Kunstmatige intelligentie
Is DALL-E 2 slechts ‘dingen aan elkaar plakken’ zonder de relaties tussen hen te begrijpen?

Een nieuw onderzoeksrapport van de Harvard University suggereert dat OpenAI’s tekst-naar-afbeelding-framework DALL-E 2 moeite heeft om zelfs maar basale relaties tussen de elementen die het samenstelt in gesynthesiseerde foto’s te reproduceren, ondanks de verbluffende sofisticatie van veel van zijn output.
De onderzoekers voerden een gebruikersstudie uit met 169 crowdsourced deelnemers, die werden gepresenteerd met DALL-E 2-afbeeldingen op basis van de meest basale menselijke principes van relationele semantiek, samen met de tekstprompts die ze hadden gegenereerd. Toen ze werden gevraagd of de prompts en de afbeeldingen gerelateerd waren, waren minder dan 22% van de afbeeldingen door de deelnemers beschouwd als pertinent voor hun geassocieerde prompts, in termen van de zeer eenvoudige relaties die DALL-E 2 werd gevraagd om te visualiseren.

Een screenshot van de trials die zijn uitgevoerd voor het nieuwe papier. Deelnemers werden gevraagd om alle afbeeldingen te selecteren die overeenkwamen met de prompt. Bron: https://arxiv.org/pdf/2208.00005.pdf
De resultaten suggereren ook dat DALL-E’s schijnbare vermogen om disparate elementen te combineren kan afnemen als die elementen minder waarschijnlijk zijn om te zijn voorgekomen in de real-world trainingsdata die de systeem aandrijft.
Bijvoorbeeld, afbeeldingen voor de prompt ‘kind dat een kom aanraakt’ kregen een overeenstemmingspercentage van 87% (d.w.z. de deelnemers klikten op de meeste afbeeldingen als relevant voor de prompt), terwijl vergelijkbare fotorealistische renders van ‘een aap die een leguaan aanraakt’ slechts 11% overeenstemming behaalden:


DALL-E heeft moeite om de onwaarschijnlijke gebeurtenis van een ‘aap die een leguaan aanraakt’ weer te geven, waarschijnlijk omdat het niet voorkomt in de trainingsset.
In het tweede voorbeeld krijgt DALL-E 2 vaak de schaal en zelfs het soort verkeerd, waarschijnlijk vanwege een gebrek aan real-world afbeeldingen die deze gebeurtenis weergeven. In tegenstelling tot de eerste afbeelding, waarbij het redelijk is om een groot aantal trainingsfoto’s te verwachten die kinderen en voedsel betreffen, en dat deze subdomein/klasse goed ontwikkeld is.
DALL-E’s moeite om sterk contrastieve beeld-elementen te combineren, suggereert dat het publiek momenteel zo verblind is door het systeem’s fotorealistische en breed interpretatieve capaciteiten, dat het nog geen kritisch oog heeft ontwikkeld voor gevallen waarin het systeem effectief alleen maar ‘plakt’ een element op een ander, zoals in deze voorbeelden van de officiële DALL-E 2-site:

Cut-and-paste-synthese, van de officiële voorbeelden voor DALL-E 2. Bron: https://openai.com/dall-e-2/
Het nieuwe papier stelt*:
‘Relationele begrip is een fundamenteel onderdeel van menselijke intelligentie, dat zich vroeg in de ontwikkeling manifesteert, en snel en automatisch in perceptie wordt berekend.
‘DALL-E 2’s moeite met zelfs maar basale ruimtelijke relaties (zoals in, op, onder) suggereert dat het, wat het ook heeft geleerd, nog niet de soort representaties heeft geleerd die mensen in staat stellen om de wereld zo flexibel en robuust te structureren.
‘Een directe interpretatie van deze moeite is dat systemen zoals DALL-E 2 nog niet relationele compositioneelheid hebben.’
De auteurs suggereren dat tekst-geleide beeldgeneratie-systemen zoals de DALL-E-serie kunnen profiteren van het gebruik van algoritmes die gebruikelijk zijn in robotica, die identiteiten en relaties tegelijk modelleren, vanwege de noodzaak voor de agent om daadwerkelijk met de omgeving te interageren in plaats van alleen maar een mengsel van diverse elementen te fabriceren.
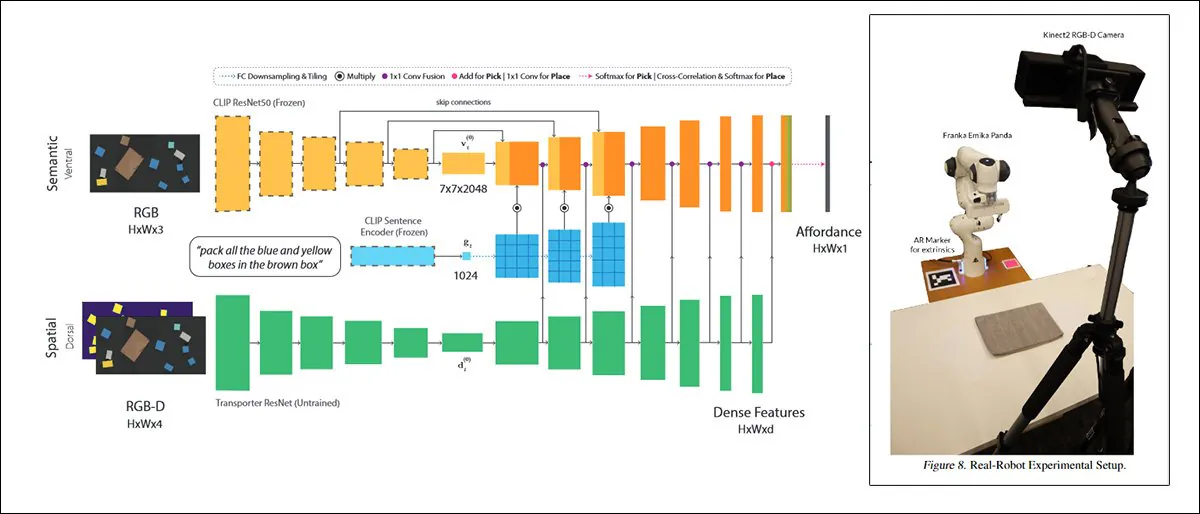
Een dergelijke benadering, getiteld CLIPort, gebruikt hetzelfde CLIP-mechanisme dat dient als een kwaliteitsbeoordelings-element in DALL-E 2:

CLIPort, een samenwerking tussen de University of Washington en NVIDIA uit 2021, gebruikt CLIP in een context die zo praktisch is dat de systemen die hierop zijn getraind noodzakelijkerwijs een begrip van fysieke relaties moeten ontwikkelen, een motivator die ontbreekt in DALL-E 2 en soortgelijke ‘fantastische’ beeldsynthese-kaders. Bron: https://arxiv.org/pdf/2109.12098.pdf
De auteurs suggereren verder dat ‘een andere plausibele upgrade’ zou kunnen zijn om de architectuur van beeldsynthesesystemen zoals DALL-E te laten incorporeren multiplicatieve effecten in een enkele laag van berekening, waardoor de berekening van relaties mogelijk wordt op een manier die geïnspireerd is door de informatieverwerkingscapaciteiten van biologische systemen.
Het nieuwe papier heeft als titel Testing Relational Understanding in Text-Guided Image Generation, en komt van Colin Conwell en Tomer D. Ullman van de afdeling Psychologie van Harvard.
Verder dan vroege kritiek
In een reactie op de ‘sleight of hand’ achter de realisme en integriteit van DALL-E 2’s output, merken de auteurs op dat eerdere werken hebben aangetoond dat er tekortkomingen zijn in DALL-E-stijl generatieve beeldsystemen.
In juni van dit jaar wees UoC Berkeley op de moeite die DALL-E heeft om reflecties en schaduwen te hanteren; dezelfde maand onderzocht een studie uit Korea de ‘uniekheid’ en originaliteit van DALL-E 2-stijl output met een kritisch oog; een voorlopige analyse van DALL-E 2-afbeeldingen, kort na de lancering, van NYU en de University of Texas, vond verschillende problemen met compositioneelheid en andere essentiële factoren in DALL-E 2-afbeeldingen; en vorige maand, een gezamenlijk werk tussen de University of Illinois en MIT bood suggesties voor architecturale verbeteringen aan dergelijke systemen in termen van compositioneelheid.
De onderzoekers merken verder op dat DALL-E-luminaries zoals Aditya Ramesh hebben toegegeven dat het kader problemen heeft met binding, relatieve grootte, tekst en andere uitdagingen.
De ontwikkelaars achter Google’s rivaliserende beeldsynthesesysteem Imagen hebben ook DrawBench voorgesteld, een novum vergelijkingssysteem dat beeldnauwkeurigheid meet over kaders heen met diverse metrics.
In plaats daarvan suggereren de auteurs van het nieuwe papier dat een beter resultaat kan worden behaald door menselijke schatting – in plaats van intern, algoritme-metrics – tegen de resulterende afbeeldingen te plaatsen, om te bepalen waar de zwakheden liggen, en wat kan worden gedaan om ze te mitigeren.
De studie
Om dit doel te bereiken, baseert het nieuwe project zijn aanpak op psychologische principes, en zoekt het om terug te keren van de huidige golf van interesse in prompt-engineering (wat in feite een concessie is aan de tekortkomingen van DALL-E 2, of een vergelijkbaar systeem), om de beperkingen te onderzoeken en mogelijk aan te pakken die dergelijke ‘workarounds’ noodzakelijk maken.













{kind=link}