Kunstmatige intelligentie
MIT: Meting van mediavooroordeel in grote nieuwsuitzendingen met Machine Learning

Een onderzoek van MIT heeft machine learning-technieken gebruikt om vooroordeelde formuleringen te identificeren in ongeveer 100 van de grootste en meest invloedrijke nieuwsuitzendingen in de VS en daarbuiten, waaronder 83 van de meest invloedrijke gedrukte nieuwspublicaties. Het is een onderzoeksinspanning die de weg wijst naar geautomatiseerde systemen die potentieel het politieke karakter van een publicatie kunnen automatisch classificeren en lezers een dieper inzicht kunnen geven in de ethische houding van een uitgeverij op onderwerpen waar zij zich mogelijk hartstochtelijk over bekommeren.
Het werk draait om de manier waarop onderwerpen worden aangepakt met specifieke formuleringen, zoals ondocumenteerde immigrant | illegale immigrant, fetus | ongeboren baby, demonstranten | anarchisten.
Het project gebruikte Natural Language Processing (NLP)-technieken om dergelijke voorbeelden van ‘geladen’ taal (onder de veronderstelling dat ogenschijnlijk meer ‘neutrale’ termen ook een politieke houding vertegenwoordigen) te extraheren en te classificeren in een brede mapping die links- en rechts-georiënteerde vooroordeel over meer dan drie miljoen artikelen van ongeveer 100 nieuwsuitzendingen onthult, resulterend in een navigeerbare vooroordeel-landschap van de publicaties in kwestie.
Het artikel komt van Samantha D’Alonzo en Max Tegmark van de afdeling Natuurkunde van MIT, en stelt vast dat een aantal recente initiatieven rond ‘feitencontrole’, in de nasleep van talrijke ‘nepnieuws’-schandalen, kunnen worden geïnterpreteerd als oneerlijk en dienstbaar aan de belangen van bepaalde groepen. Het project is bedoeld om een meer gegevensgedreven aanpak te bieden voor het bestuderen van het gebruik van vooroordeel en ‘invloedrijke’ taal in een vermeend neutrale nieuwscontext.

Een spectrum van (letterlijk) links-rechts-frasen, zoals afgeleid uit het onderzoek. Bron: https://arxiv.org/pdf/2109.00024.pdf
NLP-verwerking
De brondata van het onderzoek werd verkregen uit de open source Newspaper3K-database, en bestond uit 3.078.624 artikelen verkregen uit 100 mediabronnen, waaronder 83 kranten. De kranten werden geselecteerd op basis van hun bereik, terwijl online mediabronnen ook artikelen bevatten van de militaire nieuwsanalysesite Defense One en Science.

De bronnen die in het onderzoek werden gebruikt.
Het artikel meldt dat de gedownloade tekst ‘minimaal’ werd voorbewerkt. Directe citaten werden geëlimineerd, aangezien het onderzoek geïnteresseerd is in de taal die door journalisten wordt gekozen (hoewel citatenselecties op zichzelf een interessant veld van studie zijn).
Britse spellingswijzen werden gewijzigd in Amerikaanse om de database te standaardiseren, alle leestekens werden verwijderd en alle behalve ordinaalgetallen ook verwijderd. Initiële zinscapitalisatie werd omgezet in kleine letters, maar alle andere capitalisatie behouden.
De eerste 100.000 meest voorkomende frasen werden geïdentificeerd en uiteindelijk gerangschikt, gezuiverd en samengevoegd in een frasenlijst. Alle redundante taal die kon worden geïdentificeerd (zoals ‘Deel dit artikel’ en ‘artikel opnieuw gepubliceerd’) werd eveneens verwijderd. Variaties over wezenlijk identieke frasen (d.w.z. ‘big tech’ en ‘Big Tech’, ‘cybersecurity’ en ‘cyber security’) werden gestandaardiseerd.
‘Notenpikken’
De initiële test was op het onderwerp ‘Black lives matter’, en kon frasenvooroordeel en valent synoniemen over de gegevens heen onderscheiden.
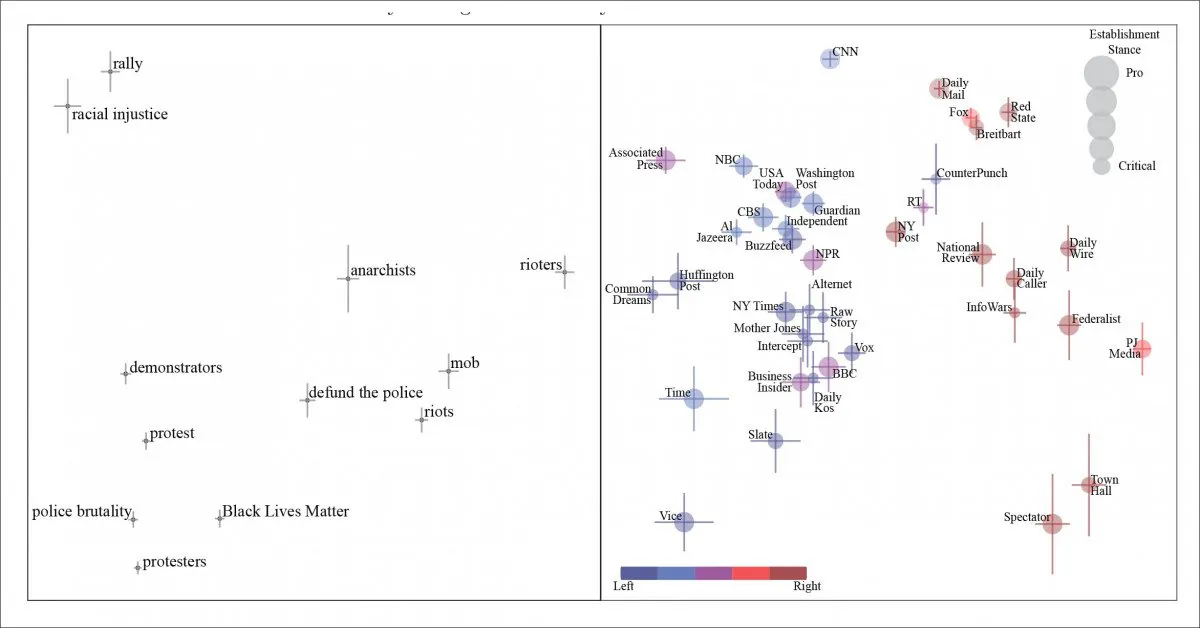
Generalized principle components for articles about Black Lives Matter (BLM). We zien mensen die deelnemen aan civiele actie gekarakteriseerd, letterlijk en figuurlijk links-rechts, als demonstranten, anarchisten en, aan het rechtse uiteinde van het spectrum, als ‘rellen’. De kranten die de frase oorspronkelijk publiceerden, worden weergegeven in het rechterpaneel.
Terwijl ‘protestanten’ van ‘anarchisten’ naar ‘rellen’ gaan als we langs de politieke houding van de uitgeverij in kwestie gaan, merkt het artikel op dat de NLP-extractie en -analyse wordt gehinderd door de praktijk van ‘notenpikken’ – waarbij een mediabron een frase citeert die als geldig wordt beschouwd door een verschillend politiek segment van de samenleving, en (ogenschijnlijk) kan vertrouwen op zijn lezerschap om de frase negatief te bekijken. Het artikel noemt ‘defund the police’ als voorbeeld van dit.
Natuurlijk betekent dit dat een ‘links-georiënteerde’ frase verschijnt in een over het algemeen rechtse context, en vertegenwoordigt een ongebruikelijke uitdaging voor een NLP-systeem dat vertrouwt op gecodeerde frasen om als signaal voor politieke houdingen te dienen.
Dergelijke frasen zijn ‘bi-valent’ [SIC] , terwijl bepaalde andere frasen een universeel negatieve connotatie hebben (d.w.z. ‘kindermoord’) die altijd als negatief wordt weergegeven over een reeks uitgeverijen heen.
Het onderzoek onthult ook soortgelijke mappings voor ‘hete’ onderwerpen zoals abortus, tech-censuur, VS-immigratie en wapenbeheersing.
Hobby-paarden
Er zijn bepaalde omstreden politieke neigingen in mediabronnen die niet voorspelbaar op deze manier splitsen, zoals het onderwerp van militaire uitgaven. Het artikel vond dat ‘links-georiënteerde’ CNN eindigde naast de rechtse National Review en Fox News op dit onderwerp.
In het algemeen kan de politieke houding echter worden bepaald door andere frasen, zoals de voorkeur voor de frase ‘militair-industrieel complex’ boven de meer rechtse ‘defensie-industrie’. De resultaten laten zien dat het eerste wordt gebruikt door establishment-kritische uitgeverijen zoals Canary en American Conservative, terwijl het tweede vaker wordt gebruikt door Fox en CNN.
Het onderzoek stelt verschillende andere progressies vast van establishment-kritische naar pro-establishment-taal, waaronder de reeks van ‘neergeschoten’ tot de meer passieve ‘de dood van’; ‘gevangene-misdadigers’ tot ‘gevangen mensen’; en ‘oliegroothandelaars’ tot ‘big oil’.

Valent synoniemen met establishment-vooroordeel, van boven naar beneden.
Het onderzoek erkent dat uitgeverijen ‘weg zullen gaan’ van hun basispolitieke houding, hetzij op een linguïstisch niveau (zoals het gebruik van bi-valente frasen), of om verschillende andere motieven. Bijvoorbeeld, de eerbare rechtse Britse publicatie The Spectator, opgericht in 1828, bevat vaak en prominent linkse denkstukken die tegen de algemene politieke stroom van zijn inhoudsstromen schuren. Of dit wordt gedaan uit een gevoel van onpartijdig rapporteren of om zijn kernlezerschap periodiek in verkeer genererende commentaar-stormen te laten ontbranden, is een kwestie van giswerk – en geen eenvoudig geval voor een machine learning-systeem dat duidelijke en consistente tokens zoekt.
Deze specifieke ‘hobby-paarden’ en dubbelzinnig gebruik van ‘jarring’ standpunten onder individuele nieuwsorganisaties verwarren enigszins de links-rechts-mapping die het onderzoek uiteindelijk biedt, maar geven een brede indicatie van politieke affiliatie.

Teruggehouden betekenis
Hoewel het artikel op 2 september is gedateerd en eind augustus 2021 is gepubliceerd, heeft het relatief weinig aandacht gekregen. Gedeeltelijk kan dit komen doordat kritisch onderzoek dat is gericht op de mainstream media onwaarschijnlijk met enthousiasme wordt ontvangen door deze; maar het kan ook te wijten zijn aan de aarzeling van de auteurs om duidelijke en ondubbelzinnige grafieken te produceren die aantonen waar invloedrijke en krachtige mediapublicaties op verschillende onderwerpen staan, samen met geaggregeerde waarden die aangeven in welke mate een publicatie naar links of rechts leunt. In feite lijken de auteurs moeite te doen om het potentieel ontvlambare effect van de resultaten te dempen.
Eveneens toont de uitgebreide gepubliceerde gegevens van het project frequentietellingen van incidenten van woorden, maar lijkt te zijn geanonimiseerd, waardoor het moeilijk is om een duidelijk beeld te krijgen van media-vooroordeel over de publicaties die zijn bestudeerd. Zonder het project op een of andere manier operationeel te maken, laat dit alleen de geselecteerde voorbeelden die in het artikel worden gepresenteerd over.
Latere studies van deze aard zouden mogelijk nuttiger zijn als ze niet alleen de formulering zouden overwegen die voor onderwerpen wordt gebruikt, maar ook of het onderwerp überhaupt werd behandeld, aangezien stilte veel zegt, en een eigen politieke karakter heeft dat vaak meer zegt dan alleen budgettaire beperkingen of andere pragmatische factoren die nieuwsselectie kunnen informeren.
Niettemin lijkt het MIT-onderzoek het grootste van zijn soort tot nu toe te zijn, en kan het een raamwerk vormen voor toekomstige classificatiesystemen, en zelfs secundaire technologieën zoals browser-extensies die casual lezers kunnen waarschuwen voor de politieke kleur van de publicatie die ze op dat moment lezen.
Bellen, vooroordeel en terugslag
Bovendien zou het moeten worden overwogen of dergelijke systemen een van de meest omstreden aspecten van algoritmische aanbevelingssystemen verder zouden versterken – de neiging om een kijker naar omgevingen te leiden waarin ze nooit een tegenstrijdig of uitdagend standpunt zien, wat waarschijnlijk de lezer zijn standpunt over kernonderwerpen verder zal versterken.
Of een dergelijke inhoudsbel een ‘veilige omgeving’ is, een belemmering voor intellectuele groei, of een bescherming tegen gedeeltelijke propaganda, is een waardeoordeel – een filosofische kwestie die moeilijk te benaderen is vanuit het mechanistische, statistische standpunt van machine learning-systemen.
Verder, net zoals het MIT-onderzoek moeite heeft gedaan om de gegevens de resultaten te laten definiëren, is de classificatie van de politieke waarde van frasen onvermijdelijk ook een soort waardeoordeel, en een die niet gemakkelijk kan weerstaan aan de mogelijkheid van taal om opnieuw te coderen giftige of omstreden inhoud in nieuwe frasen die niet in het handboek, de forumregels of de trainingsdatabase staan.
Als een dergelijke codificatie in populaire online-systemen zou worden ingebed, lijkt het waarschijnlijk dat een voortdurende inspanning om de ethische en politieke temperatuur van grote nieuwsuitzendingen in kaart te brengen, kan uitgroeien tot een Koude Oorlog tussen de mogelijkheid van AI om vooroordeel te onderscheiden en de mogelijkheid van uitgeverijen om hun standpunt uit te drukken in een evoluerende idioom dat routinematig de begrip van semantiek van machine learning voorbij gaat.
14/09/21 – 1.41 GMT+2 – Gewijzigd van ‘100 kranten’ in ‘100 nieuwsuitzendingen’
4:58pm – Correctie van artikelcitaat om Samantha D’Alonzo op te nemen, en verwante correcties.












