
Artificial Intelligence
Deepfake-detectoren bewandelen nieuwe wegen: latente diffusiemodellen en GAN's

Advies De laatste tijd is de onderzoeksgemeenschap voor deepfake-detectie, die zich sinds eind 2017 bijna uitsluitend bezighoudt met de auto-encoder-gebaseerd raamwerk dat op dat moment in première ging tot zoveel publiek ontzag (en ontzetting), is forensisch geïnteresseerd geraakt in minder stagnerende architecturen, waaronder latente diffusie modellen zoals: DALL-E2 en Stabiele diffusie, evenals de output van Generative Adversarial Networks (GAN's). Bijvoorbeeld in juni, UC Berkeley publiceerde de resultaten van haar onderzoek naar de ontwikkeling van een detector voor de uitgang van de toen dominante DALL-E 2.
Wat deze groeiende interesse lijkt te stimuleren, is de plotselinge evolutionaire sprong in het vermogen en de beschikbaarheid van latente diffusiemodellen in 2022, met de closed-source en limited-access los van DALL-E 2 in het voorjaar, in de nazomer gevolgd door de sensationele open source van stabiele diffusie door stabiliteit.ai.
GAN's zijn ook geweest lang bestudeerd in deze context, hoewel minder intensief, aangezien het is zeer moeilijk om ze te gebruiken voor overtuigende en uitgebreide op video gebaseerde recreaties van mensen; tenminste, vergeleken met de inmiddels eerbiedwaardige autoencoder-pakketten zoals gezicht wisselen en DeepFaceLab – en diens neef die live streamt, DeepFaceLive.
Afbeeldingen verplaatsen
In beide gevallen lijkt de stimulerende factor het vooruitzicht van een volgende ontwikkelingssprint te zijn video- synthese. De start van oktober – en het grote conferentieseizoen van 2022 – werd gekenmerkt door een lawine van plotselinge en onverwachte oplossingen voor verschillende langdurige bugbears van videosynthese: Facebook had niet eerder vrijgegeven monsters van zijn eigen tekst-naar-video-platform, dan overstemde Google Research al snel die aanvankelijke toejuiching door zijn nieuwe Imagen-to-Video T2V-architectuur aan te kondigen, die in staat is om beeldmateriaal in hoge resolutie (zij het alleen via een 7-laags netwerk van upscalers).
Als je denkt dat dit soort dingen in drieën komt, overweeg dan ook de raadselachtige belofte van stabiliteit.ai dat 'video komt' naar Stable Diffusion, blijkbaar later dit jaar, terwijl Stable Diffusion mede-ontwikkelaar Runway heeft een soortgelijke toezegging gedaan, hoewel het onduidelijk is of ze naar hetzelfde systeem verwijzen. De Onenigheid bericht van Stability's CEO Emad Mostaque beloofde ook 'audio, video [en] 3d'.
Wat met een out-of-the-blue aanbod van verschillende nieuwe kaders voor het genereren van audio (sommige gebaseerd op latente diffusie), en een nieuw diffusiemodel dat kan genereren authentieke karakterbeweging, het idee dat 'statische' frameworks zoals GAN's en diffusors eindelijk hun plaats zullen innemen als ondersteuning adjuncten naar externe animatieframeworks begint echt grip te krijgen.
Kortom, het lijkt waarschijnlijk dat de verlamde wereld van op autoencoder gebaseerde video-deepfakes, die alleen effectief de centrale deel van een gezicht, zou volgend jaar rond deze tijd kunnen worden overschaduwd door een nieuwe generatie op diffusie gebaseerde deepfake-compatibele technologieën - populaire, open source-benaderingen met het potentieel om niet alleen hele lichamen, maar hele scènes fotorealistisch te vervalsen.
Om deze reden begint de anti-deepfake-onderzoeksgemeenschap misschien beeldsynthese serieus te nemen en te beseffen dat het meer doelen kan dienen dan alleen het genereren van valse LinkedIn-profielfoto's; en dat als al hun hardnekkige latente ruimtes kunnen volbrengen in termen van temporele beweging fungeren als een echt geweldige textuur-renderer, dat zou eigenlijk meer dan genoeg kunnen zijn.
Blade Runner
De laatste twee artikelen die respectievelijk latente diffusie en GAN-gebaseerde deepfake-detectie behandelen, zijn respectievelijk DE-FAKE: Detectie en attributie van valse afbeeldingen gegenereerd door tekst-naar-beeld diffusiemodellen, een samenwerking tussen het CISPA Helmholtz Center for Information Security en Salesforce; En BLADERUNNER: snelle tegenmaatregel voor synthetische (AI-gegenereerde) StyleGAN-gezichten, van Adam Dorian Wong van het Lincoln Laboratory van het MIT.
Alvorens de nieuwe methode uit te leggen, neemt het laatste artikel enige tijd om eerdere benaderingen te onderzoeken om te bepalen of een afbeelding al dan niet is gegenereerd door een GAN (het artikel gaat specifiek over NVIDIA's StyleGAN-familie).
De 'Brady Bunch'-methode – misschien een zinloze verwijzing voor iedereen die in de jaren 1970 geen tv aan het kijken was, of die de filmaanpassingen uit de jaren 1990 heeft gemist: identificeert GAN-vervalste inhoud op basis van de vaste posities die bepaalde delen van een GAN-gezicht zeker zullen innemen, vanwege de uit het hoofd en op sjablonen gebaseerde aard van de 'productieproces'.

De 'Brady Bunch'-methode voorgesteld door een webcast van het SANS-instituut in 2022: een op GAN gebaseerde gezichtsgenerator zal in bepaalde gevallen een onwaarschijnlijk uniforme plaatsing van bepaalde gelaatstrekken uitvoeren, waardoor de oorsprong van de foto wordt gelogenstraft. Bron: https://arxiv.org/ftp/arxiv/papers/2210/2210.06587.pdf
Een andere nuttige bekende indicatie is het frequente onvermogen van StyleGAN om meerdere gezichten weer te geven (eerste afbeelding hieronder), evenals het gebrek aan talent voor accessoirecoördinatie (middelste afbeelding hieronder), en de neiging om een haarlijn te gebruiken als het begin van een geïmproviseerde video. hoed (derde afbeelding hieronder).

De derde methode waarop de onderzoeker de aandacht vestigt is foto-overlay (een voorbeeld hiervan is te zien in ons artikel van augustus over AI-ondersteunde diagnose van psychische stoornissen), die compositorische 'image blending'-software gebruikt, zoals de CombineZ-serie om meerdere afbeeldingen samen te voegen tot één afbeelding, waarbij vaak onderliggende overeenkomsten in structuur worden onthuld - een mogelijke indicatie van synthese.

De architectuur die in het nieuwe artikel wordt voorgesteld, is getiteld (mogelijk tegen alle SEO-adviezen in) Blade Runner, verwijzend naar de Voight-Kampff-test dat bepaalt of antagonisten in de sci-fi-franchise 'nep' zijn of niet.
De pijplijn bestaat uit twee fasen, de eerste is de PapersPlease-analysator, die gegevens kan evalueren die zijn verzameld van bekende GAN-face-websites zoals thispersondoesnotexist.com of generated.photos.

Hoewel een verkorte versie van de code kan worden geïnspecteerd op GitHub (zie hieronder), worden er weinig details gegeven over deze module, behalve dat OpenCV en DLIB worden gebruikt om gezichten in het verzamelde materiaal te schetsen en te detecteren.
De tweede module is de Onder ons detector. Het systeem is ontworpen om te zoeken naar gecoördineerde oogplaatsing in foto's, een blijvend kenmerk van StyleGAN's gezichtsoutput, getypeerd in het hierboven beschreven 'Brady Bunch'-scenario. AmongUs wordt aangedreven door een standaard 68-landmark-detector.

Annotaties van gezichtspunten via de Intelligent Behavior Understanding Group (IBUG), waarvan de plotcode voor gezichtsoriëntatiepunten wordt gebruikt in het Blade Runner-pakket.
AmongUs is afhankelijk van vooraf getrainde oriëntatiepunten op basis van de bekende 'Brady-bundel'-coördinaten van PapersPlease, en is bedoeld voor gebruik tegen live, webgerichte voorbeelden van op StyleGAN gebaseerde gezichtsafbeeldingen.
Blade Runner, zo suggereert de auteur, is een plug-and-play-oplossing die bedoeld is voor bedrijven of organisaties die niet over de middelen beschikken om interne oplossingen te ontwikkelen voor het soort deepfake-detectie dat hier wordt behandeld, en een 'stop-gap-maatregel om tijd te winnen voor meer permanente tegenmaatregelen'.
In een beveiligingssector die zo volatiel en snelgroeiend is, zijn er niet veel op maat gemaakte or kant-en-klare oplossingen van cloudleveranciers waarop een bedrijf met onvoldoende middelen momenteel met vertrouwen terecht kan.
Hoewel Blade Runner slecht presteert tegen bebrild StyleGAN-vervalste mensen, dit is een relatief veel voorkomend probleem bij vergelijkbare systemen, die verwachten oogafbakeningen te kunnen evalueren als kernreferentiepunten, in dergelijke gevallen verduisterd.
Er is een verkleinde versie van Blade Runner geweest uitgebracht om source op GitHub te openen. Er bestaat een eigen versie met meer functies, die meerdere foto's kan verwerken in plaats van de enkele foto per bewerking van de open source-repository. De auteur is van plan, zegt hij, om de GitHub-versie uiteindelijk naar dezelfde standaard te upgraden, als de tijd het toelaat. Hij geeft ook toe dat StyleGAN waarschijnlijk verder zal evolueren dan zijn bekende of huidige zwakheden, en dat de software zich ook samen zal moeten ontwikkelen.
DE-FAKE
De DE-FAKE-architectuur heeft niet alleen tot doel 'universele detectie' te bereiken voor afbeeldingen die worden geproduceerd door tekst-naar-beeld-diffusiemodellen, maar ook om een methode te bieden om welke latente diffusie (LD) -model produceerde het beeld.
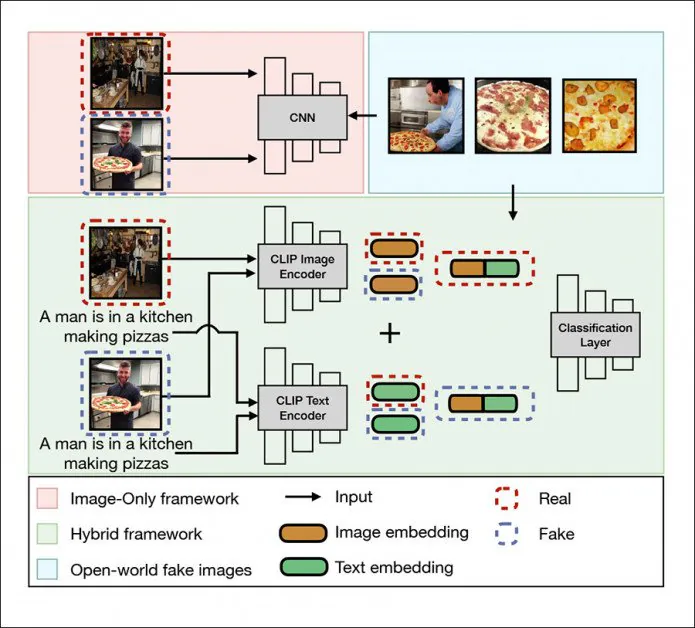
Het universele detectieraamwerk in DE-FAKE richt zich op lokale afbeeldingen, een hybride raamwerk (groen) en open wereldbeelden (blauw). Bron: http://export.arxiv.org/pdf/2210.06998
Eerlijk gezegd is dat op dit moment een vrij gemakkelijke taak, aangezien alle populaire LD-modellen – closed of open source – opmerkelijke onderscheidende kenmerken hebben.
Bovendien delen de meesten een aantal gemeenschappelijke zwakheden, zoals de neiging om hoofden af te hakken vanwege de willekeurige manier dat niet-vierkante webgeschraapte afbeeldingen worden opgenomen in de enorme datasets die systemen zoals DALL-E 2, Stable Diffusion en MidJourney aandrijven:

Latente diffusiemodellen vereisen, net als alle computer vision-modellen, invoer in vierkant formaat; maar de totale web-scraping die de LAION5B-dataset voedt, biedt geen 'luxe extra's', zoals de mogelijkheid om gezichten (of iets anders) te herkennen en erop te focussen, en kapt afbeeldingen behoorlijk brutaal af in plaats van ze op te vullen (waardoor de hele bron zou behouden blijven). afbeelding, maar met een lagere resolutie). Eenmaal getraind, worden deze 'gewassen' genormaliseerd en komen ze zeer vaak voor in de output van latente diffusiesystemen zoals Stable Diffusion. Bronnen: https://blog.novelai.net/novelai-improvements-on-stable-diffusion-e10d38db82ac en Stable Diffusion.
DE-FAKE is bedoeld om algoritme-agnostisch te zijn, een langgekoesterd doel van autoencoder anti-deepfake-onderzoekers, en op dit moment redelijk haalbaar met betrekking tot LD-systemen.
De architectuur maakt gebruik van OpenAI's Contrastive Language-Image Pretraining (CLIP) multimodale bibliotheek – een essentieel element in stabiele diffusie, en hard op weg het hart te worden van de nieuwe golf van beeld-/videosynthesesystemen – als een manier om inbeddingen uit 'vervalste' LD-beelden te extraheren en een classificator te trainen op de waargenomen patronen en klassen.
In een meer 'black box'-scenario, waar de PNG-brokken die informatie bevatten over het generatieproces al lang zijn verwijderd door uploadprocessen en om andere redenen, gebruiken de onderzoekers de Salesforce BLIP-framework (ook onderdeel van minstens een distributie van Stable Diffusion) om 'blind' de afbeeldingen te pollen op de waarschijnlijke semantische structuur van de prompts die ze hebben gemaakt.

De onderzoekers gebruikten Stable Diffusion, Latent Diffusion (zelf een afzonderlijk product), GLIDE en DALL-E 2 om een trainings- en testdataset te vullen met behulp van MSCOCO en Flickr30k.
Normaal zouden we voor een nieuw raamwerk vrij uitgebreid kijken naar de resultaten van de experimenten van de onderzoekers; maar in werkelijkheid lijken de bevindingen van DE-FAKE waarschijnlijk nuttiger als toekomstige benchmark voor latere iteraties en soortgelijke projecten, in plaats van als een zinvolle maatstaf voor projectsucces, gezien de vluchtige omgeving waarin het opereert en het systeem dat het waartegen het in de onderzoeken van de krant concurreert, is bijna drie jaar oud – uit de tijd dat de beeldsynthese-scène echt in opkomst was.

De twee meest linkse afbeeldingen: het 'betwiste' eerdere raamwerk, ontstaan in 2019, presteerde voorspelbaar minder goed tegen DE-FAKE (meest rechtse twee afbeeldingen) over de vier geteste LD-systemen.
De resultaten van het team zijn om twee redenen overweldigend positief: er is weinig eerder werk om het mee te vergelijken (en helemaal geen dat een eerlijke vergelijking biedt, dat wil zeggen, dat de slechts twaalf weken beslaat sinds Stable Diffusion werd vrijgegeven voor open source).
Ten tweede, zoals hierboven vermeld, hoewel het LD-beeldsyntheseveld zich exponentieel ontwikkelt, wordt de uitvoerinhoud van het huidige aanbod effectief van een watermerk voorzien door zijn eigen structurele (en zeer voorspelbare) tekortkomingen en excentriciteiten - waarvan er vele waarschijnlijk zullen worden verholpen, in het geval van Stable Diffusion tenminste, door de release van het beter presterende 1.5 checkpoint (dwz het getrainde model van 4 GB dat het systeem aandrijft).
Tegelijkertijd heeft Stability al aangegeven een duidelijke roadmap te hebben voor V2 en V3 van het systeem. Gezien de gebeurtenissen van de afgelopen drie maanden die de krantenkoppen haalden, is elke zakelijke verdoving van de kant van OpenAI en andere concurrerende spelers op het gebied van beeldsynthese waarschijnlijk verdampt, wat betekent dat we een vergelijkbaar snel tempo van vooruitgang kunnen verwachten, ook in de ruimte voor beeldsynthese met gesloten bron.
Voor het eerst gepubliceerd op 14 oktober 2022.















