Andersons hoek
Fidelity vs. Realisme in Deepfake-video’s

Niet alle deepfake-praktijken delen hetzelfde doel: de impuls van het onderzoekssector van beeldsynthese – gesteund door invloedrijke voorstanders zoals Adobe, NVIDIA en Facebook – is om de stand van de techniek te verbeteren zodat machine learning-technieken uiteindelijk menselijke activiteit kunnen recreëren of synthetiseren in hoge resolutie en onder de meest uitdagende omstandigheden (fidelity).
Daarentegen is het doel van degenen die deepfake-technologieën willen gebruiken om desinformatie te verspreiden, om geloofwaardige simulaties van echte mensen te creëren met behulp van vele andere methoden dan de enkele waarheid van deepfaked gezichten. In dit scenario zijn adjunctfactoren zoals context en geloofwaardigheid bijna gelijk aan de potentie van een video om gezichten te simuleren (realisme).
Deze ‘sleight-of-hand’-aanpak strekt zich uit tot de degradatie van de eindbeeldkwaliteit van een deepfake-video, zodat de hele video (en niet alleen het bedrieglijke gedeelte dat wordt vertegenwoordigd door een deepfaked gezicht) een samenhangend ‘uitzicht’ heeft dat nauwkeurig is voor de verwachte kwaliteit voor het medium.
‘Samenhangend’ hoeft niet te betekenen ‘goed’ – het is genoeg dat de kwaliteit consistent is over het origineel en de ingevoegde, vervalste inhoud, en voldoet aan verwachtingen. In termen van VOIP-streaminguitvoer op platforms zoals Skype en Zoom, kan de lat opvallend laag liggen, met stuttering, jerky video en een hele reeks potentiële compressie-artefacten, evenals ‘smoothing’-algoritmen die zijn ontworpen om hun effecten te verminderen – die op zichzelf een aanvullende reeks ‘onechte’ effecten vormen die we hebben geaccepteerd als corollarissen van de beperkingen en eigenaardigheden van live-streaming.
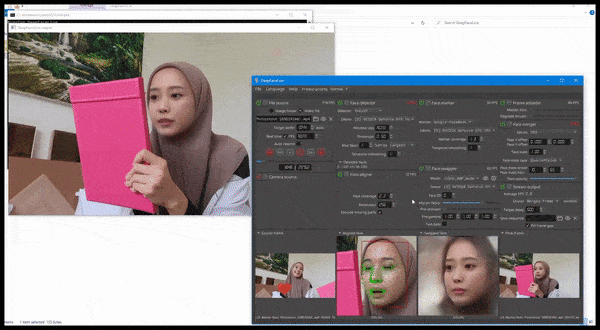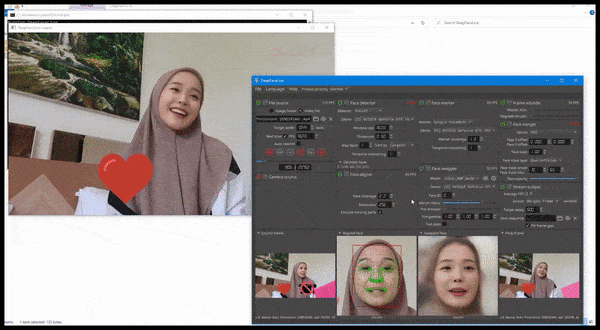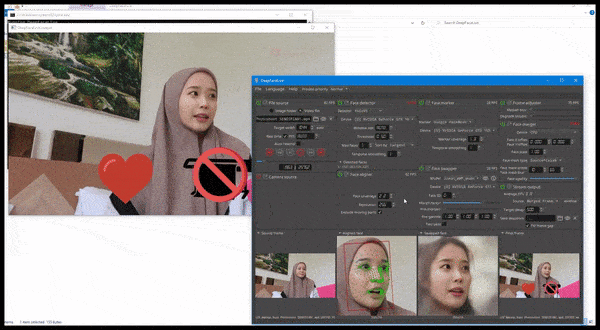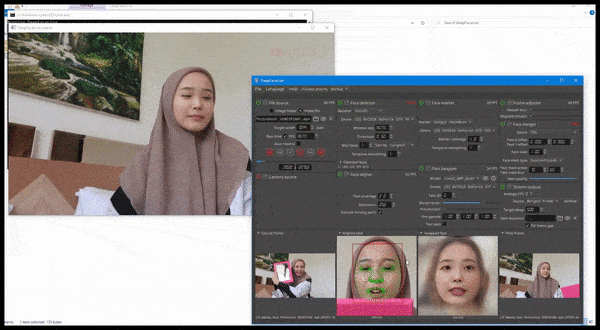
DeepFaceLive in actie: deze streamingversie van de premier deepfakesoftware DeepFaceLab kan contextueel realisme bieden door vervalsingen te presenteren in de context van beperkte videokwaliteit, complete met afspeelproblemen en andere terugkerende verbindingartefacten. Bron: https://www.youtube.com/watch?v=IL517EgYH8U
Ingebouwde degradatie
Inderdaad bevatten de twee meest populaire deepfake-pakketten (beide afgeleid van de omstreden broncode van 2017) componenten die zijn bedoeld om het deepfaked gezicht te integreren in de context van ‘historische’ of lagere kwaliteit video door het gegenereerde gezicht te degraderen. In DeepFaceLab wordt dit bereikt met de bicubic_degrade_power-parameter, en in FaceSwap helpt de ‘grain’-instelling in de Ffmpeg-configuratie eveneens bij de integratie van het valse gezicht door de korrel te behouden tijdens het coderen*.

De ‘grain’-instelling in FaceSwap helpt bij de authentieke integratie in niet-HQ-videomateriaal en legacy-inhoud die mogelijk filmmateriaal-effecten kan bevatten die tegenwoordig relatief zeldzaam zijn.
Vaak zal in plaats van een complete en geïntegreerde deepfake-video, deepfakers een geïsoleerde reeks PNG-bestanden met alfakanalen uitvoeren, waarbij elke afbeelding alleen het synthetische gezicht weergeeft, zodat de beeldstroom kan worden omgezet in video op platforms met meer geavanceerde ‘degraderende’ effectmogelijkheden, zoals Adobe After Effects, voordat de valse en echte elementen worden samengevoegd voor de eindvideo.
Naast deze opzettelijke degradaties wordt de inhoud van deepfake-werk vaak opnieuw gecomprimeerd, hetzij algoritme (waar socialemediaplatforms proberen bandbreedte te besparen door lichtere versies van gebruikersuploads te produceren) op platforms zoals YouTube en Facebook, of door het oorspronkelijke werk om te zetten in geanimeerde GIF’s, detailsecties of andere divers gemotiveerde workflows die het oorspronkelijke uitgangspunt behandelen als een startpunt en vervolgens extra compressie introduceren.
Realistische deepfake-detectiecontexten
Met dit in gedachten heeft een nieuw artikel uit Zwitserland een herziening van de methodologie achter deepfake-detectiebenaderingen voorgesteld, door detectiesystemen te leren de kenmerken van deepfake-inhoud te leren wanneer deze wordt gepresenteerd in opzettelijk verslechterde contexten.

Stochastische gegevensaugmentatie toegepast op een van de datasets die in het nieuwe artikel worden gebruikt, met Gaussische ruis, gamma-correktie en Gaussische vervaagding, evenals artefacten van JPEG-compressie. Bron: https://arxiv.org/pdf/2203.11807.pdf
In het nieuwe artikel betogen de onderzoekers dat baanbrekende deepfake-detectiepakketten afhankelijk zijn van onrealistische benchmarkvoorwaarden voor de context van de metrics die ze toepassen, en dat ‘verslechterde’ deepfake-uitvoer onder de minimale kwaliteitsdrempel voor detectie kan vallen, hoewel hun realistisch ‘vuile’ inhoud waarschijnlijk kijkers zal misleiden vanwege een correcte aandacht voor context.
De onderzoekers hebben een nieuw ‘real-world’ gegevensdegradatieproces ingesteld dat erin slaagt de generaliseerbaarheid van toonaangevende deepfake-detectoren te verbeteren, met slechts een marginale verlies van nauwkeurigheid op de oorspronkelijke detectietarieven die worden behaald met ‘schone’ gegevens. Ze bieden ook een nieuw evaluatiekader dat de robuustheid van deepfake-detectoren in real-world-omstandigheden kan beoordelen, ondersteund door uitgebreide ablatiestudies.
Het artikel heeft de titel Een nieuwe benadering om leergerichte deepfake-detectie in realistische omstandigheden te verbeteren en komt van onderzoekers aan de Multimedia Signal Processing Group (MMSPG) en de Ecole Polytechnique Federale de Lausanne (EPFL), beide gevestigd in Lausanne.
Nuttige verwarring
Eerdere pogingen om verslechterde uitvoer in deepfake-detectiebenaderingen op te nemen, omvatten de Mixup-neuraal netwerk, een aanbod van 2018 van MIT en FAIR, en AugMix, een samenwerking van 2020 tussen DeepMind en Google, beide gegevensaugmentatiemethoden die proberen de trainingsmateriaal ‘te vertroebelen’ op een manier die geneigd is om generalisatie te helpen.
De onderzoekers van het nieuwe werk merken ook eerder studies op die Gaussische ruis en compressie-artefacten hebben toegepast op trainingsgegevens om de grenzen van de relatie tussen een afgeleide functie en de ruis waarin het is ingebed te vestigen.
Het nieuwe onderzoek biedt een pijplijn die de gecompromitteerde omstandigheden van zowel het acquisitieproces voor beeldvorming als de compressie en diverse andere algoritmen die de beelduitvoer in de distributieprocedure verder kunnen verslechteren, simuleert. Door deze real-world-workflow in een evaluatiekader op te nemen, is het mogelijk om trainingsgegevens voor deepfake-detectoren te produceren die meer bestand zijn tegen artefacten.

De conceptuele logica en workflow voor de nieuwe benadering.
De degradatieproces werd toegepast op twee populaire en succesvolle datasets die worden gebruikt voor deepfake-detectie: FaceForensics++ en Celeb-DFv2. Bovendien werden toonaangevende deepfake-detectieframeworks Capsule-Forensics en XceptionNet getraind op de vervalste versies van de twee datasets.
De detectors werden getraind met de Adam-optimizer voor 25 en 10 epochs respectievelijk. Voor de datasettransformatie werden 100 frames willekeurig bemonsterd uit elke trainingsvideo, met 32 frames geëxtraheerd voor testen, voordat de degraderingsprocessen werden toegevoegd.
De distorties die in de workflow werden overwogen, waren ruis, waarbij zero-mean Gaussische ruis werd toegepast op zes verschillende niveaus; herdimensionering, om de verlaagde resolutie van typische buitenvideo’s te simuleren, die typisch detectors kan beïnvloeden; compressie, waarbij variabele JPEG-compressieniveaus werden toegepast op de gegevens; vervaging, waarbij drie typische vervagingsfilters die in ‘denoising’ worden gebruikt, werden geëvalueerd voor het kader; verbetering, waarbij contrast en helderheid werden aangepast; en combinaties, waarbij een mengsel van drie van de bovengenoemde methoden tegelijk werd toegepast op één afbeelding.
Testen en resultaten
Bij het testen van de gegevens namen de onderzoekers drie metrics: Accuracie (ACC); Oppervlakte Onder de Ontvanger-Operatie-Karakteristieke Curve (AUC); en F1-score.
De onderzoekers testten de standaardgetrainde versies van de twee deepfake-detectoren tegen de vervalste gegevens en vonden ze tekort:
‘In het algemeen zijn de meeste realistische distorties en verwerkingen uiterst schadelijk voor normaal getrainde leergerichte deepfake-detectoren. Bijvoorbeeld, de Capsule-Forensics-methode toont zeer hoge AUC-scores op zowel ongecomprimeerde FFpp als Celeb-DFv2-testset na training op respectievelijke datasets, maar lijdt vervolgens aan een drastische prestatieverbetering op gewijzigde gegevens uit ons evaluatiekader. Soortgelijke trends zijn waargenomen met de XceptionNet-detector.’
In tegenstelling tot de prestaties van de twee detectors werden aanzienlijk verbeterd door training op de getransformeerde gegevens, waarbij elke detector nu beter in staat was om ongeziene bedrieglijke media te detecteren.
‘Het gegevensaugmentatieschema verbetert de robuustheid van de twee detectors aanzienlijk en ze behouden tegelijkertijd een hoge prestatie op originele, ongewijzigde gegevens.’

Prestatievergelijkingen tussen de ruwe en aangevulde datasets die in de studie worden gebruikt voor de twee deepfake-detectoren.
Het artikel concludeert:
‘Huidige detectiemethoden zijn ontworpen om zo hoog mogelijke prestaties te behalen op specifieke benchmarks. Dit resulteert vaak in het opofferen van de generaliseerbaarheid voor meer realistische scenario’s. In dit artikel wordt een zorgvuldig geconceerde gegevensaugmentatieschema op basis van een natuurlijk beelddegradatieproces voorgesteld.
‘Uitgebreide experimenten laten zien dat de eenvoudige maar effectieve techniek de robuustheid van het model aanzienlijk verbetert tegenover diverse realistische distorties en verwerkingsoperaties in typische beeldverwerkingsworkflows.’
* Overeenkomende korrel in het gegenereerde gezicht is een functie van stijltransfer tijdens het omzettingsproces.
Origineel gepubliceerd op 29 maart 2022. Bijgewerkt om 20:33 uur EST om de korrelgebruik in Ffmpeg te verduidelijken.












