
Artificial Intelligence
Computer Vision-modellen trainen op willekeurige ruis in plaats van echte beelden

Onderzoekers van het MIT Computer Science & Artificial Intelligence Laboratory (CSAIL) hebben geëxperimenteerd met het gebruik van willekeurige ruisbeelden in computer vision-datasets om computer vision-modellen te trainen, en hebben ontdekt dat de methode verrassend effectief is in plaats van afval te produceren:

Generatieve modellen uit het experiment, gesorteerd op prestatie. Bron: https://openreview.net/pdf?id=RQUl8gZnN7O
Het voeden van ogenschijnlijk 'visueel afval' in populaire computer vision-architecturen zou niet moeten resulteren in dit soort prestaties. Uiterst rechts in de bovenstaande afbeelding geven de zwarte kolommen de nauwkeurigheidsscores weer (op Imagenet-100) voor vier 'echte' datasets. Hoewel de 'willekeurige ruis'-datasets die eraan voorafgingen (afgebeeld in verschillende kleuren, zie index linksboven) daar niet aan kunnen tippen, vallen ze qua nauwkeurigheid bijna allemaal binnen respectabele boven- en ondergrenzen (rode stippellijnen).
In die zin betekent 'nauwkeurigheid' niet dat een resultaat noodzakelijkerwijs op een lijkt gezichtsverzorging, een kerk, een pizza, of een ander specifiek domein waarvoor u mogelijk geïnteresseerd bent in het maken van een beeld synthese systeem, zoals een Generative Adversarial Network of een encoder/decoder-framework.
Het betekent veeleer dat de CSAIL-modellen breed toepasbare centrale 'waarheden' hebben afgeleid uit beeldgegevens die zo ogenschijnlijk ongestructureerd zijn dat ze die niet zouden kunnen leveren.
Diversiteit vs. Naturalisme
Ook kunnen deze resultaten niet worden toegeschreven overmaats: een levendig discussie tussen de auteurs en recensenten bij Open Review onthult dat het mixen van verschillende inhoud van visueel diverse datasets (zoals 'dode bladeren', 'fractals' en 'procedurele ruis' - zie onderstaande afbeelding) in een trainingsdataset werkelijk verbetert nauwkeurigheid bij deze experimenten.
Dit suggereert (en het is een beetje een revolutionaire notie) een nieuw soort 'ondermaats', waarbij 'diversiteit' boven 'naturalisme' gaat.
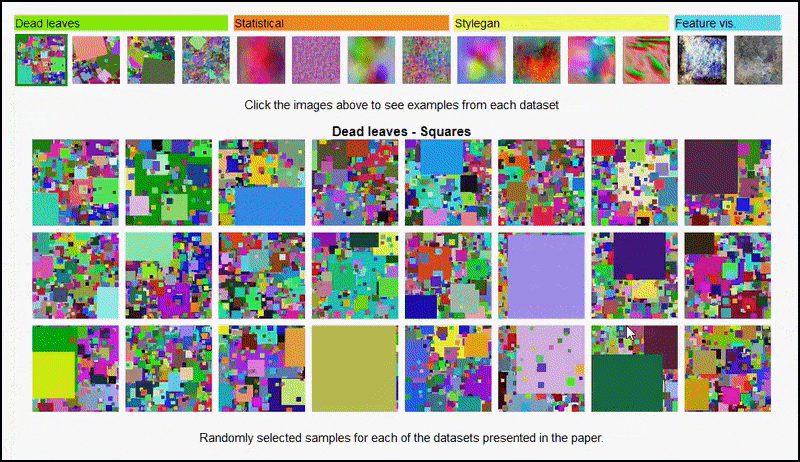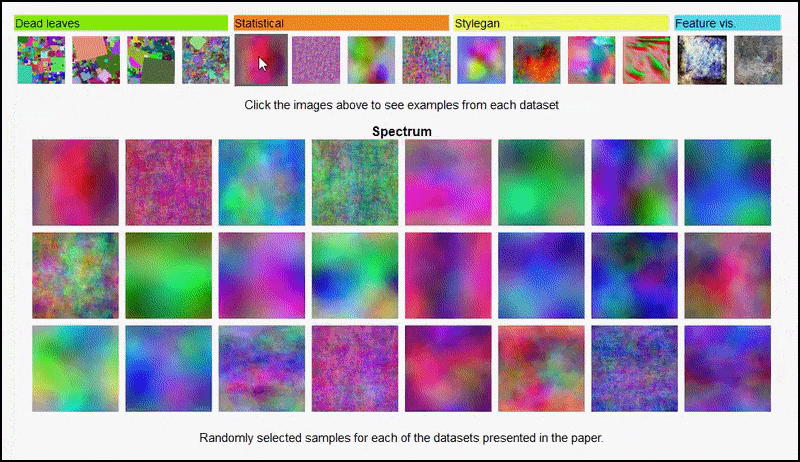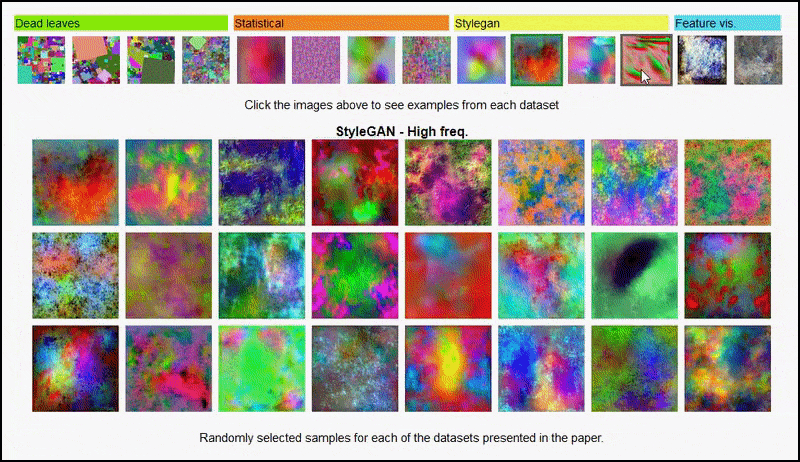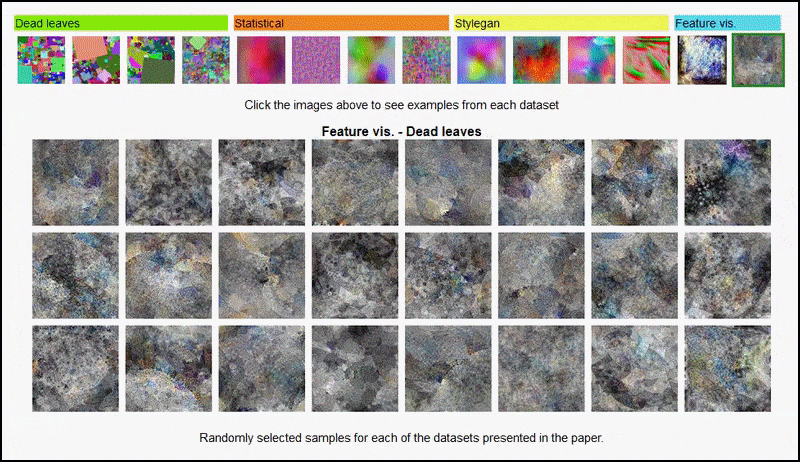
De project pagina voor het initiatief kunt u interactief de verschillende soorten willekeurige beelddatasets bekijken die in het experiment zijn gebruikt. Bron: https://mbaradad.github.io/learning_with_noise/
De door de onderzoekers verkregen resultaten stellen de fundamentele relatie tussen op afbeeldingen gebaseerde neurale netwerken en de beelden uit de 'echte wereld' die hen alarmerend worden toegeworpen in vraag. grotere volumes elk jaar, en impliceren dat de noodzaak om te verkrijgen, cureren en anderszins ruziën hyperscale beelddatasets kan uiteindelijk overbodig worden. De auteurs stellen:
'De huidige vision-systemen zijn getraind op enorme datasets, en deze datasets brengen kosten met zich mee: curatie is duur, ze erven menselijke vooroordelen en er zijn zorgen over privacy en gebruiksrechten. Om deze kosten tegen te gaan, is de belangstelling toegenomen om te leren van goedkopere gegevensbronnen, zoals niet-gelabelde afbeeldingen.
'In dit artikel gaan we een stap verder en vragen we of we echte beelddatasets helemaal kunnen afschaffen door te leren van procedurele ruisprocessen.'
De onderzoekers suggereren dat de huidige generatie machine learning-architecturen mogelijk iets veel fundamentelers (of op zijn minst onverwachts) uit beelden afleidt dan eerder werd gedacht, en dat 'onzin'-beelden mogelijk een groot deel van deze kennis veel meer kunnen overbrengen. goedkoop, zelfs met het mogelijke gebruik van ad hoc synthetische data, via architecturen voor het genereren van datasets die tijdens de training willekeurige beelden genereren:
'We identificeren twee belangrijke eigenschappen die zorgen voor goede synthetische gegevens voor het trainen van visiesystemen: 1) naturalisme, 2) diversiteit. Interessant is dat de meest naturalistische gegevens niet altijd de beste zijn, aangezien naturalisme ten koste kan gaan van diversiteit.
'Het feit dat naturalistische gegevens helpen, is misschien niet verrassend, en het suggereert dat grootschalige echte gegevens inderdaad waarde hebben. We vinden echter dat wat cruciaal is, niet is dat de gegevens zijn vast maar dat het zo is naturalistisch, dwz het moet bepaalde structurele eigenschappen van echte gegevens vastleggen.
'Veel van deze eigenschappen zijn te vangen in eenvoudige geluidsmodellen.'

Feature-visualisaties die het resultaat zijn van een van AlexNet afgeleide encoder op enkele van de verschillende 'willekeurige afbeelding'-datasets die door de auteurs zijn gebruikt, die de 3e en 5e (laatste) convolutionele laag beslaan. De hier gebruikte methodologie volgt die uiteengezet in Google AI-onderzoek uit 2017.
De papier, gepresenteerd op de 35e conferentie over neurale informatieverwerkingssystemen (NeurIPS 2021) in Sydney, is getiteld Leren zien door naar lawaai te kijken, en komt van zes onderzoekers van CSAIL, met een gelijke bijdrage.
Het werk was aanbevolen bij consensus voor een selectie in de schijnwerpers op NeurIPS 2021, met collega-commentatoren die de paper typeren als 'een wetenschappelijke doorbraak' die een 'geweldig studiegebied' opent, ook al roept het evenveel vragen op als het beantwoordt.
In het artikel concluderen de auteurs:
'We hebben aangetoond dat deze datasets, wanneer ze zijn ontworpen met behulp van resultaten van eerder onderzoek naar natuurlijke beeldstatistieken, met succes visuele representaties kunnen trainen. We hopen dat dit artikel de studie van nieuwe generatieve modellen zal motiveren die in staat zijn om gestructureerde ruis te produceren die nog hogere prestaties levert bij gebruik in een diverse reeks visuele taken.
'Zou het mogelijk zijn om de behaalde prestaties te evenaren met ImageNet-voortraining? Als er geen grote trainingsset is die specifiek is voor een bepaalde taak, is de beste pre-training misschien niet het gebruik van een standaard echte dataset zoals ImageNet.'















