Andersons hoek
De gevaren van het gebruik van citaten om NLG-inhoud te verifiëren

MeningNatuurlijke Taal Generatie-modellen zoals GPT-3 zijn gevoelig voor ‘hallucinaties’ van materiaal dat ze presenteren in de context van feitelijke informatie. In een tijdperk dat buitengewoon bezorgd is over de groei van tekstgebaseerde nepnieuws, vertegenwoordigen deze ‘graag behaaglijke’ vluchten van de fantasie een existentiële hindernis voor de ontwikkeling van geautomatiseerde schrijf- en samenvattingsystemen, en voor de toekomst van AI-gedreven journalistiek, onder andere subsectoren van Natural Language Processing (NLP).
Het centrale probleem is dat GPT-achtige taalmodellen belangrijke functies en klassen afleiden uit zeer grote corpora van trainingsTeksten, en leren om deze functies te gebruiken als bouwstenen van taal behendig en authentiek, ongeacht de nauwkeurigheid van de gegenereerde inhoud, of zelfs de aanvaardbaarheid ervan.
NLG-systemen zijn daarom momenteel afhankelijk van menselijke verificatie van feiten in een van twee benaderingen: dat de modellen worden gebruikt als zaadtekst-generatoren die onmiddellijk worden doorgegeven aan menselijke gebruikers, hetzij voor verificatie of enige andere vorm van bewerking of aanpassing; of dat mensen worden gebruikt als dure filters om de kwaliteit van datasets te verbeteren die zijn bedoeld om minder abstracte en ‘creatieve’ modellen te informeren (die op zichzelf nog steeds moeilijk te vertrouwen zijn in termen van feitelijke nauwkeurigheid, en die verdere lagen van menselijke toezicht zullen vereisen).
Oude Nieuws en Valse Feiten
Natuurlijke Taal Generatie (NLG) modellen zijn in staat om overtuigende en plausibele output te produceren omdat ze semantische architectuur hebben geleerd, in plaats van meer abstract de daadwerkelijke geschiedenis, wetenschap, economie, of enig ander onderwerp waarover ze mogelijk moeten menen, die effectief zijn verstrengeld als ‘passagiers’ in de brondata.
De feitelijke nauwkeurigheid van de informatie die NLG-modellen genereren, gaat ervan uit dat de invoer waarop ze zijn getraind, zelf betrouwbaar en up-to-date is, wat een buitengewone last met zich meebrengt in termen van voorverwerking en verdere menselijke verificatie – een kostbare hindernis die de NLP-onderzoekssector momenteel aanpakt op veel fronten.
GPT-3-schaal systemen vergen een buitengewone hoeveelheid tijd en geld om te trainen, en, eenmaal getraind, zijn ze moeilijk bij te werken op het niveau van de ‘kernel’. Hoewel sessie-gebaseerde en gebruikersgebaseerde lokale aanpassingen de bruikbaarheid en nauwkeurigheid van de geïmplementeerde modellen kunnen vergroten, zijn deze nuttige voordelen moeilijk, soms onmogelijk om terug te geven aan het kernmodel zonder volledige of gedeeltelijke opnieuw training te vereisen.
Om deze reden is het moeilijk om getrainde taalmodellen te creëren die gebruik kunnen maken van de laatste informatie.

Getraind vóór de komst van COVID, text-davinci-002 – de iteratie van GPT-3 die door zijn maker OpenAI als ‘meest capabel’ wordt beschouwd – kan 4000 tokens per verzoek verwerken, maar weet niets van COVID-19 of de invasie van Oekraïne in 2022 (deze prompts en antwoorden zijn van 5 april 2022). Interessant is dat ‘onbekend’ eigenlijk een acceptabel antwoord is in beide mislukkingen, maar verdere prompts stellen gemakkelijk vast dat GPT-3 niets weet van deze gebeurtenissen. Bron: https://beta.openai.com/playground
Een getraind model kan alleen toegang krijgen tot ‘waarheden’ die het heeft geïnternaliseerd tijdens de trainingsfase, en het is moeilijk om een nauwkeurige en pertinente citaat te krijgen per default, wanneer men probeert de model te laten verifiëren van zijn claims. Het echte gevaar van het verkrijgen van citaten uit de standaard GPT-3 (bijvoorbeeld) is dat het soms correcte citaten produceert, wat leidt tot een vals vertrouwen in dit facet van zijn capaciteiten:

Boven, drie nauwkeurige citaten verkregen door GPT-3 uit 2021. Midden, GPT-3 faalt om een van Einsteins meest beroemde citaten te citeren (“God speelt geen dobbelspel met het universum”), ondanks een niet-cryptische prompt. Onder, GPT-3 wijt een schandalig en fictief citaat toe aan Albert Einstein, blijkbaar een overschot van eerder vragen over Winston Churchill in dezelfde sessie. Bron: De auteur van het artikel uit 2021 op https://www.width.ai/post/business-applications-for-gpt-3
GopherCite
In een poging om deze algemene tekortkoming in NLG-modellen aan te pakken, heeft Google’s DeepMind onlangs GopherCite voorgesteld, een model met 280 miljard parameters dat in staat is om specifieke en nauwkeurige bewijzen te citeren ter ondersteuning van zijn gegenereerde antwoorden op prompts.



Drie voorbeelden van GopherCite die zijn claims ondersteunt met echte citaten. Bron: https://arxiv.org/pdf/2203.11147.pdf
GopherCite maakt gebruik van versterking van menselijke voorkeuren (RLHP) om querymodellen te trainen die in staat zijn om echte citaten te citeren als ondersteunend bewijs. De citaten worden live getrokken uit meerdere documentbronnen die zijn verkregen uit zoekmachines, of uit een specifiek document dat is verstrekt door de gebruiker.
De prestaties van GopherCite werden gemeten door middel van menselijke evaluatie van modelantwoorden, die 80% van de tijd ‘hoogwaardig’ werden bevonden op Google’s NaturalQuestions dataset, en 67% van de tijd op de ELI5 dataset.
Citeren van Leugens
Echter, toen getest tegen Oxford University’s TruthfulQA benchmark, werden GopherCite’s antwoorden zelden als waardevol bevonden in vergelijking met de door mensen gecurdeerde ‘correcte’ antwoorden.
De auteurs suggereren dat dit komt omdat het concept van ‘ondersteunde antwoorden’ op geen enkele objectieve manier helpt om de waarheid te definiëren, aangezien de bruikbaarheid van broncitaties kan worden ondermijnd door andere factoren, zoals de mogelijkheid dat de auteur van de citaat zelf ‘hallucineert’ (d.w.z. schrijft over fictieve werelden, produceert advertentie-inhoud, of anderszins fantastiseert over onauthentiek materiaal.



GopherCite-gevallen waarbij overtuiging niet noodzakelijkerwijs gelijk staat aan ‘waarheid’.
Effectief wordt het noodzakelijk om onderscheid te maken tussen ‘ondersteund’ en ‘waar’ in dergelijke gevallen. De menselijke cultuur is momenteel ver vooruit op machine learning in termen van het gebruik van methodologieën en kaders die zijn ontworpen om objectieve definities van waarheid te verkrijgen, en zelfs daar lijkt de native staat van ‘belangrijke’ waarheid te zijn contentie en marginale ontkenning.
Het probleem is recursief in NLG-architecturen die proberen om definitieve ‘bevestigende’ mechanismen te ontwikkelen: menselijke consensus wordt ingezet als een benchmark van waarheid door uitbesteede, AMT-achtige modellen waarbij de menselijke evaluatoren (en die andere mensen die geschillen tussen hen bemiddelen) zelf partieel en bevooroordeeld zijn.
Als voorbeeld gebruiken de initiële GopherCite-experimenten een ‘super rater’-model om de beste menselijke onderwerpen te kiezen om het modeloutput te evalueren, waarbij alleen die raters worden geselecteerd die ten minste 85% scoorden in vergelijking met een kwaliteitszorgset. Uiteindelijk werden 113 super-raters geselecteerd voor de taak.
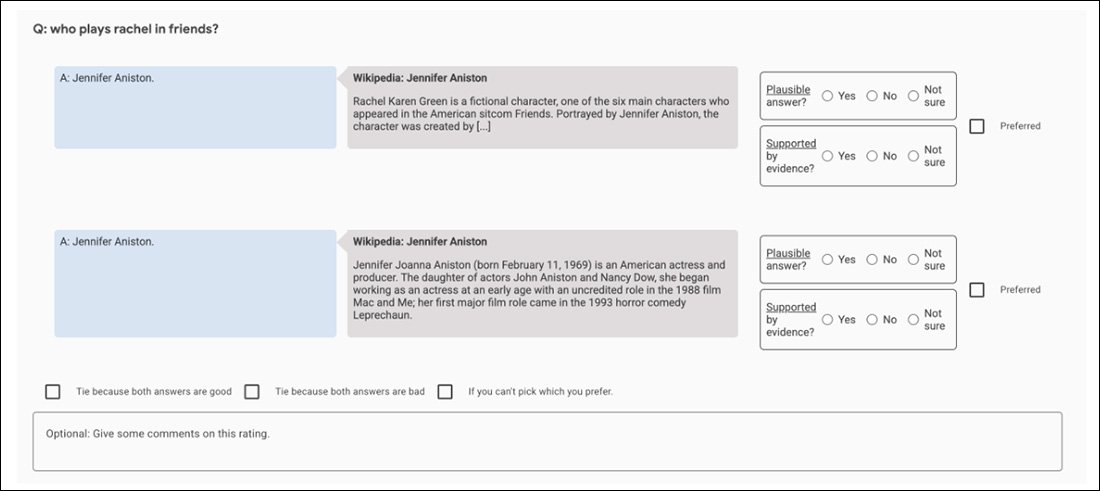
Schermopname van de vergelijkingstoepassing die wordt gebruikt om GopherCite’s output te evalueren.
Men kan betogen dat dit een perfect beeld is van een onwinbare fractale achtervolging: de kwaliteitszorgset die wordt gebruikt om de raters te beoordelen, is op zichzelf nog een andere ‘door de mens gedefinieerde’ maatstaf van waarheid, net als de Oxford TruthfulQA-set tegen welke GopherCite tekort is geschoten.
Wat betreft ondersteunde en ‘geverifieerde’ inhoud, kan NLG-systemen alleen maar hopen om menselijke dispariteit en diversiteit te synthetiseren uit training op menselijke gegevens, wat op zichzelf een slecht geformuleerd en onopgelost probleem is. We hebben een aangeboren neiging om citaten te citeren die onze meningen ondersteunen, en om met autoriteit en overtuiging te spreken in gevallen waarin onze broninformatie mogelijk verouderd, geheel onnauwkeurig of anderszins willens en wetens verkeerd kan zijn; en een neiging om deze meningen rechtstreeks in het wild te verspreiden, op een schaal en effectiviteit die ongeëvenaard is in de menselijke geschiedenis, recht in het pad van de kennis-schraapframeworks die nieuwe NLG-frameworks voeden.
Daarom lijkt het gevaar dat inherent is aan de ontwikkeling van citatie-ondersteunde NLG-systemen verbonden te zijn met de onvoorspelbare aard van het bronmateriaal. Elke mechanisme (zoals directe citatie en citaten) die de gebruikersvertrouwen in NLG-output verhoogt, voegt op het huidige niveau van de techniek gevaarlijk bij aan de authenticiteit, maar niet de waarheid van de output.
Dergelijke technieken zullen waarschijnlijk nuttig genoeg zijn wanneer NLP uiteindelijk de fictie-schrijf-‘kaleidoscopen’ van Orwell’s Nineteen Eighty-Four herschept; maar ze vertegenwoordigen een gevaarlijke achtervolging voor objectieve documentanalyse, AI-gecentreerde journalistiek, en andere mogelijke ‘non-fictie’-toepassingen van machine samenvatting en spontane of geleide tekstgeneratie.
Origineel gepubliceerd op 5 april 2022. Bijgewerkt om 15:29 EET om term te corrigeren.












