle representasjoner. Vi håper at denne artikkelen vil motivere studiet av nye generative modeller som kan produsere strukturert støy som oppnår enda bedre ytelse når de brukes i en mangfoldig samling av visuelle oppgaver.
‘Ville det være mulig å matche ytelsen som er oppnådd med ImageNet-forhåndstrening? Kanskje i fravær av en stor trenings-datasett spesifikt for en bestemt oppgave, er den beste forhåndstrenings-metoden kanskje ikke å bruke et standard-reelt datasett som ImageNet.’












