Kunstmatige intelligentie
Het creëren van een aangepaste Generative Adversarial Network met schetsen

Onderzoekers van Carnegie Mellon en MIT hebben een nieuwe methode ontwikkeld die het mogelijk maakt voor een gebruiker om een aangepaste Generative Adversarial Network (GAN) beeldcreatie-systemen te maken door simpelweg indicatieve schetsen te tekenen.
Een systeem van dit type zou het mogelijk maken voor een eindgebruiker om beeldgenererende systemen te creëren die in staat zijn om zeer specifieke beelden te genereren, zoals specifieke dieren, soorten gebouwen – en zelfs individuele mensen. Momenteel produceren de meeste GAN-generatiesystemen brede en vrij willekeurige output, met beperkte mogelijkheden om specifieke kenmerken op te geven, zoals dier ras, haartypen bij mensen, architectuurstijlen of daadwerkelijke gezichtsidentiteiten.
De benadering, zoals beschreven in het artikel Sketch Your Own GAN, maakt gebruik van een noviteitsschetsinterface als een effectieve ‘zoek’functie om kenmerken en klassen te vinden in overvolle beeld databases die duizenden soorten objecten kunnen bevatten, waaronder veel subtypen die niet relevant zijn voor de intentie van de gebruiker. De GAN wordt vervolgens getraind op deze gefilterde sub-set van beelden.
Door de specifieke objecttype te schetsen waarmee de gebruiker de GAN wil kalibreren, worden de generatieve mogelijkheden van het framework gespecialiseerd in die klasse. Als een gebruiker bijvoorbeeld een framework wil creëren dat een specifiek type kat genereert (in plaats van zomaar een oude kat, zoals te verkrijgen met This Cat Does Not Exist), dienen de invoerschetsen als een filter om niet-relevante klassen van katten uit te sluiten.

Source: https://peterwang512.github.io/GANSketching/
Het onderzoek wordt geleid door Sheng Yu-Wang van Carnegie Mellon University, samen met collega Jun-Yan Zhu, en David Bau van MIT’s Computer Science & Artificial Intelligence Laboratory.
De methode zelf wordt ‘GAN schetsen’ genoemd en gebruikt de invoerschetsen om de gewichten van een ‘template’ GAN-model rechtstreeks te veranderen om specifiek het geïdentificeerde domein of subdomein te richten via cross-domain adversarial loss.
Verschillende regulatiemethoden werden onderzocht om ervoor te zorgen dat de output van het model gevarieerd is, terwijl de beeldkwaliteit hoog blijft. De onderzoekers creëerden voorbeeldtoepassingen die in staat zijn om latent ruimte te interpoleren en beeldbewerkingen uit te voeren.
Dit [$class] Bestaat Niet
GAN-gebaseerde beeldgeneratiesystemen zijn de afgelopen jaren een rage geworden, zo niet een meme, met een vermenigvuldiging van projecten die in staat zijn om afbeeldingen van niet-bestaande dingen te genereren, waaronder mensen, huurappartementen, snacks, voeten, paarden, politici en insecten, om er maar een paar te noemen.
GAN-gebaseerde beeldsynthesesystemen worden gemaakt door uitgebreide datasets samen te stellen of te cureren die afbeeldingen bevatten uit het doeldomein, zoals gezichten of paarden; modellen trainen die een reeks kenmerken generaliseren over de afbeeldingen in de database; en generator-modules implementeren die willekeurige voorbeelden kunnen uitvoeren op basis van de geleerde kenmerken.

Output van schetsen in DeepFacePencil, die gebruikers in staat stelt om fotorealistische gezichten te creëren vanuit schetsen. Veel soortgelijke schets-tot-afbeeldingprojecten bestaan. Source: https://arxiv.org/pdf/2008.13343.pdf
Hoge-dimensionale kenmerken zijn onder de eerste die worden geconcretiseerd tijdens het trainingsproces en zijn equivalent aan de eerste brede verfstreken van een schilder op een canvas. Deze hoge-dimensionale kenmerken zullen uiteindelijk correleren met veel meer gedetailleerde kenmerken (d.w.z. de oogglans en scherpe snorharen van een kat, in plaats van alleen een generieke beige blob die het hoofd vertegenwoordigt).
Ik Weet Wat Je Bedoelt…
Door de relatie tussen deze vroege seminale vormen en de uiteindelijk gedetailleerde interpretaties die veel later in het trainingsproces worden verkregen, is het mogelijk om relaties tussen ‘vaag’ en ‘specifiek’ beelden af te leiden, waardoor gebruikers complexe en fotorealistische beelden kunnen creëren vanuit ruwe schetsen.
Onlangs bracht NVIDIA een desktopversie uit van zijn langlopende GauGAN-onderzoek naar GAN-gebaseerde landschapsgeneratie, die gemakkelijk dit principe demonstreert:
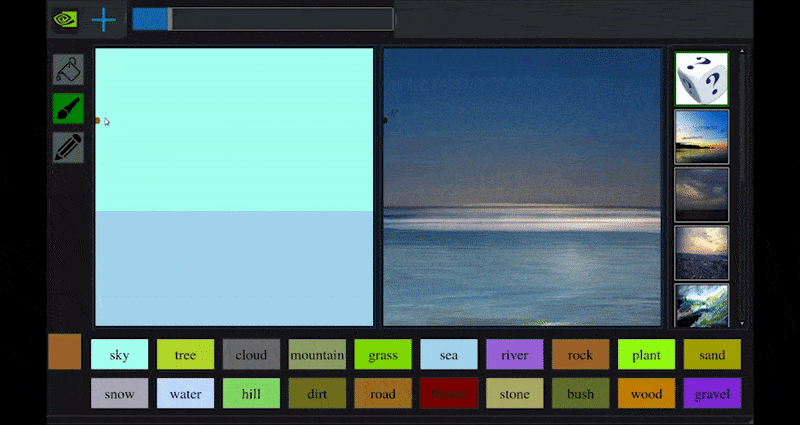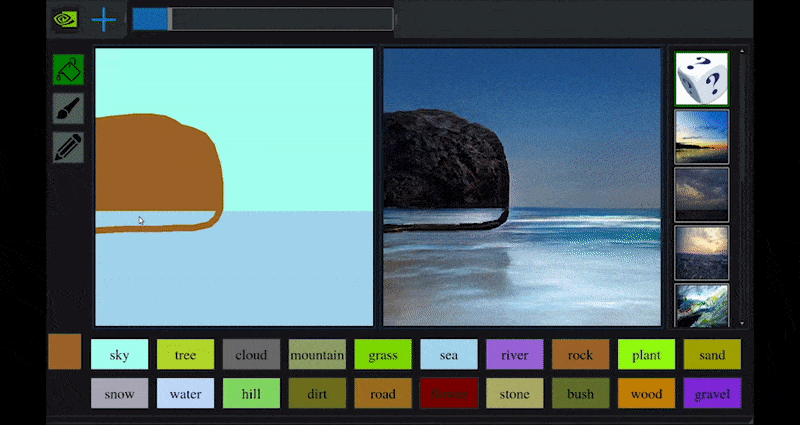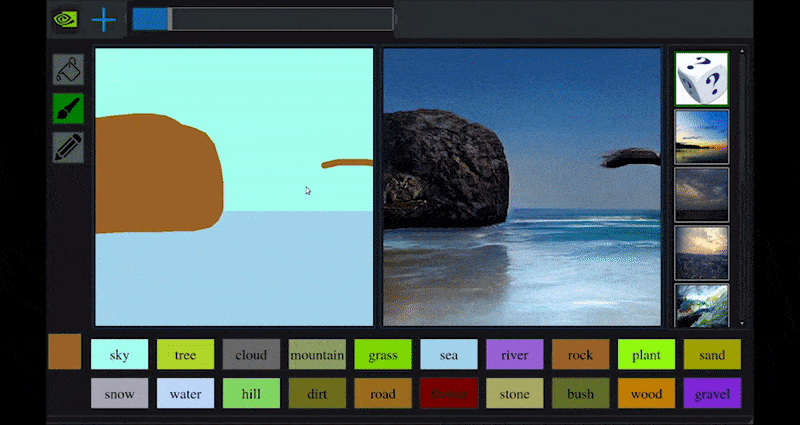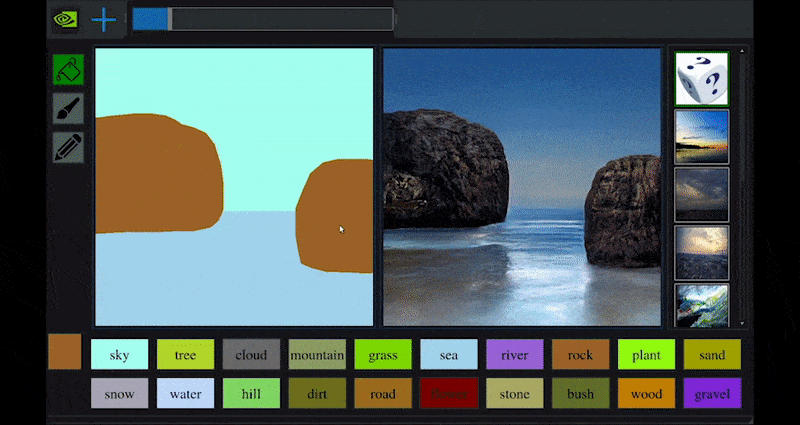
Benaderende schetsen worden omgezet in rijke landschapsbeelden via NVIDIA’s GauGAN, en nu de NVIDIA Canvas-toepassing. Source: https://rossdawson.com/futurist/implications-of-ai/future-of-ai-image-synthesis/
Evenzo hebben meerdere systemen zoals DeepFacePencil hetzelfde principe gebruikt om schets-geïnduceerde fotorealistische beeldgeneratoren te creëren voor verschillende domeinen.

De architectuur van DeepFacePencil.
Sketch-To-Image Vereenvoudigen
De nieuwe paper’s GAN Sketching-benadering zoekt ernaar om de formidabele last van datagathering en -curatie die typisch betrokken is bij de ontwikkeling van GAN-beeldkaders, te verwijderen door gebruikersinput te gebruiken om te definiëren welke sub-set van beelden de trainingsdata zou moeten vormen.
Het systeem is ontworpen om slechts een kleine hoeveelheid invoerschetsen te vereisen om het kader te kalibreren. Het systeem keert effectief de functionaliteit van PhotoSketch om, een gezamenlijk onderzoeksinitiatief van 2019 door onderzoekers van Carnegie Mellon, Adobe, Uber ATG en Argo AI, dat is opgenomen in het nieuwe werk. PhotoSketch was ontworpen om artistieke schetsen van afbeeldingen te creëren en bevat al de effectieve mapping van vaag>specifiek beeldcreatie-relaties.
Voor het generatiegedeelte van het proces, verandert de nieuwe methode alleen de gewichten van StyleGAN2. Aangezien de beeldgegevens die worden gebruikt slechts een sub-set zijn van de totale beschikbare gegevens, is het modificeren van de mapping-netwerk voldoende om de gewenste resultaten te behalen.
De methode werd geëvalueerd op een aantal populaire sub-domeinen, waaronder paarden, kerken en katten.

De LSUN-dataset van Princeton University uit 2016 werd gebruikt als de kernmateriaal waaruit de doelsub-domeinen werden afgeleid. Om een schetskaartsysteem te creëren dat robuust is tegen de eigenaardigheden van echte gebruikersinvoerschetsen, werd het systeem getraind op afbeeldingen uit de QuickDraw-dataset die door Microsoft tussen 2021-2016 is ontwikkeld.
Hoewel de schetskaart tussen PhotoSketch en QuickDraw vrij verschillend zijn, vonden de onderzoekers dat hun kader goed werkt in het overbruggen van hen op relatief eenvoudige poses, hoewel meer ingewikkelde poses (zoals katten die liggen) meer uitdagingen bieden, terwijl zeer abstracte gebruikersinput (d.w.z. te ruwe tekeningen) ook de kwaliteit van de resultaten beïnvloedt.

Latente Ruimte en Natuurlijke Beeldbewerking
De onderzoekers ontwikkelden twee toepassingen op basis van het kernwerk: latente ruimte bewerken en beeldbewerken. Latente ruimte bewerken biedt interpreteerbare gebruikerscontroles die worden gefaciliteerd tijdens de training, en stellen een brede variatie mogelijk terwijl ze trouw blijven aan het doeldomein en aangenaam consistent zijn over variaties.

Soepele latente ruimte interpolatie met de aangepaste modellen van GAN Sketching.
Het latente ruimte bewerken-component werd aangedreven door het GANSpace-project van 2020, een gezamenlijk initiatief van Aalto University, Adobe en NVIDIA.
Een enkele afbeelding kan ook worden doorgevoerd aan het aangepaste model, waardoor natuurlijke beeldbewerking mogelijk wordt. In deze toepassing wordt een enkele afbeelding geprojecteerd op het aangepaste GAN, waardoor niet alleen directe bewerking mogelijk wordt, maar ook het behoud van hogere latente ruimte bewerken, als dit ook is gebruikt.

Hier is een echte afbeelding gebruikt als invoer voor het GAN (katmodel), die de invoer bewerkt om overeen te komen met de ingediende schetsen. Dit maakt beeldbewerking via schetsen mogelijk.
Hoewel configureerbaar, is het systeem niet ontworpen om in real-time te werken, tenminste niet in termen van training en kalibratie. Momenteel vereist GAN Sketching 30.000 trainingsiteraties. Het systeem vereist ook toegang tot de oorspronkelijke trainingsdata voor het oorspronkelijke model.
In gevallen waarin de dataset open source is en een licentie heeft die lokale kopiëring toestaat, kan dit worden geaccommodeerd door de brondata op te nemen in een lokaal geïnstalleerd pakket, hoewel dit aanzienlijke schijfruimte in beslag zou nemen; of door toegang te krijgen tot of gegevens te verwerken op afstand, via een cloud-gebaseerde benadering, die netwerkoverhead en (in het geval van verwerking die daadwerkelijk plaatsvindt in de cloud) mogelijk rekenkostenoverwegingen introduceert.

Transformaties van aangepaste FFHQ-modellen getraind op slechts 4 door de mens gegenereerde schetsen.












