Kunstmatige intelligentie
Complete Gids over Gemma 2: Google’s Nieuwe Open Large Language Model

Gemma 2 bouwt voort op zijn voorganger, met verbeterde prestaties en efficiëntie, evenals een reeks innovatieve functies die het bijzonder aantrekkelijk maken voor zowel onderzoek als praktische toepassingen. Wat Gemma 2 onderscheidt, is zijn vermogen om prestaties te leveren die vergelijkbaar zijn met veel grotere propriëtaire modellen, maar in een pakket dat is ontworpen voor bredere toegankelijkheid en gebruik op bescheidener hardware-opstellingen.
Toen ik me verdiepte in de technische specificaties en architectuur van Gemma 2, werd ik steeds meer onder de indruk van de vernuftigheid van zijn ontwerp. Het model omvat verschillende geavanceerde technieken, waaronder novate aandachtmechanismen en innovatieve benaderingen van trainingsstabiliteit, die bijdragen aan zijn opmerkelijke mogelijkheden.

Google Open Source LLM Gemma
In deze uitgebreide gids zullen we Gemma 2 diepgaand onderzoeken, waarbij we zijn architectuur, belangrijkste functies en praktische toepassingen zullen bekijken. Of u nu een ervaren AI-praktijk bent of een enthousiaste nieuwkomer in het veld, dit artikel heeft als doel waardevolle inzichten te bieden in hoe Gemma 2 werkt en hoe u zijn kracht in uw eigen projecten kunt benutten.
Wat is Gemma 2?
Gemma 2 is Google’s nieuwste open-source large language model, ontworpen om lichtgewicht yet krachtig te zijn. Het is gebouwd op dezelfde onderzoek en technologie die gebruikt werd om Google’s Gemini-modellen te creëren, met state-of-the-art prestaties in een toegankelijker pakket. Gemma 2 komt in twee maten:
Gemma 2 9B: Een 9 miljard parameter model
Gemma 2 27B: Een groter 27 miljard parameter model
Elke maat is beschikbaar in twee varianten:
Basismodellen: Voorgetraind op een uitgebreide verzameling tekstgegevens
Instruction-tuned (IT) modellen: Fijngesteld voor betere prestaties op specifieke taken
Toegang tot de modellen in Google AI Studio: Google AI Studio – Gemma 2
Lees het paper hier: Gemma 2 Technical Report
Belangrijkste functies en verbeteringen
Gemma 2 introduceert verschillende significante verbeteringen ten opzichte van zijn voorganger:
1. Verhoogde trainingsgegevens
De modellen zijn getraind op aanzienlijk meer gegevens:
Gemma 2 27B: Getraind op 13 biljoen tokens
Gemma 2 9B: Getraind op 8 biljoen tokens
Deze uitgebreide dataset, voornamelijk bestaande uit webgegevens (voornamelijk Engels), code en wiskunde, draagt bij aan de verbeterde prestaties en veelzijdigheid van de modellen.
2. Sliding Window Attention
Gemma 2 implementeert een novate benadering van aandachtmechanismen:
Elke andere laag gebruikt een sliding window attention met een lokale context van 4096 tokens
Alternatieve lagen gebruiken volledige kwadratische globale aandacht over de hele 8192 token context
Deze hybride benadering heeft als doel efficiëntie te balanceren met het vermogen om lange-afstandsafhankelijkheden in de invoer te detecteren.
3. Soft-Capping
Om de trainingsstabiliteit en prestaties te verbeteren, introduceert Gemma 2 een soft-capping mechanisme:
def soft_cap(x, cap): return cap * torch.tanh(x / cap) # Toegepast op aandachtlogits attention_logits = soft_cap(attention_logits, cap=50.0) # Toegepast op finale laaglogits final_logits = soft_cap(final_logits, cap=30.0)
Deze techniek voorkomt dat logit groeit excessief groot zonder harde truncatie, waardoor meer informatie behouden blijft en de trainingsprocessen worden gestabiliseerd.
- Gemma 2 9B: Een 9 miljard parameter model
- Gemma 2 27B: Een groter 27 miljard parameter model
Elke maat is beschikbaar in twee varianten:
- Basismodellen: Voorgetraind op een uitgebreide verzameling tekstgegevens
- Instruction-tuned (IT) modellen: Fijngesteld voor betere prestaties op specifieke taken
4. Kennisoverdracht
Voor het 9B-model gebruikt Gemma 2 kennisoverdrachttechnieken:
- Pre-training: Het 9B-model leert van een groter teacher-model tijdens de initiële training
- Post-training: Zowel 9B als 27B-modellen gebruiken on-policy distillatie om hun prestaties te verfijnen
Dit proces helpt het kleinere model om de capaciteiten van grotere modellen effectiever te benutten.
5. Modelmerging
Gemma 2 gebruikt een novate modelmergingtechniek genaamd Warp, die meerdere modellen combineert in drie stadia:
- Exponentiële Moving Average (EMA) tijdens versterking learning fine-tuning
- Spherical Linear intERPolation (SLERP) na fine-tuning van meerdere policies
- Lineaire Interpolatie naar Initialisatie (LITI) als laatste stap
Deze benadering heeft als doel een robuuster en capabeler eindmodel te creëren.
Prestatiebenchmarks
Gemma 2 toont indrukwekkende prestaties over verschillende benchmarks:
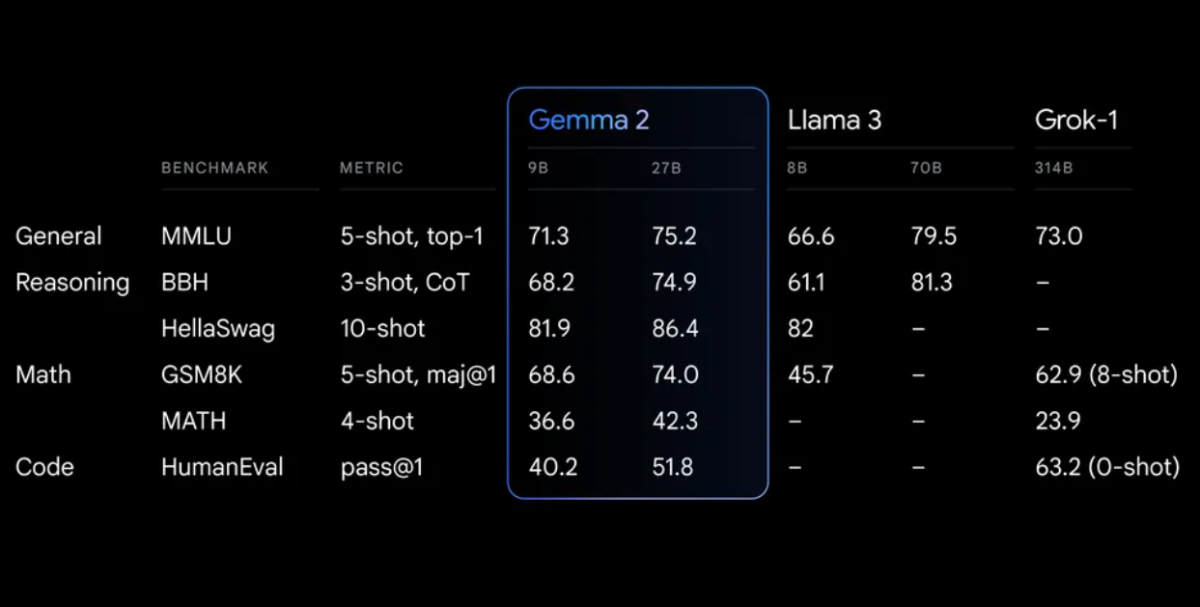
Gemma 2 op een herontworpen architectuur, ontworpen voor zowel uitzonderlijke prestaties als inferentie-efficiëntie
Aan de slag met Gemma 2
Om Gemma 2 te gebruiken in uw projecten, heeft u verschillende opties:
1. Google AI Studio
Voor snelle experimenten zonder hardwarevereisten, kunt u Gemma 2 toegang via Google AI Studio.
2. Hugging Face Transformers
Gemma 2 is geïntegreerd met de populaire Hugging Face Transformers-bibliotheek. Hier is hoe u het kunt gebruiken:
<div class="relative flex flex-col rounded-lg"> <div class="text-text-300 absolute pl-3 pt-2.5 text-xs"> from transformers import AutoTokenizer, AutoModelForCausalLM # Laad het model en tokenizer model_name = "google/gemma-2-27b-it" # of "google/gemma-2-9b-it" voor de kleinere versie tokenizer = AutoTokenizer.from_pretrained(model_name) model = AutoModelForCausalLM.from_pretrained(model_name) # Bereid invoer voor prompt = "Leg het concept van quantum entanglement uit in eenvoudige bewoordingen." inputs = tokenizer(prompt, return_tensors="pt") # Genereer tekst outputs = model.generate(**inputs, max_length=200) response = tokenizer.decode(outputs[0], skip_special_tokens=True) print(response)
3. TensorFlow/Keras
Voor TensorFlow-gebruikers is Gemma 2 beschikbaar via Keras:
import tensorflow as tf
from keras_nlp.models import GemmaCausalLM
# Laad het model
model = GemmaCausalLM.from_preset("gemma_2b_en")
# Genereer tekst
prompt = "Leg het concept van quantum entanglement uit in eenvoudige bewoordingen."
output = model.generate(prompt, max_length=200)
print(output)
Geavanceerd gebruik: een lokale RAG-systeem bouwen met Gemma 2
Een krachtige toepassing van Gemma 2 is het bouwen van een Retrieval Augmented Generation (RAG)-systeem. Laten we een eenvoudig, volledig lokaal RAG-systeem maken met Gemma 2 en Nomic-embeddings.
Stap 1: omgevingsinstellingen
Zorg ervoor dat u de nodige bibliotheken geïnstalleerd heeft:
pip install langchain ollama nomic chromadb
Stap 2: documentindexeren
Maak een indexer om uw documenten te verwerken:
import os
from langchain.text_splitter import RecursiveCharacterTextSplitter
from langchain.document_loaders import DirectoryLoader
from langchain.vectorstores import Chroma
from langchain.embeddings import HuggingFaceEmbeddings
class Indexer:
def __init__(self, directory_path):
self.directory_path = directory_path
self.text_splitter = RecursiveCharacterTextSplitter(chunk_size=1000, chunk_overlap=200)
self.embeddings = HuggingFaceEmbeddings(model_name="nomic-ai/nomic-embed-text-v1")
def load_and_split_documents(self):
loader = DirectoryLoader(self.directory_path, glob="**/*.txt")
documents = loader.load()
return self.text_splitter.split_documents(documents)
def create_vector_store(self, documents):
return Chroma.from_documents(documents, self.embeddings, persist_directory="./chroma_db")
def index(self):
documents = self.load_and_split_documents()
vector_store = self.create_vector_store(documents)
vector_store.persist()
return vector_store
# Gebruik
indexer = Indexer("pad/naar/uw/documenten")
vector_store = indexer.index()
Stap 3: RAG-systeem instellen
Nu laten we het RAG-systeem maken met Gemma 2:
from langchain.llms import Ollama
from langchain.chains import RetrievalQA
from langchain.prompts import PromptTemplate
class RAGSystem:
def __init__(self, vector_store):
self.vector_store = vector_store
self.llm = Ollama(model="gemma2:9b")
self.retriever = self.vector_store.as_retriever(search_kwargs={"k": 3})
self.template = """Gebruik de volgende stukken context om de vraag aan het einde te beantwoorden.
Als u het antwoord niet weet, zegt u dat u het niet weet, probeert u geen antwoord te verzinnen.
{context}
Vraag: {question}
Antwoord: """
self.qa_prompt = PromptTemplate(
template=self.template, input_variables=["context", "question"]
)
self.qa_chain = RetrievalQA.from_chain_type(
llm=self.llm,
chain_type="stuff",
retriever=self.retriever,
return_source_documents=True,
chain_type_kwargs={"prompt": self.qa_prompt}
)
def query(self, question):
return self.qa_chain({"query": question})
# Gebruik
rag_system = RAGSystem(vector_store)
response = rag_system.query("Wat is de hoofdstad van Frankrijk?")
print(response["result"])
Dit RAG-systeem gebruikt Gemma 2 via Ollama voor het taalmodel en Nomic-embeddings voor documentopname. Het laat u toe om vragen te stellen op basis van de geïndexeerde documenten, met antwoorden met context van de relevante bronnen.
Fijntunen van Gemma 2
Voor specifieke taken of domeinen wilt u Gemma 2 mogelijk fijntunen. Hier is een basisvoorbeeld met de Hugging Face Transformers-bibliotheek:
from transformers import AutoTokenizer, AutoModelForCausalLM, TrainingArguments, Trainer
from datasets import load_dataset
# Laad model en tokenizer
model_name = "google/gemma-2-9b-it"
tokenizer = AutoTokenizer.from_pretrained(model_name)
model = AutoModelForCausalLM.from_pretrained(model_name)
# Bereid dataset voor
dataset = load_dataset("uw_dataset")
def tokenize_function(examples):
return tokenizer(examples["text"], padding="max_length", truncation=True)
tokenized_datasets = dataset.map(tokenize_function, batched=True)
# Stel trainingsargumenten in
training_args = TrainingArguments(
output_dir="./results",
num_train_epochs=3,
per_device_train_batch_size=4,
per_device_eval_batch_size=4,
warmup_steps=500,
weight_decay=0.01,
logging_dir="./logs",
)
# Initialiseer Trainer
trainer = Trainer(
model=model,
args=training_args,
train_dataset=tokenized_datasets["train"],
eval_dataset=tokenized_datasets["test"],
)
# Start fijntunen
trainer.train()
# Sla het gefijntunde model op
model.save_pretrained("./fine_tuned_gemma2")
tokenizer.save_pretrained("./fine_tuned_gemma2")
Onthoud om de trainingsparameters aan te passen op basis van uw specifieke vereisten en computationele middelen.
Ethische overwegingen en beperkingen
Terwijl Gemma 2 indrukwekkende mogelijkheden biedt, is het cruciaal om zich bewust te zijn van zijn beperkingen en ethische overwegingen:
- Vooringenomenheid: Net als alle taalmodellen kan Gemma 2 vooringenomenheden weerspiegelen die aanwezig zijn in zijn trainingsgegevens. Altijd kritisch de uitvoer evalueren.
- Feitelijke nauwkeurigheid: Hoewel zeer capabel, kan Gemma 2 soms onjuiste of inconsistentie informatie genereren. Belangrijke feiten van betrouwbare bronnen verifiëren.
- Contextlengte: Gemma 2 heeft een contextlengte van 8192 tokens. Voor langere documenten of conversaties kan het nodig zijn om strategieën te implementeren om context effectief te beheren.
- Computationele middelen: Vooral voor het 27B-model kunnen aanzienlijke computationele middelen nodig zijn voor efficiënte inferentie en fijntuning.
- Verantwoord gebruik: Houd u aan Google’s verantwoorde AI-praktijken en zorg ervoor dat uw gebruik van Gemma 2 in overeenstemming is met ethische AI-principes.
Conclusie
Gemma 2 geavanceerde functies zoals sliding window attention, soft-capping en novate modelmergingtechnieken maken het een krachtig instrument voor een breed scala aan natuurlijke taalverwerkingstaken.
Door Gemma 2 te gebruiken in uw projecten, of het nu gaat om eenvoudige inferentie, complexe RAG-systemen of gefijntunde modellen voor specifieke domeinen, kunt u de kracht van SOTA AI benutten terwijl u de controle over uw gegevens en processen behoudt.












