Kunstmatige intelligentie
Adobe Research breidt Disentangled GAN Face Editing uit

Het is niet moeilijk om te begrijpen waarom entanglement een probleem is in beeldsynthese, omdat het vaak een probleem is in andere gebieden van het leven; bijvoorbeeld, het is veel moeilijker om kurkuma uit een curry te verwijderen dan om een augurk uit een hamburger weg te gooien, en het is praktisch onmogelijk om een kop koffie ontzoet te maken. Sommige dingen komen gewoon gebundeld.
Evenzo is entanglement een obstakel voor beeldsynthesearchitecturen die idealiter verschillende functies en concepten willen scheiden wanneer ze machine learning gebruiken om gezichten (of honden, boten, of elk ander domein) te maken of te bewerken.
Als je functies zoals leeftijd, geslacht, haarkleur, huidskleur, emotie, enzovoort, kunt scheiden, zou je het begin hebben van echte instrumentatie en flexibiliteit in een kader dat gezichtsbeelden op een echt granulair niveau kan maken en bewerken, zonder ongewenste ‘passagiers’ in deze conversies mee te nemen.

Bij maximale entanglement (boven links), kun je alleen het beeld van een geleerd GAN-netwerk naar het beeld van een andere persoon veranderen.
Dit is effectief het gebruik van de laatste AI-computervisietechnologie om iets te bereiken dat al meer dan dertig jaar geleden op andere manieren was opgelost over dertig jaar geleden.
Met een zekere mate van scheiding (‘Medium Separation’ in eerder bovenstaand beeld), is het mogelijk om stijlgebaseerde veranderingen uit te voeren, zoals haarkleur, expressie, cosmetische toepassing en beperkte hoofdrotatie, enzovoort.

Bron: FEAT: Face Editing with Attention, februari 2022, https://arxiv.org/pdf/2202.02713.pdf
Er zijn de afgelopen twee jaar verschillende pogingen gedaan om interactieve gezichtsbewerkingsomgevingen te creëren die een gebruiker in staat stellen om gezichtskenmerken te veranderen met schuifregelaars en andere traditionele UI-interacties, terwijl de kernfuncties van het doelgezicht intact blijven wanneer toevoegingen of veranderingen worden aangebracht. Echter, dit is een uitdaging gebleken vanwege de onderliggende functie/stijlentanglement in de latent ruimte van de GAN.
Bijvoorbeeld, het bril-kenmerk is vaak verweven met het leeftijd-kenmerk, wat betekent dat het toevoegen van een bril ook het ‘verouderen’ van het gezicht kan betekenen, terwijl het verouderen van het gezicht ook een bril kan toevoegen, afhankelijk van de mate van toegepaste scheiding van hoogwaardige functies (zie ‘Testen’ hieronder voor voorbeelden).
Het is vooral moeilijk om haarkleur en andere haargaspecten te veranderen zonder dat de haargangen en -dispositie opnieuw worden berekend, wat een ‘sissend’, overgangseffect geeft.

Bron: InterFaceGAN Demo (CVPR 2020), https://www.youtube.com/watch?v=uoftpl3Bj6w
Latent-to-Latent GAN Traversal
Een nieuw door Adobe geleid paper ingevoerd voor WACV 2022 biedt een novate aanpak voor deze onderliggende problemen in een paper getiteld Latent to Latent: A Learned Mapper for Identity Preserving Editing of Multiple Face Attributes in StyleGAN-generated Images.

Aanvullend materiaal van de paper Latent to Latent: A Learned Mapper for Identity Preserving Editing of Multiple Face Attributes in StyleGAN-generated Images. Hier zien we dat de basiskenmerken in het geleerde gezicht niet worden meegesleept in niet-gerelateerde veranderingen. Zie de volledige video-inbedding aan het einde van het artikel voor betere details en resolutie. Bron: https://www.youtube.com/watch?v=rf_61llRH0Q
Het paper is geleid door Adobe Applied Scientist Siavash Khodadadeh, samen met vier andere Adobe-onderzoekers en een onderzoeker van de afdeling Computerwetenschappen van de Universiteit van Central Florida.
Het stuk is interessant omdat Adobe al enige tijd in deze ruimte actief is, en het is verleidelijk om je voor te stellen dat deze functionaliteit binnenkort in een Creative Suite-project terechtkomt; maar vooral omdat de architectuur die voor het project is gecreëerd, een andere aanpak heeft voor het behouden van visuele integriteit in een GAN-gezichtsbewerker tijdens het aanbrengen van veranderingen.
De auteurs verklaren:
‘[We] trainen een neurale netwerk om een latent-to-latent-transformatie uit te voeren die de latent encoding vindt die overeenkomt met het beeld met het gewijzigde kenmerk. Aangezien de techniek one-shot is, vertrouwt het niet op een lineaire of niet-lineaire traject van de geleidelijke verandering van de kenmerken.’
‘Door het netwerk end-to-end over de volledige generatiepijplijn te trainen, kan het systeem zich aanpassen aan de latente ruimtes van standaardgeneratorarchitecturen. Conserverings eigenschappen, zoals het behouden van de identiteit van de persoon, kunnen worden gecodeerd in de vorm van trainingsverliezen. ‘
‘Eens het latent-to-latent netwerk getraind was, kan het opnieuw worden gebruikt voor willekeurige beelden zonder opnieuw te trainen.’
Dit laatste betekent dat de voorgestelde architectuur bij de eindgebruiker in een voltooide staat arriveert. Het moet nog steeds een neurale netwerk op lokale middelen uitvoeren, maar nieuwe beelden kunnen ‘ingevallen’ worden en klaar zijn voor bewerking bijna onmiddellijk, aangezien het kader voldoende losgekoppeld is om geen verdere beeldspecifieke training nodig te hebben.
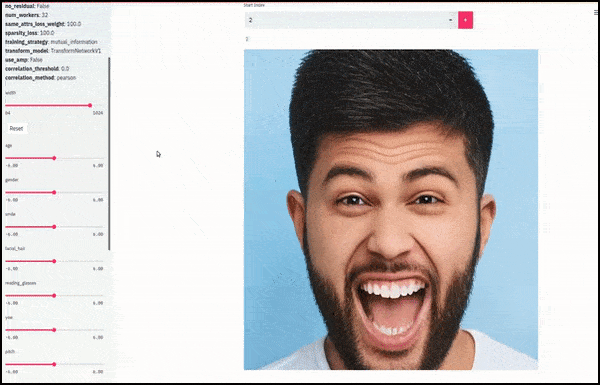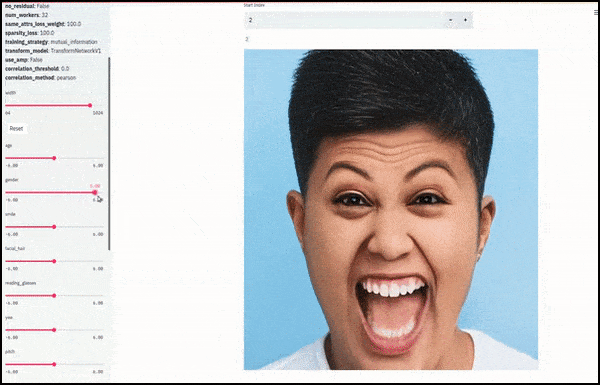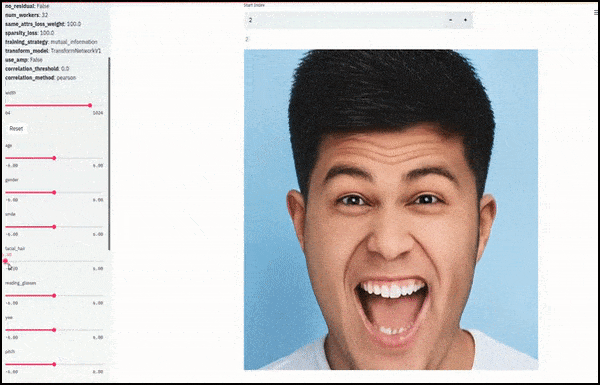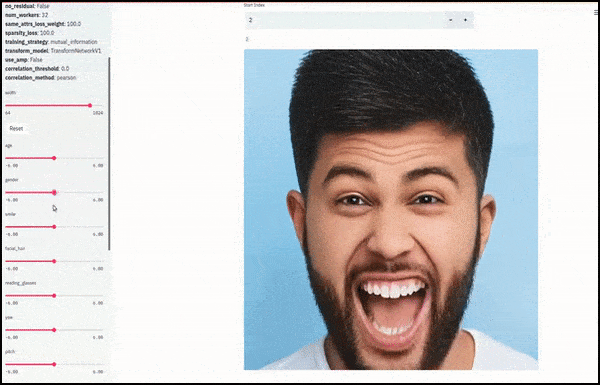
Geslacht en gezichtsbeharing veranderd terwijl schuifregelaars willekeurige en arbitrare paden door de latente ruimte tekenen, niet alleen ‘tussen eindpunten schrobben’. Zie de video-inbedding aan het einde van het artikel voor meer transformaties in betere resolutie.
Onder de belangrijkste prestaties in het werk is de mogelijkheid van het netwerk om ‘identiteiten in de latente ruimte te bevriezen’ door alleen het kenmerk in een doelvector te veranderen en ‘correctie-termen’ te bieden die identiteiten conserveren die worden getransformeerd.
In wezen is het voorgestelde netwerk ingebed in een bredere architectuur die alle verwerkte elementen orkestreert, die door vooraf getrainde componenten met bevroren gewichten passeren die geen ongewenste laterale effecten op transformaties zullen produceren.
Aangezien het trainingsproces afhankelijk is van triplets die kunnen worden gegenereerd door een zaadbeeld (onder GAN-inversie) of een bestaande initiële latente codering, is het hele trainingsproces onbegeleid, met de stilzwijgende acties van de gebruikelijke reeks label- en curatorssystemen in dergelijke systemen effectief ingebakken in de architectuur. In feite gebruikt het nieuwe systeem standaardattribuutregressors:
‘[Het] aantal kenmerken dat ons netwerk onafhankelijk kan controleren, is alleen beperkt door de mogelijkheden van de herkenner(s) – als je een herkenner voor een kenmerk hebt, kunnen we het toevoegen aan willekeurige gezichten. In onze experimenten hebben we het latent-to-latent netwerk getraind om de aanpassing van 35 verschillende gezichtskenmerken toe te staan, meer dan enige eerdere aanpak.’
Het systeem omvat een extra waarborg tegen ongewenste ‘bijwerking’-transformaties: bij afwezigheid van een verzoek om een kenmerkverandering, zal het latent-to-latent netwerk een latent vector toewijzen aan zichzelf, waardoor de stabiele persistentie van de doelidentiteit verder wordt verhoogd.
Gezichtsherkenning
Een terugkerend probleem met GAN- en encoder/decoder-gebaseerde gezichtsbewerkers van de afgelopen jaren is dat toegepaste transformaties de gelijkenis tendens tot degraderen. Om dit te bestrijden, gebruikt het Adobe-project een ingebed gezichtsherkenningnetwerk genaamd FaceNet als discriminator.

Projectarchitectuur, zie onder midden-links voor de opname van FaceNet. Bron: Latent to Latent: A Learned Mapper for Identity Preserving Editing of Multiple Face Attributes in StyleGAN-generated Images, OpenAccess.
(Als persoonlijke noot lijkt dit een bemoedigende stap naar de integratie van standaardgezichtsidentificatie- en zelfs expressieherkenningssystemen in generatieve netwerken, waarschijnlijk de beste manier om de blinde pixel>pixel-kaart die de huidige deepfake-architecturen domineert, ten koste van expressiefidelity en andere belangrijke domeinen in de gezichtsgeneratiesector, te overwinnen.)
Toegang tot alle gebieden in de latente ruimte
Een andere indrukwekkende functie van het kader is de mogelijkheid om willekeurig tussen potentiële transformaties in de latente ruimte te reizen, op gebruikerswhim. Verschillende eerdere systemen die exploratoire interfaces boden, lieten de gebruiker vaak in wezen ‘tussen vaste functietransformatietijden schrobben’ – indrukwekkend, maar vaak een lineaire of voorgeschreven ervaring.

Van Improving GAN Equilibrium by Raising Spatial Awareness: hier schrobt de gebruiker door een reeks van potentiële overgangspunten tussen twee latent ruimtelocaties, maar binnen de grenzen van vooraf getrainde locaties in de latente ruimte. Om andere soorten transformaties op basis van hetzelfde materiaal toe te passen, is opnieuw configureren en/of opnieuw trainen noodzakelijk. Bron: https://genforce.github.io/eqgan/
Bovendien kan de gebruiker handmatig ‘bevriezen’ van elementen die hij wil conserveren tijdens het transformatieproces. Op deze manier kan de gebruiker ervoor zorgen dat (bijvoorbeeld) achtergronden niet verschuiven of dat ogen open of dicht blijven.
Gegevens
Het attribuutregressienetwerk werd getraind op drie netwerken: FFHQ, CelebAMask-HQ, en een lokale, GAN-gegenereerd netwerk verkregen door 400.000 vectoren te bemonsteren uit de Z-ruimte van StyleGAN-V2.
Buiten-distributiebeelden (OOD) werden gefilterd en attributen werden geëxtraheerd met behulp van Microsoft’s Face API, met het resulterende beeldenset gesplitst in 90/10, waardoor 721.218 trainingsbeelden en 72.172 testbeelden overbleven om te vergelijken.
Testen
Hoewel het experimentele netwerk oorspronkelijk was geconfigureerd om 35 potentiële transformaties te accommoderen, werden deze teruggeschroefd tot acht om analoge testen uit te voeren tegen de vergelijkbare kaders InterFaceGAN, GANSpace, en StyleFlow.
De acht geselecteerde attributen waren Leeftijd, Kaaldheid, Baard, Expressie, Geslacht, Bril, Pitch, en Yaw. Het was noodzakelijk om de concurrerende kaders opnieuw in te richten voor sommige van de acht attributen die niet in de oorspronkelijke distributie waren voorzien, zoals het toevoegen van kaaldheid en baard aan InterFaceGAN.
Zoals verwacht, trad er een grotere mate van entanglement op in de rivaliserende architectuur. Bijvoorbeeld, in een test, veranderden InterFaceGAN en StyleFlow beiden het geslacht van de onderwerp wanneer ze werden gevraagd om leeftijd toe te passen:

Twee van de concurrerende kaders rolden een geslachtsverandering in de ‘leeftijd’-transformatie, evenals het veranderen van haarkleur zonder directe opdracht van de gebruiker.
Bovendien vonden twee van de rivalen dat bril en leeftijd onlosmakelijke facetten zijn:

Bril en haarkleurverandering erbij, zonder extra kosten!
Het is geen uniforme overwinning voor het onderzoek: zoals te zien is in de bijgevoegde video die aan het einde van het artikel is ingebed, is het kader het minst effectief wanneer het probeert om diverse hoeken (yaw) te extrapoleren, terwijl GANSpace een beter algemeen resultaat heeft voor leeftijd en het opleggen van bril. Het latent-to-latent kader maakte een gelijkspel met GANSpace en StyleFlow met betrekking tot het toevoegen van pitch (hoek van het hoofd).

Resultaten berekend op basis van een kalibratie van de MTCNN-gezichtsdetector. Lagere resultaten zijn beter.
Voor verdere details en betere resolutie van voorbeelden, bekijk de begeleidende video van het paper hieronder.
Eerst gepubliceerd op 16 februari 2022.












