
Artificial Intelligence
Google's LipSync3D biedt verbeterde 'Deepfaked' synchronisatie van mondbewegingen

A samenwerking tussen Google AI-onderzoekers en het Indian Institute of Technology Kharagpur biedt een nieuw raamwerk om pratende hoofden te synthetiseren uit audio-inhoud. Het project heeft tot doel geoptimaliseerde en redelijk uitgeruste manieren te produceren om 'talking head'-video-inhoud te maken van audio, met als doel lipbewegingen te synchroniseren met nagesynchroniseerde of machinaal vertaalde audio, en voor gebruik in avatars, in interactieve toepassingen en in andere real-time omgevingen.

Bron: https://www.youtube.com/watch?v=L1StbX9OznY
De machine learning-modellen die in het proces zijn getraind – LipSync3D genoemd – vereisen slechts één video van de identiteit van het doelgezicht als invoergegevens. De datavoorbereidingspijplijn scheidt de extractie van gezichtsgeometrie van de evaluatie van verlichting en andere facetten van een invoervideo, waardoor een meer economische en gerichte training mogelijk wordt.
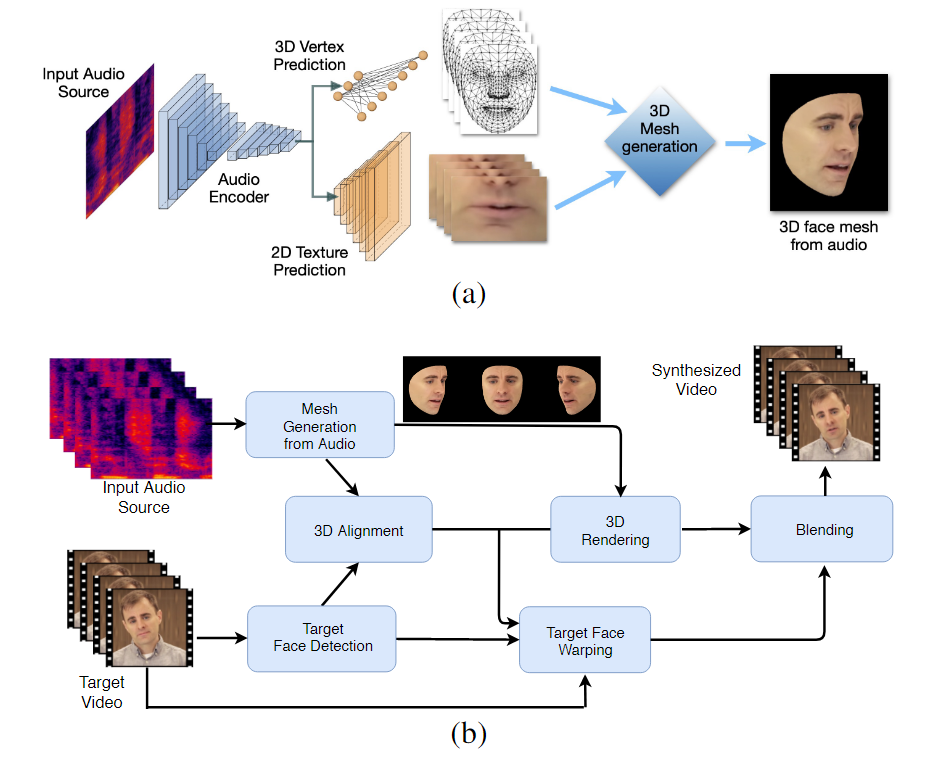
De workflow in twee fasen van LipSync3D. Hierboven het genereren van een dynamisch getextureerd 3D-gezicht uit de 'doel'-audio; hieronder, de invoeging van de gegenereerde mesh in een doelvideo.
De meest opmerkelijke bijdrage van LipSync3D aan de hoeveelheid onderzoek op dit gebied is misschien wel het algoritme voor verlichtingsnormalisatie, dat training en inferentieverlichting loskoppelt.

Door de verlichtingsgegevens los te koppelen van de algemene geometrie, kan LipSync3D onder uitdagende omstandigheden een meer realistische output van lipbewegingen produceren. Andere benaderingen van de afgelopen jaren hebben zich beperkt tot 'vaste' lichtomstandigheden die hun beperktere capaciteit in dit opzicht niet verraden.
Tijdens de voorverwerking van de ingevoerde gegevensframes moet het systeem spiegelende punten identificeren en verwijderen, aangezien deze specifiek zijn voor de lichtomstandigheden waaronder de video is gemaakt en anders het proces van opnieuw belichten zullen verstoren.

LipSync3D, zoals de naam al doet vermoeden, voert niet alleen pixelanalyse uit op de gezichten die het evalueert, maar gebruikt actief geïdentificeerde gezichtsoriëntatiepunten om beweeglijke CGI-achtige meshes te genereren, samen met de 'uitgevouwen' texturen die eromheen zijn gewikkeld in een traditionele CGI pijpleiding.

Pose-normalisatie in LipSync3D. Aan de linkerkant staan de invoerframes en gedetecteerde kenmerken; in het midden de genormaliseerde hoekpunten van de gegenereerde mesh-evaluatie; en aan de rechterkant de bijbehorende textuuratlas, die de basiswaarheid biedt voor textuurvoorspelling. Bron: https://arxiv.org/pdf/2106.04185.pdf
Naast de nieuwe relighting-methode beweren de onderzoekers dat LipSync3D drie belangrijke innovaties biedt op eerder werk: de scheiding van geometrie, belichting, pose en textuur in afzonderlijke datastromen in een genormaliseerde ruimte; een gemakkelijk te trainen auto-regressief textuurvoorspellingsmodel dat in de tijd consistente videosynthese produceert; en meer realisme, zoals geëvalueerd door menselijke beoordelingen en objectieve statistieken.

Door de verschillende facetten van de video-gezichtsbeelden op te splitsen, krijgt u meer controle over de videosynthese.
LipSync3D kan de juiste beweging van de lipgeometrie rechtstreeks uit audio afleiden door fonemen en andere facetten van spraak te analyseren en deze te vertalen in bekende corresponderende spierhoudingen rond de mond.

Dit proces maakt gebruik van een gezamenlijke voorspellingspijplijn, waarbij de afgeleide geometrie en textuur speciale encoders hebben in een auto-encoderopstelling, maar een audio-encoder delen met de spraak die bedoeld is om aan het model te worden opgelegd:

De labiele bewegingssynthese van LipSync3D is ook bedoeld om gestileerde CGI-avatars aan te drijven, die in feite slechts hetzelfde soort mesh- en textuurinformatie zijn als echte beelden:
De lipbewegingen van een gestileerde 3D-avatar worden in realtime aangedreven door een bronsprekervideo. In een dergelijk scenario zouden de beste resultaten worden verkregen door gepersonaliseerde pre-training.
De onderzoekers anticiperen ook op het gebruik van avatars met een iets realistischer gevoel:
![]()
Voorbeelden van trainingstijden voor de video's variëren van 3-5 uur voor een video van 2-5 minuten, in een pijplijn die TensorFlow, Python en C++ gebruikt op een GeForce GTX 1080. De trainingssessies gebruikten een batchgrootte van 128 frames over 500-1000 tijdperken, waarbij elk tijdperk een volledige evaluatie van de video vertegenwoordigt.

Op weg naar dynamische hersynchronisatie van lipbewegingen
Het gebied van het opnieuw synchroniseren van lippen om ruimte te bieden aan een nieuwe audiotrack heeft de afgelopen jaren veel aandacht gekregen in computer vision-onderzoek (zie hieronder), niet in de laatste plaats omdat het een bijproduct is van controversiële deepfake-technologie.
In 2017 de Universiteit van Washington gepresenteerd onderzoek in staat om lipsynchronisatie van audio te leren en het te gebruiken om de lipbewegingen van de toenmalige president Obama te veranderen. In 2018; het Max Planck Instituut voor Informatica geleid een ander onderzoeksinitiatief om identiteit> identiteitsvideo-overdracht mogelijk te maken, met lipsynchronisatie a bijproduct van het proces; en in mei 2021 onthulde AI-startup FlawlessAI zijn gepatenteerde lipsynchronisatietechnologie TrueSync op grote schaal ontvangen in de pers als aanjager van verbeterde nasynchronisatietechnologieën voor grote filmreleases in verschillende talen.
En natuurlijk biedt de voortdurende ontwikkeling van deepfake open source-repository's een andere tak van actief door gebruikers bijgedragen onderzoek op dit gebied van gezichtsbeeldsynthese.















