
Best av
10 beste maskinlæringsalgoritmer
Selv om vi lever gjennom en tid med ekstraordinær innovasjon innen GPU-akselerert maskinlæring, inneholder de siste forskningsartikler ofte (og fremtredende) algoritmer som er tiår, i visse tilfeller 70 år gamle.
Noen vil kanskje hevde at mange av disse eldre metodene faller inn i leiren for 'statistisk analyse' snarere enn maskinlæring, og foretrekker å datere fremkomsten av sektoren så langt tilbake som 1957, med oppfinnelsen av Perceptron.
Gitt i hvilken grad disse eldre algoritmene støtter og er innblandet i de siste trendene og overskriftsfengende utviklingen innen maskinlæring, er det en omstridt holdning. Så la oss ta en titt på noen av de "klassiske" byggeklossene som ligger til grunn for de siste innovasjonene, samt noen nyere oppføringer som gir et tidlig bud på AI Hall of Fame.
1: Transformatorer
I 2017 ledet Google Research et forskningssamarbeid som kulminerte med papir Oppmerksomhet er alt du trenger. Verket skisserte en ny arkitektur som fremmet oppmerksomhetsmekanismer fra 'piping' i koder/dekoder og tilbakevendende nettverksmodeller til en sentral transformasjonsteknologi i seg selv.
Tilnærmingen ble kalt Transformator, og har siden blitt en revolusjonerende metodikk innen Natural Language Processing (NLP), som blant mange andre eksempler driver den autoregressive språkmodellen og AI-plakat-barn GPT-3.
![]()
Transformatorer løste elegant problemet med sekvenstransduksjon, også kalt 'transformasjon', som er opptatt med prosessering av inngangssekvenser til utgangssekvenser. En transformator mottar og administrerer også data på en kontinuerlig måte, snarere enn i sekvensielle grupper, noe som tillater en "vedvarende minne" som RNN-arkitekturer ikke er designet for å oppnå. For en mer detaljert oversikt over transformatorer, ta en titt på vår referanseartikkel.
I motsetning til de tilbakevendende nevrale nettverkene (RNN) som hadde begynt å dominere ML-forskning i CUDA-tiden, kunne transformatorarkitektur også være lett parallellisert, åpner veien for produktivt å adressere et langt større korpus av data enn RNN-er.
Populær bruk
Transformers fanget publikums fantasi i 2020 med utgivelsen av OpenAIs GPT-3, som kunne skryte av en rekordstor 175 milliarder parametere. Denne tilsynelatende svimlende prestasjonen ble til slutt overskygget av senere prosjekter, som 2021 slipp av Microsofts Megatron-Turing NLG 530B, som (som navnet antyder) har over 530 milliarder parametere.

En tidslinje med hyperskala Transformer NLP-prosjekter. kilde: Microsoft
Transformatorarkitektur har også gått over fra NLP til datasyn, og driver en ny generasjon av rammeverk for bildesyntese som OpenAI's CLIP og DALL-E, som bruker tekst>bildedomenekartlegging for å fullføre ufullstendige bilder og syntetisere nye bilder fra opplærte domener, blant et økende antall relaterte applikasjoner.

DALL-E prøver å fullføre et delvis bilde av en byste av Platon. Kilde: https://openai.com/blog/dall-e/
2: Generative Adversarial Networks (GAN)
Selv om transformatorer har fått ekstraordinær mediedekning gjennom utgivelsen og adopsjonen av GPT-3, er den Generativ motstandernettverk (GAN) har blitt et gjenkjennelig merke i seg selv, og kan etter hvert bli med deepfake som et verb.
Først foreslått i 2014 og primært brukt til bildesyntese, et Generative Adversarial Network arkitektur er sammensatt av en Generator og en Diskriminator. Generatoren går gjennom tusenvis av bilder i et datasett, og prøver iterativt å rekonstruere dem. For hvert forsøk graderer Diskriminatoren Generatorens arbeid, og sender Generatoren tilbake for å gjøre det bedre, men uten noen innsikt i måten den forrige rekonstruksjonen tok feil på.

Kilde: https://developers.google.com/machine-learning/gan/gan_structure
Dette tvinger Generatoren til å utforske en rekke veier, i stedet for å følge de potensielle blindgatene som ville ha resultert hvis Diskriminatoren hadde fortalt den hvor det gikk galt (se #8 nedenfor). Når treningen er over, har Generatoren et detaljert og omfattende kart over forhold mellom punkter i datasettet.

Fra avisen Forbedring av GAN-likevekt ved å øke romlig bevissthet: et nytt rammeverk går gjennom det til tider mystiske latente rommet til en GAN, og gir responsiv instrumentalitet for en bildesyntesearkitektur. Kilde: https://genforce.github.io/eqgan/
I analogi er dette forskjellen mellom å lære en enkel pendling til London sentrum, eller møysommelig skaffe seg Kunnskapen.
Resultatet er en samling av funksjoner på høyt nivå i det latente rommet til den trente modellen. Den semantiske indikatoren for en funksjon på høyt nivå kan være "person", mens en nedstigning gjennom spesifisitet relatert til funksjonen kan avdekke andre lærte egenskaper, for eksempel "mann" og "kvinne". På lavere nivåer kan underfunksjonene brytes ned til 'blond', 'kaukasisk', et al.
Forvikling er et bemerkelsesverdig problem i det latente rommet til GAN-er og koder/dekoder-rammeverk: er smilet på et GAN-generert kvinneansikt et sammenfiltret trekk ved hennes 'identitet' i det latente rommet, eller er det en parallell gren?

GAN-genererte ansikter fra denne personen eksisterer ikke. Kilde: https://this-person-does-not-exist.com/en
De siste par årene har ført frem et økende antall nye forskningsinitiativer i denne forbindelse, kanskje banet vei for funksjonsnivå, Photoshop-stil redigering for det latente rommet til en GAN, men for øyeblikket er mange transformasjoner effektivt ' alt eller ingenting-pakker. Spesielt oppnår NVIDIAs EditGAN-utgivelse fra slutten av 2021 en høy grad av tolkbarhet i det latente rommet ved å bruke semantiske segmenteringsmasker.
Populær bruk
Ved siden av deres (faktisk ganske begrensede) involvering i populære dypfalske videoer, har bilde-/videosentrerte GAN-er spredt seg i løpet av de siste fire årene, og trollbundet både forskere og publikum. Å holde tritt med den svimlende hastigheten og frekvensen av nye utgivelser er en utfordring, selv om GitHub-depotet Fantastiske GAN-applikasjoner har som mål å gi en omfattende liste.
Generative kontradiktoriske nettverk kan i teorien utlede trekk fra ethvert godt innrammet domene, inkludert tekst.
3: SVM
opprinnelse i 1963, Støtt vektormaskin (SVM) er en kjernealgoritme som dukker opp ofte i ny forskning. Under SVM kartlegger vektorer den relative disponeringen av datapunkter i et datasett, mens støtte vektorer avgrenser grensene mellom ulike grupper, funksjoner eller egenskaper.
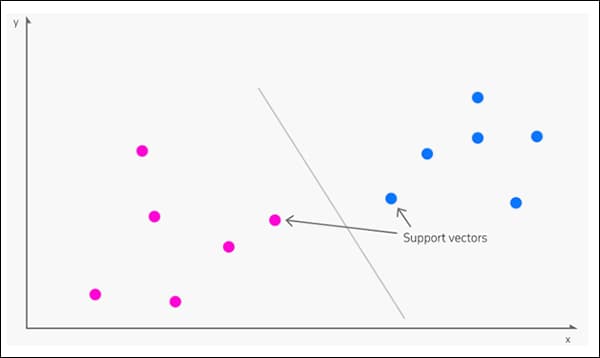
Støttevektorer definerer grensene mellom grupper. Kilde: https://www.kdnuggets.com/2016/07/support-vector-machines-simple-explanation.html
Den avledede grensen kalles a hyper.
Ved lave funksjonsnivåer er SVM todimensjonal (bilde over), men der det er et høyere anerkjent antall grupper eller typer, blir det tredimensjonal.

En dypere rekke punkter og grupper krever en tredimensjonal SVM. Kilde: https://cml.rhul.ac.uk/svm.html
Populær bruk
Siden støtte Vector Machines effektivt og agnostisk kan adressere høydimensjonale data av mange slag, dukker de opp bredt på tvers av en rekke maskinlæringssektorer, inkludert deepfake deteksjon, bildeklassifisering, klassifisering av hatefulle ytringer, DNA analyse og befolkningsstruktur prediksjon, blant mange andre.
4: K-Means Clustering
Clustering generelt er en uovervåket læring tilnærming som søker å kategorisere datapunkter gjennom estimering av tetthet, lage et kart over distribusjonen av dataene som studeres.

K-Betyr gruppering av guddommelige segmenter, grupper og samfunn i data. Kilde: https://aws.amazon.com/blogs/machine-learning/k-means-clustering-with-amazon-sagemaker/
K-Betyr gruppering har blitt den mest populære implementeringen av denne tilnærmingen, og gjeterdata peker inn i særegne 'K-grupper', som kan indikere demografiske sektorer, nettsamfunn eller annen mulig hemmelig aggregering som venter på å bli oppdaget i rå statistiske data.

Klynger dannes i K-Means-analyse. Kilde: https://www.geeksforgeeks.org/ml-determine-the-optimal-value-of-k-in-k-means-clustering/
K-verdien i seg selv er den avgjørende faktoren for nytten av prosessen, og for å etablere en optimal verdi for en klynge. Til å begynne med tildeles K-verdien tilfeldig, og dens funksjoner og vektorkarakteristikker sammenlignet med naboene. De naboene som ligner mest på datapunktet med den tilfeldig tildelte verdien, blir tildelt klyngen iterativt inntil dataene har gitt alle grupperingene som prosessen tillater.
Plottet for kvadratfeilen, eller 'kostnaden' for forskjellige verdier blant klyngene vil avsløre en albuepunkt for dataene:

'Albuepunktet' i en klyngegraf. Kilde: https://www.scikit-yb.org/en/latest/api/cluster/elbow.html
Albuepunktet ligner i konseptet måten tap flater ut til avtagende avkastning på slutten av en treningsøkt for et datasett. Det representerer punktet der ingen ytterligere forskjeller mellom grupper kommer til å bli synlige, og indikerer øyeblikket for å gå videre til påfølgende faser i datapipelinen, eller for å rapportere funn.
Populær bruk
K-Means Clustering er av åpenbare grunner en primær teknologi i kundeanalyse, siden den tilbyr en klar og forklarlig metodikk for å oversette store mengder kommersielle poster til demografisk innsikt og "leads".
Utenom denne applikasjonen er K-Means Clustering også ansatt for skredprediksjon, medisinsk bildesegmentering, bildesyntese med GAN-er, dokumentklassifiseringog byplanlegging, blant mange andre potensielle og faktiske bruksområder.
5: Tilfeldig skog
Random Forest er en ensemble læring metode som gir gjennomsnitt av resultatet fra en rekke avgjørelse trær å etablere en samlet prediksjon for utfallet.

Kilde: https://www.tutorialandexample.com/wp-content/uploads/2019/10/Decision-Trees-Root-Node.png
Hvis du har undersøkt det så lite som å se på Tilbake til fremtiden trilogien er et beslutningstre i seg selv ganske enkelt å konseptualisere: en rekke veier ligger foran deg, og hver vei forgrener seg til et nytt utfall som igjen inneholder flere mulige veier.
In forsterkning læring, kan du trekke deg tilbake fra en sti og starte på nytt fra en tidligere holdning, mens beslutningstrær forplikter seg til sine reiser.
Dermed er Random Forest-algoritmen i hovedsak spread-betting for beslutninger. Algoritmen kalles "tilfeldig" fordi den lager ad hoc utvalg og observasjoner for å forstå median summen av resultatene fra beslutningstreet.
Siden den tar hensyn til en rekke faktorer, kan en Random Forest-tilnærming være vanskeligere å konvertere til meningsfulle grafer enn et beslutningstre, men vil sannsynligvis være spesielt mer produktiv.
Beslutningstrær er gjenstand for overtilpasning, der resultatene som oppnås er dataspesifikke og sannsynligvis ikke vil generalisere. Random Forests vilkårlige utvalg av datapunkter bekjemper denne tendensen, og går gjennom til meningsfulle og nyttige representative trender i dataene.

Regresjon av beslutningstre. Kilde: https://scikit-learn.org/stable/auto_examples/tree/plot_tree_regression.html
Populær bruk
Som med mange av algoritmene i denne listen, fungerer Random Forest vanligvis som en "tidlig" sorterer og filter av data, og dukker som sådan konsekvent opp i nye forskningsartikler. Noen eksempler på Random Forest-bruk inkluderer Magnetisk resonans bildesyntese, Bitcoin-prediksjon, folketelling segmentering, tekst klassifisering og oppdage kredittkortsvindel.
Siden Random Forest er en lavnivåalgoritme i maskinlæringsarkitekturer, kan den også bidra til ytelsen til andre lavnivåmetoder, samt visualiseringsalgoritmer, bl.a. Induktiv klynging, Funksjonstransformasjoner, klassifisering av tekstdokumenter bruker sparsomme funksjonerog viser rørledninger.
6: Naive Bayes
Sammen med tetthetsestimering (se 4, ovenfor), a naive Bayes klassifiserer er en kraftig, men relativt lett algoritme som er i stand til å estimere sannsynligheter basert på de beregnede egenskapene til data.

Vis relasjoner i en naiv Bayes-klassifiser. Kilde: https://www.sciencedirect.com/topics/computer-science/naive-bayes-model
Begrepet "naiv" refererer til antagelsen i Bayes' teorem at funksjoner ikke er relatert, kjent som betinget uavhengighet. Hvis du inntar dette standpunktet, er det ikke nok å gå og snakke som en and til å fastslå at vi har å gjøre med en and, og ingen "åpenbare" antakelser blir overtatt for tidlig.
Dette nivået av akademisk og etterforskningsmessig strenghet ville være overkill der "sunn fornuft" er tilgjengelig, men er en verdifull standard når man krysser de mange tvetydighetene og potensielt urelaterte korrelasjonene som kan eksistere i et maskinlæringsdatasett.
I et originalt Bayesiansk nettverk er funksjoner underlagt skåringsfunksjoner, inkludert minimal beskrivelseslengde og Bayesiansk scoring, som kan legge begrensninger på dataene når det gjelder de estimerte forbindelsene som er funnet mellom datapunktene, og retningen disse forbindelsene flyter i.
En naiv Bayes-klassifikator, omvendt, opererer ved å anta at egenskapene til et gitt objekt er uavhengige, og bruker deretter Bayes' teorem for å beregne sannsynligheten for et gitt objekt, basert på dets egenskaper.
Populær bruk
Naive Bayes-filtre er godt representert i sykdomsprediksjon og dokumentkategorisering, spamfiltrering, følelsesklassifisering, anbefalingssystemerog svindeloppdagelse, blant andre applikasjoner.
7: K- Nærmeste naboer (KNN)
Først foreslått av US Air Force School of Aviation Medicine i 1951, og å måtte tilpasse seg det siste innen datamaskinvare fra midten av 20-tallet, K-nærmeste naboer (KNN) er en slank algoritme som fortsatt har en fremtredende plass på tvers av akademiske artikler og forskningsinitiativer for maskinlæring i privat sektor.
KNN har blitt kalt 'den late lærende', siden det uttømmende skanner et datasett for å evaluere relasjonene mellom datapunkter, i stedet for å kreve opplæring av en fullverdig maskinlæringsmodell.

En KNN-gruppering. Kilde: https://scikit-learn.org/stable/modules/neighbors.html
Selv om KNN er slank arkitektonisk, stiller dens systematiske tilnærming et bemerkelsesverdig krav til lese-/skriveoperasjoner, og bruken i svært store datasett kan være problematisk uten tilleggsteknologier som Principal Component Analysis (PCA), som kan transformere komplekse og høyvolumsdatasett. inn i representative grupperinger at KNN kan krysse med mindre innsats.
A fersk undersøkelse evaluerte effektiviteten og økonomien til en rekke algoritmer som har til oppgave å forutsi om en ansatt vil forlate et selskap, og fant ut at Septuagenarian KNN forble overlegen mer moderne utfordrere når det gjelder nøyaktighet og prediktiv effektivitet.
Populær bruk
På tross av all sin populære enkelhet i konsept og utførelse, sitter ikke KNN fast på 1950-tallet – det har blitt tilpasset til en mer DNN-fokusert tilnærming i et 2018-forslag fra Pennsylvania State University, og er fortsatt en sentral tidligfaseprosess (eller analytisk etterbehandlingsverktøy) i mange langt mer komplekse maskinlæringsrammer.
I ulike konfigurasjoner har KNN vært brukt eller for online signaturverifisering, bildeklassifisering, tekst gruvedrift, avlingsprediksjonog ansiktsgjenkjenning, i tillegg til andre applikasjoner og inkorporeringer.

Et KNN-basert ansiktsgjenkjenningssystem under trening. Source: https://pdfs.semanticscholar.org/6f3d/d4c5ffeb3ce74bf57342861686944490f513.pdf
8: Markov Decision Process (MDP)
Et matematisk rammeverk introdusert av den amerikanske matematikeren Richard Bellman i 1957, Markov Decision Process (MDP) er en av de mest grunnleggende blokkene i forsterkning læring arkitekturer. En konseptuell algoritme i seg selv, den har blitt tilpasset til et stort antall andre algoritmer, og går ofte igjen i den nåværende avlingen av AI/ML-forskning.
MDP utforsker et datamiljø ved å bruke evalueringen av dets nåværende tilstand (dvs. "hvor" det er i dataene) for å bestemme hvilken node av dataene som skal utforskes neste gang.

Kilde: https://www.sciencedirect.com/science/article/abs/pii/S0888613X18304420
En grunnleggende Markov-beslutningsprosess vil prioritere fordeler på kort sikt fremfor mer ønskelige langsiktige mål. Av denne grunn er det vanligvis innebygd i konteksten av en mer omfattende policyarkitektur innen forsterkningslæring, og er ofte underlagt begrensende faktorer som f.eks. rabattert belønning, og andre modifiserende miljøvariabler som vil hindre den i å skynde seg til et umiddelbar mål uten å ta hensyn til det bredere ønskete resultatet.
Populær bruk
MDPs lavnivåkonsept er utbredt i både forskning og aktiv distribusjon av maskinlæring. Det er foreslått for IoT sikkerhetsforsvarssystemer, høsting av fiskog markedsprognoser.
Foruten det åpenbar anvendelighet til sjakk og andre strengt sekvensielle spill, er MDP også en naturlig konkurrent for prosedyreopplæring av robotsystemer, som vi kan se i videoen nedenfor.

9: Term Frequency-Invers Document Frequency
Termhyppighet (TF) deler antall ganger et ord vises i et dokument med det totale antallet ord i det dokumentet. Altså ordet forsegle som vises én gang i en tusenordsartikkel har en termfrekvens på 0.001. I seg selv er TF stort sett ubrukelig som en indikator på begrepets betydning, på grunn av at meningsløse artikler (som f.eks. a, og, deog it) fremherske.
For å få en meningsfull verdi for et begrep, beregner Inverse Document Frequency (IDF) TF for et ord på tvers av flere dokumenter i et datasett, og tildeler lav vurdering til svært høy frekvens stoppord, for eksempel artikler. De resulterende egenskapsvektorene normaliseres til hele verdier, med hvert ord tildelt en passende vekt.

TF-IDF vekter relevansen av termer basert på frekvens på tvers av en rekke dokumenter, med sjeldnere forekomst en indikator på fremtredende. Kilde: https://moz.com/blog/inverse-document-frequency-and-the-importance-of-uniqueness
Selv om denne tilnærmingen forhindrer at semantisk viktige ord går tapt som uteliggere, invertering av frekvensvekten betyr ikke automatisk at en lavfrekvent term er ikke en uteligger, fordi noen ting er sjeldne og verdiløs. Derfor vil et lavfrekvent begrep måtte bevise sin verdi i den bredere arkitektoniske konteksten ved å presentere (selv med lav frekvens per dokument) i en rekke dokumenter i datasettet.
Til tross for det alder, TF-IDF er en kraftig og populær metode for innledende filtreringspass i Natural Language Processing-rammeverk.
Populær bruk
Fordi TF-IDF i det minste har spilt en del i utviklingen av Googles stort sett okkulte PageRank-algoritme de siste tjue årene, har det blitt svært bredt vedtatt som en manipulerende SEO-taktikk, til tross for John Muellers 2019 avvisning av dens betydning for søkeresultatene.
På grunn av hemmeligholdet rundt PageRank er det ingen klare bevis for at TF-IDF er det ikke for tiden en effektiv taktikk for å øke i Googles rangeringer. Brennende diskusjon blant IT-fagfolk nylig indikerer en populær forståelse, riktig eller ikke, at begrepsmisbruk fortsatt kan resultere i forbedret SEO-plassering (selv om ytterligere anklager om monopolmisbruk og overdreven reklame viske ut grensene for denne teorien).
10: Stokastisk gradientnedstigning
Stokastisk gradientnedstigning (SGD) er en stadig mer populær metode for å optimalisere opplæringen av maskinlæringsmodeller.
Gradient Descent i seg selv er en metode for å optimalisere og deretter kvantifisere forbedringen som en modell gjør under trening.
I denne forstand indikerer 'gradient' en skråning nedover (i stedet for en fargebasert gradering, se bildet nedenfor), der det høyeste punktet på 'bakken', til venstre, representerer begynnelsen av treningsprosessen. På dette stadiet har modellen ennå ikke sett hele dataene en gang, og har ikke lært nok om forhold mellom dataene til å produsere effektive transformasjoner.

En gradientnedstigning på en FaceSwap-treningsøkt. Vi kan se at treningen har platået en stund i andre omgang, men har etter hvert kommet seg nedover stigningen mot en akseptabel konvergens.
Det laveste punktet, til høyre, representerer konvergens (punktet der modellen er like effektiv som den noen gang kommer til å komme under de pålagte begrensningene og innstillingene).
Gradienten fungerer som en registrering og prediktor for forskjellen mellom feilraten (hvor nøyaktig modellen har kartlagt datarelasjonene) og vektene (innstillingene som påvirker måten modellen vil lære på).
Denne oversikten over fremdrift kan brukes til å informere en læringshastighetsplan, en automatisk prosess som forteller at arkitekturen skal bli mer detaljert og presis når de tidlige vage detaljene forvandles til klare relasjoner og kartlegginger. I realiteten gir gradienttap et just-in-time kart over hvor treningen skal gå videre, og hvordan den skal fortsette.
Innovasjonen til Stochastic Gradient Descent er at den oppdaterer modellens parametere på hvert treningseksempel per iterasjon, noe som generelt setter fart på reisen til konvergens. På grunn av bruken av hyperskala datasett de siste årene, har SGD vokst i popularitet i det siste som en mulig metode for å løse de påfølgende logistiske problemene.
På den annen side har SGD negative implikasjoner for funksjonsskalering, og kan kreve flere iterasjoner for å oppnå samme resultat, noe som krever ekstra planlegging og tilleggsparametere, sammenlignet med vanlig gradientnedstigning.
Populær bruk
På grunn av dens konfigurerbarhet, og til tross for dens mangler, har SGD blitt den mest populære optimaliseringsalgoritmen for å tilpasse nevrale nettverk. En konfigurasjon av SGD som er i ferd med å bli dominerende i nye AI/ML-forskningsartikler er valget av Adaptive Moment Estimation (ADAM, introdusert i 2015) optimizer.
ADAM tilpasser læringsraten for hver parameter dynamisk ('adaptive learning rate'), i tillegg til å inkludere resultater fra tidligere oppdateringer i den påfølgende konfigurasjonen ('momentum'). I tillegg kan den konfigureres til å bruke senere innovasjoner, som f.eks Nesterov Momentum.
Noen hevder imidlertid at bruk av momentum også kan fremskynde ADAM (og lignende algoritmer) til en suboptimal konklusjon. Som med det meste av spredningen av maskinlæringsforskningssektoren, er SGD et arbeid som pågår.
Først publisert 10. februar 2022. Endret 10. februar 20.05 EET – formatering.















