Kunstmatige intelligentie
Naar Real-Time AI Mensen Met Neural Lumigraph Rendering

Ondanks de huidige golf van interesse in Neural Radiance Fields (NeRF), een technologie die in staat is om AI-gegenereerde 3D-omgevingen en objecten te creëren, vereist deze nieuwe benadering van beeldsynthesetechnologie nog steeds een grote hoeveelheid trainingsdata en ontbreekt het aan een implementatie die real-time, hoogresponsieve interfaces mogelijk maakt.
Een samenwerking tussen enkele indrukwekkende namen in de industrie en academische wereld biedt een nieuwe kijk op deze uitdaging (algemeen bekend als Novel View Synthesis, of NVS).
Het onderzoeksartikel, getiteld Neural Lumigraph Rendering, claimt een verbetering van de staat van de techniek van ongeveer twee ordes van grootte, wat verschillende stappen naar real-time CG-rendering via machine learning-pijplijnen vertegenwoordigt.

Neural Lumigraph Rendering (rechts) biedt een betere resolutie van blending-artefacten en een verbeterde afhandeling van occlusie ten opzichte van eerdere methoden. Source.
Hoewel de credits voor het artikel alleen Stanford University en de holografische displaytechnologiebedrijf Raxium (momenteel actief in stealth mode) noemen, zijn de bijdragers onder andere een principal machine learning architect bij Google, een computer wetenschapper bij Adobe, en de CTO bij StoryFile (die onlangs het nieuws haalde met een AI-versie van William Shatner).
In verband met de recente Shatner-publiciteitscampagne lijkt StoryFile NLR te gebruiken in zijn nieuwe proces voor het creëren van interactieve, AI-gegenereerde entiteiten op basis van de kenmerken en verhalen van individuele mensen.
https://www.youtube.com/watch?v=AEj2K4YzwiU
StoryFile ziet het gebruik van deze technologie in museumtentoonstellingen, online interactieve verhalen, holografische displays, augmented reality (AR) en erfgoeddocumentatie – en lijkt ook potentiële nieuwe toepassingen van NLR in wervingsgesprekken en virtuele datingsapps te onderzoeken:

Voorgestelde toepassingen uit een online video van StoryFile. Source: https://www.youtube.com/watch?v=2K9J6q5DqRc
Volumetrische Capture Voor Novel View Synthesis Interfaces En Video
Het principe van volumetrische capture, over de reeks van artikelen die over het onderwerp accumuleren, is het idee om still images of video’s van een onderwerp te nemen en machine learning te gebruiken om de viewpoints die niet door de oorspronkelijke array van camera’s werden gedekt, ‘in te vullen’.
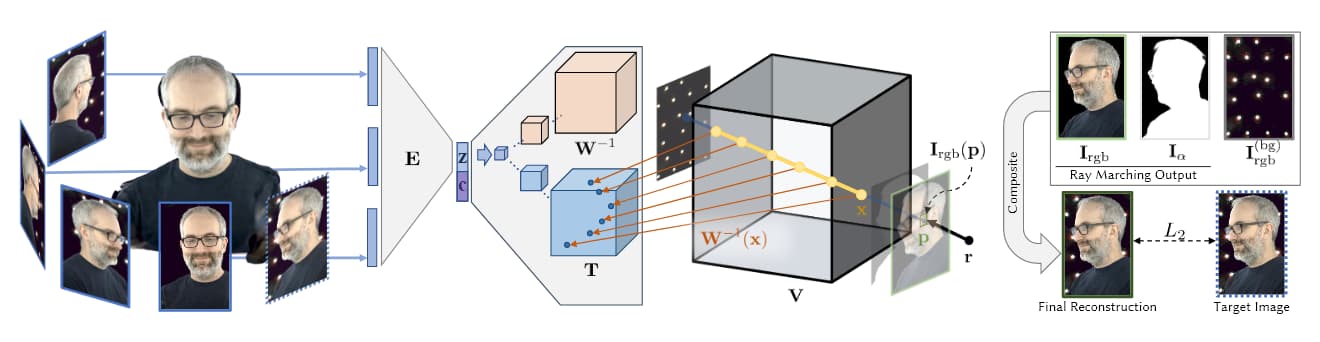
Source: https://research.fb.com/wp-content/uploads/2019/06/Neural-Volumes-Learning-Dynamic-Renderable-Volumes-from-Images.pdf
In de afbeelding hierboven, afkomstig uit Facebook’s AI-onderzoek van 2019 (zie hieronder), zien we de vier fasen van volumetrische capture: meerdere camera’s nemen beelden/footage; encoder/decoder-architectuur (of andere architectuur) berekent en concateneert de relativiteit van views; ray-marching-algoritmen berekenen de voxels (of andere XYZ-ruimtelijke geometrische eenheden) van elk punt in de volumetrische ruimte; en (in de meeste recente artikelen) training vindt plaats om een complete entiteit te synthetiseren die in real-time kan worden gemanipuleerd.
Het is deze vaak uitgebreide en data-intensieve trainingsfase die tot nu toe Novel View Synthesis buiten het bereik van real-time of hoogresponsieve capture heeft gehouden.
Het feit dat Novel View Synthesis een complete 3D-kaart van een volumetrische ruimte maakt, betekent dat het relatief triviaal is om deze punten samen te voegen tot een traditioneel computer gegenereerd mesh, waardoor een CGI-mens (of elk ander relatief begrensd object) on-the-fly kan worden vastgelegd en gearticuleerd.
Benaderingen die NeRF gebruiken, zijn afhankelijk van puntenwolken en dieptekaarten om de interpolaties tussen de schaarse punten van de capture-apparaten te genereren:

NeRF kan volumetrische diepte genereren door berekening van dieptekaarten, in plaats van generatie van CG-meshes. Source: https://www.youtube.com/watch?v=JuH79E8rdKc
Hoewel NeRF in staat is om meshes te berekenen, gebruiken de meeste implementaties dit niet om volumetrische scènes te genereren.
In tegenstelling tot NeRF, hangt de Implicit Differentiable Renderer (IDR)-benadering, gepubliceerd door het Weizmann Institute of Science in oktober 2020, af van het exploiteren van 3D-mesh-informatie die automatisch wordt gegenereerd uit capture-arrays:

Voorbeelden van IDR-captures omgezet in interactieve CGI-meshes. Source: https://www.youtube.com/watch?v=C55y7RhJ1fE
Terwijl NeRF IDR’s mogelijkheid voor vormschatting ontbreekt, kan IDR NeRF’s beeldkwaliteit niet evenaren, en beide vereisen uitgebreide middelen om te trainen en te combineren (hoewel recente innovaties in NeRF beginnen om dit aan te pakken).

NLR’s aangepaste camerarig met 16 GoPro HERO7 en 6 centrale Back-Bone H7PRO-camera’s. Voor ‘real-time’ rendering, werken deze met een minimum van 60fps. Source: https://arxiv.org/pdf/2103.11571.pdf
In plaats daarvan gebruikt Neural Lumigraph Rendering SIREN (Sinusoidal Representation Networks) om de sterke punten van elke benadering in zijn eigen kader te integreren, dat is bedoeld om output te genereren die direct bruikbaar is in bestaande real-time graphics-pijplijnen.
SIREN is gebruikt voor soortgelijke implementaties in het afgelopen jaar en vertegenwoordigt nu een populaire API-aanroep voor hobbyist Colabs in beeldsynthesegemeenschappen; echter is NLR’s innovatie om SIREN’s toe te passen op tweedimensionale multi-view beeldsupervisie, wat problematisch is vanwege de mate waarin SIREN over-gefitteerde in plaats van gegeneraliseerde output produceert.
Nadat het CG-mesh is geëxtraheerd uit de array-afbeeldingen, wordt het mesh gerasterd via OpenGL, en worden de vertexposities van het mesh toegewezen aan de bijbehorende pixels, waarna de blending van de verschillende bijdragende kaarten wordt berekend.
Het resulterende mesh is meer gegeneraliseerd en representatief dan NeRF’s (zie afbeelding hieronder), vereist minder berekening en past geen overmatige details toe aan gebieden (zoals gladde gezichtshuid) die daar niet van kunnen profiteren:

Source: https://arxiv.org/pdf/2103.11571.pdf
Aan de negatieve kant heeft NLR nog geen capaciteit voor dynamische belichting of relighting, en is de output beperkt tot schaduwkaarten en andere belichtingsoverwegingen die zijn verkregen op het moment van capture. De onderzoekers zijn van plan om dit in toekomstig onderzoek aan te pakken.
Bovendien geeft het artikel toe dat de vormen die door NLR worden gegenereerd, niet zo nauwkeurig zijn als sommige alternatieve benaderingen, zoals Pixelwise View Selection for Unstructured Multi-View Stereo, of het onderzoek van het Weizmann Institute dat eerder werd genoemd.
De Opkomst Van Volumetrische Beeldsynthese
Het idee om 3D-entiteiten te creëren uit een beperkte reeks foto’s met neurale netwerken, gaat terug tot 2007 of eerder. In 2019 produceerde Facebook’s AI-onderzoeksafdeling een seminaal onderzoeksartikel, Neural Volumes: Learning Dynamic Renderable Volumes from Images, dat voor het eerst responsieve interfaces mogelijk maakte voor synthetische mensen gegenereerd door machine learning-gebaseerde volumetrische capture.

Facebook’s onderzoek van 2019 maakte de creatie van een responsieve gebruikersinterface voor een volumetrische persoon mogelijk. Source: https://research.fb.com/publications/neural-volumes-learning-dynamic-renderable-volumes-from-images/












