Kunstmatige intelligentie
ChatGPT’s Eerste Verjaardag: De Toekomst van AI-Interactie Opnieuw Vormgeven

Als we terugkijken op ChatGPT’s eerste jaar, is het duidelijk dat dit instrument de AI-scene aanzienlijk heeft veranderd. Gelanceerd aan het einde van 2022, onderscheidde ChatGPT zich door zijn gebruikersvriendelijke, conversationalistische stijl die het interactie met AI meer liet aanvoelen als een gesprek met een persoon dan met een machine. Deze nieuwe aanpak trok snel de aandacht van het publiek. Binnen vijf dagen na de release had ChatGPT al een miljoen gebruikers aangetrokken. Begin 2023 was dit aantal gestegen tot ongeveer 100 miljoen maandelijkse gebruikers, en tegen oktober trok de platform ongeveer 1,7 miljard bezoeken wereldwijd. Deze cijfers zeggen veel over zijn populariteit en nut.
In het afgelopen jaar hebben gebruikers allerlei creatieve manieren gevonden om ChatGPT te gebruiken, van eenvoudige taken zoals het schrijven van e-mails en het bijwerken van cv’s tot het starten van succesvolle bedrijven. Maar het gaat niet alleen om hoe mensen het gebruiken; de technologie zelf is gegroeid en verbeterd. Aanvankelijk was ChatGPT een gratis dienst die gedetailleerde tekstantwoorden bood. Nu is er ChatGPT Plus, dat ChatGPT-4 omvat. Deze bijgewerkte versie is getraind op meer gegevens, geeft minder verkeerde antwoorden en begrijpt complexe instructies beter.
Een van de grootste updates is dat ChatGPT op meerdere manieren kan communiceren – het kan luisteren, spreken en zelfs afbeeldingen verwerken. Dit betekent dat u via de mobiele app met hem kunt praten en hem afbeeldingen kunt laten zien om antwoorden te krijgen. Deze veranderingen hebben nieuwe mogelijkheden voor AI geopend en hebben veranderd hoe mensen tegen AI aankijken en erover denken.
Van zijn begin als technische demo tot zijn huidige status als een belangrijke speler in de technische wereld, is ChatGPT’s reis behoorlijk indrukwekkend. Aanvankelijk werd het gezien als een manier om technologie te testen en te verbeteren door feedback van het publiek te krijgen. Maar het werd snel een essentieel onderdeel van het AI-landschap. Dit succes toont aan hoe effectief het is om grote taalmodellen (LLM’s) te fijn af te stemmen met zowel begeleide als onbegeleide leermethoden en feedback van mensen. Als gevolg hiervan kan ChatGPT een breed scala aan vragen en taken aan.
De race om de meest capabele en veelzijdige AI-systemen te ontwikkelen, heeft geleid tot een toename van zowel open-source als propriëtaire modellen zoals ChatGPT. Het begrijpen van hun algemene capaciteiten vereist uitgebreide benchmarks over een breed spectrum van taken. Dit gedeelte onderzoekt deze benchmarks, waardoor duidelijk wordt hoe verschillende modellen, waaronder ChatGPT, zich verhouden tot elkaar.
Evaluatie van LLM’s: De Benchmarks
- MT-Bench: Deze benchmark test multi-turn conversaties en instructievolgcapaciteiten in acht domeinen: schrijven, rollenspel, informatie-extractie, redeneren, wiskunde, coderen, STEM-kennis en geesteswetenschappen. Sterkere LLM’s zoals GPT-4 worden gebruikt als evaluatoren.
- AlpacaEval: Gebaseerd op de AlpacaFarm-evaluatieset, benchmarkt deze LLM-gebaseerde automatische evaluator modellen tegen antwoorden van geavanceerde LLM’s zoals GPT-4 en Claude, waarbij de winstpercentage van kandidaatmodellen wordt berekend.
- Open LLM Leaderboard: Met behulp van de Language Model Evaluation Harness, evalueert deze leaderboard LLM’s op zeven belangrijke benchmarks, waaronder redeneeruitdagingen en algemene kennis-tests, in zowel zero-shot als few-shot settings.
- BIG-bench: Deze samenwerkingsbenchmark omvat meer dan 200 nieuwe taaltaken, die een breed scala aan onderwerpen en talen bestrijken. Het doel is om LLM’s te onderzoeken en hun toekomstige capaciteiten te voorspellen.
- ChatEval: Een multi-agent debatframework dat teams in staat stelt om autonoom te discussiëren en de kwaliteit van antwoorden van verschillende modellen te evalueren op open vragen en traditionele natuurlijke taalgeneratie-taken.
Vergelijkbare Prestaties
In termen van algemene benchmarks hebben open-source LLM’s aanzienlijke vooruitgang geboekt. Llama-2-70B, bijvoorbeeld, behaalde indrukwekkende resultaten, vooral na fijn afstemming met instructiegegevens. Zijn variant, Llama-2-chat-70B, blonk uit in AlpacaEval met een winstpercentage van 92,66%, waarbij GPT-3.5-turbo werd overtroffen. GPT-4 blijft echter de koploper met een winstpercentage van 95,28%.
Zephyr-7B, een kleinere model, toonde capaciteiten die vergelijkbaar zijn met grotere 70B LLM’s, vooral in AlpacaEval en MT-Bench. Ondertussen scoorde WizardLM-70B, gefinetuned met een diverse reeks instructiegegevens, het hoogst onder open-source LLM’s op MT-Bench. Het bleef echter achter bij GPT-3.5-turbo en GPT-4.
Een interessante inzending, GodziLLa2-70B, behaalde een concurrerend score op de Open LLM Leaderboard, waarmee het potentieel van experimentele modellen die diverse datasets combineren, werd aangetoond. Evenzo blonk Yi-34B, ontwikkeld van scratch, uit met scores die vergelijkbaar waren met GPT-3.5-turbo en slechts iets achter GPT-4.
UltraLlama, met zijn fijn afstemming op diverse en hoogwaardige gegevens, evenaarde GPT-3.5-turbo in zijn voorgestelde benchmarks en overtrof het zelfs op gebieden van wereld- en professionele kennis.
Op schaal: De Opkomst van Reusachtige LLM’s
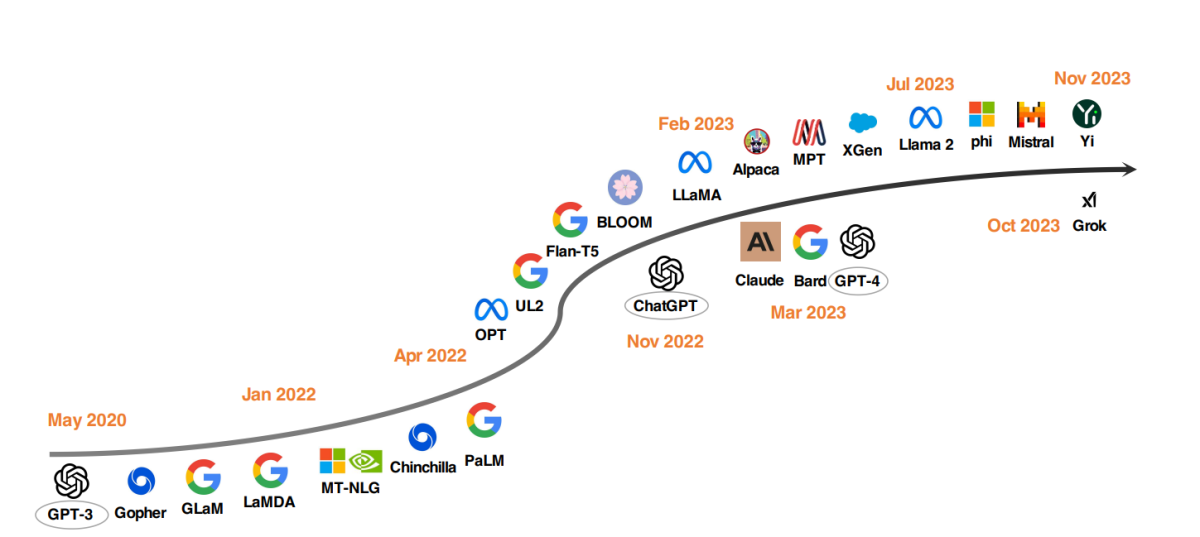
Top LLM-modellen sinds 2020
Een opvallende trend in LLM-ontwikkeling is het opschalen van modelparameters. Modellen zoals Gopher, GLaM, LaMDA, MT-NLG en PaLM hebben de grenzen verlegd, met als resultaat modellen met tot 540 miljard parameters. Deze modellen hebben uitzonderlijke capaciteiten getoond, maar hun gesloten karakter heeft hun bredere toepassing beperkt. Deze beperking heeft interesse gewekt in het ontwikkelen van open-source LLM’s, een trend die aan het groeien is.
Naast het opschalen van modelgroottes hebben onderzoekers alternatieve strategieën onderzocht. In plaats van modellen alleen maar groter te maken, hebben ze zich gericht op het verbeteren van de vooraftraining van kleinere modellen. Voorbeelden hiervan zijn Chinchilla en UL2, die hebben aangetoond dat meer niet altijd beter is; slimmere strategieën kunnen efficiënte resultaten opleveren. Bovendien is er aanzienlijke aandacht besteed aan instructieafstemming van taalmodellen, met projecten zoals FLAN, T0 en Flan-T5 die significante bijdragen leveren aan dit gebied.
De ChatGPT-Katalysator
De introductie van OpenAI’s ChatGPT markeerde een keerpunt in NLP-onderzoek. Om concurrerend te zijn met OpenAI, lanceerden bedrijven zoals Google en Anthropic hun eigen modellen, Bard en Claude, respectievelijk. Hoewel deze modellen vergelijkbare prestaties laten zien als ChatGPT in veel taken, blijven ze achter bij de laatste model van OpenAI, GPT-4. Het succes van deze modellen wordt voornamelijk toegeschreven aan versterkt leren van menselijke feedback (RLHF), een techniek die meer onderzoeksfocus krijgt voor verdere verbetering.
Geruchten en Speculaties Rond OpenAI’s Q* (Q-Star)
Recente rapporten suggereren dat onderzoekers bij OpenAI een significante doorbraak in AI hebben behaald met de ontwikkeling van een nieuw model genaamd Q* (uitgesproken als Q-ster). Volgens de geruchten heeft Q* de capaciteit om wiskunde op basisschoolniveau uit te voeren, een prestatie die discussies onder experts heeft aangewakkerd over zijn potentieel als een mijlpaal naar kunstmatige algemene intelligentie (AGI). Hoewel OpenAI geen commentaar heeft geleverd op deze rapporten, hebben de vermeende capaciteiten van Q* aanzienlijke opwinding en speculatie op sociale media en onder AI-enthousiasten gegenereerd.
De ontwikkeling van Q* is opmerkelijk omdat bestaande taalmodellen zoals ChatGPT en GPT-4, hoewel in staat om enkele wiskundige taken uit te voeren, niet bijzonder goed zijn in het betrouwbaar uitvoeren van deze taken. De uitdaging ligt in de noodzaak voor AI-modellen om niet alleen patronen te herkennen, zoals ze dat nu doen door diepe leer- en transformatoren, maar ook om te redeneren en abstracte concepten te begrijpen. Wiskunde, als een benchmark voor redeneren, vereist dat de AI plannen en meerdere stappen uitvoert, waarbij een diep begrip van abstracte concepten wordt getoond. Deze capaciteit zou een significante sprong in AI-capaciteiten markeren, mogelijk uitbreidend naar taken buiten wiskunde.
De Open-Source LLM-Beweging
Om open-source LLM-onderzoek te stimuleren, bracht Meta de Llama-serie modellen uit, waardoor een golf van nieuwe ontwikkelingen op basis van Llama ontstond. Dit omvat modellen die zijn gefinetuned met instructiegegevens, zoals Alpaca, Vicuna, Lima en WizardLM. Onderzoek vertakt zich ook naar het verbeteren van agentcapaciteiten, logisch redeneren en lang-contextmodellering binnen het Llama-gebaseerde kader.
Bovendien is er een groeiende trend in het ontwikkelen van krachtige LLM’s van scratch, met projecten zoals MPT, Falcon, XGen, Phi, Baichuan, Mistral, Grok en Yi. Deze inspanningen weerspiegelen een toewijding om de capaciteiten van gesloten LLM’s te democratiseren, waardoor geavanceerde AI-hulpmiddelen toegankelijker en efficiënter worden.
De Impact van ChatGPT en Open-Source Modellen in de Gezondheidszorg
We kijken naar een toekomst waarin LLM’s helpen bij klinische notities, formulieren invullen voor vergoedingen en artsen ondersteunen bij diagnose- en behandelplanning. Dit heeft de aandacht getrokken van zowel technologiebedrijven als gezondheidsinstellingen.
Microsofts gesprekken met Epic, een toonaangevende softwareprovider voor elektronische gezondheidsdossiers, signaleren de integratie van LLM’s in de gezondheidszorg. Initiatieven zijn al gaande bij UC San Diego Health en Stanford University Medical Center. Evenzo markeren Google’s samenwerking met Mayo Clinic en Amazon Web Services’ lancering van HealthScribe, een AI-diagnostische dienst, significante stappen in deze richting.
Echter, deze snelle implementaties wekken bezorgdheid over het afstaan van de controle over de geneeskunde aan corporate belangen. De propriëtaire aard van deze LLM’s maakt het moeilijk om ze te evalueren. Hun mogelijke wijziging of stopzetting om winst te behalen kan de patiëntenzorg, privacy en veiligheid in gevaar brengen.
De dringende behoefte is aan een open en inclusieve aanpak van LLM-ontwikkeling in de gezondheidszorg. Gezondheidsinstellingen, onderzoekers, clinici en patiënten moeten wereldwijd samenwerken om open-source LLM’s voor de gezondheidszorg te ontwikkelen. Deze aanpak, vergelijkbaar met de Trillion Parameter Consortium, zou het mogelijk maken om computationele, financiële middelen en expertise te combineren.












