
ဉာဏ်ရည်တု
Deepfake Detectors များသည် မြေပြင်အသစ်- Latent Diffusion Models နှင့် GAN များကို လိုက်ကြသည်။

သဘော နှောင်းပိုင်းတွင်၊ 2017 ခုနှစ်နှောင်းပိုင်းမှစတင်၍ သီးသန့်နီးပါးဖြစ်သော deepfake detection research community ကို၊ autoencodeထိုအချိန်က ရုံတင်ပြသခဲ့သော အခြေခံမူဘောင်ကို လူအများက အံ့အားသင့်စေခဲ့သည် (နှင့် စိတ်ပျက်စရာ) အပါအဝင် တည်ငြိမ်မှုနည်းသော ဗိသုကာပညာကို ငြင်းမရသော စိတ်ဝင်စားမှု စတင်ခဲ့သည်။ ငုပ်လျှိုးနေသော ပျံ့နှံ့မှု ကဲ့သို့သောမော်ဒယ်များ DALL-E2 နှင့် တည်ငြိမ်သောပျံ့နှံ့မှုနှင့် Generative Adversarial Networks (GANs) ၏ ထွက်ရှိမှု။ ဥပမာအားဖြင့်၊ ဇွန်လတွင် UC Berkeley ရလဒ်များကို ထုတ်ပြန်ခဲ့သည်။ ထိုအချိန်ကလွှမ်းမိုးထားသော DALL-E 2 ၏ output အတွက် detector ၏ဖွံ့ဖြိုးတိုးတက်မှုအတွက်၎င်း၏သုတေသနပြုချက်။
ဤတိုးပွားလာနေသော စိတ်ဝင်စားမှုကို တွန်းအားပေးဟန်ရှိသည့်အရာမှာ ပိတ်-ရင်းမြစ်နှင့် အကန့်အသတ်ဖြင့် ဝင်ရောက်မှုနှင့်အတူ 2022 ခုနှစ်တွင် ငုပ်လျှိုးနေသော ပျံ့နှံ့မှုပုံစံများ ရရှိနိုင်မှုနှင့် စွမ်းရည်နှင့် ရရှိနိုင်မှုတွင် ရုတ်တရက် ဆင့်ကဲခုန်တက်သွားပုံရသည်။ လွှတ်ပေး နွေဦးတွင် DALL-E 2 ၏နောက်တွင် နွေနှောင်းပိုင်းတွင် အာရုံခံစားမှုဖြင့် လိုက်ပါခဲ့သည်။ ပွင့်လင်းသောအရင်းအမြစ် stability.ai မှ Stable Diffusion ၏
GAN တွေလည်း ဖြစ်ခဲ့ပါတယ်။ ကြာရှည်စွာလေ့လာခဲ့သည်။ ဤအခြေအနေတွင်၊ အလေးအနက် နည်းပါးသော်လည်း၊ အလွန်ခက်ခဲ လူတွေရဲ့ ဗီဒီယိုအခြေခံ အပန်းဖြေမှုတွေကို ဆွဲဆောင်နိုင်စေဖို့အတွက် သူတို့ကို အသုံးပြုဖို့၊ အနည်းဆုံး၊ ယခုခေတ်တွင် ကြည်ညိုနိုင်သော autoencoder ပက်ကေ့ခ်ျများနှင့် နှိုင်းယှဉ်ပါ။ မျက်နှာလဲလှယ်ခြင်း။ နှင့် အချစ် - နှင့် နောက်ဆုံးမှ တိုက်ရိုက်ထုတ်လွှင့်သည့် ဝမ်းကွဲဝမ်းကွဲ၊ DeepFaceLive.
ရွေ့လျားပုံများ
မည်သို့ပင်ဆိုစေကာမူ၊ သွပ်ရည်စိမ်သည့်အချက်သည် နောက်ဆက်တွဲဖွံ့ဖြိုးတိုးတက်မှုအပြေးအလွှားအတွက် အလားအလာဖြစ်ပုံရသည်။ ဗီဒီယို ပေါင်းစပ်မှု။ အောက်တိုဘာလ၏အစ - နှင့် 2022 ၏အဓိကကွန်ဖရင့်ရာသီ - အမျိုးမျိုးသောကြာရှည်ခံဗီဒီယိုပေါင်းစပ်မှု bugbears အတွက်ရုတ်တရက်နှင့်မျှော်လင့်မထားသောအဖြေများပြိုကျမှုဖြင့်သွင်ပြင်လက္ခဏာဖြစ်သည်- မကြာမီ Facebook တွင်မရှိပါ နမူနာများကို ထုတ်ပြန်ခဲ့သည်။ Google Research ထက် ၎င်း၏ကိုယ်ပိုင် စာသားမှ ဗီဒီယို ပလက်ဖောင်းမှ ၎င်း၏ ရုပ်ပုံမှ ဗီဒီယို T2V ဗိသုကာလက်ရာသစ်ကို ထုတ်ပြန်ကြေညာခြင်းဖြင့် ကနဦး ချီးကျူးမှုကို လျင်မြန်စွာ တိမ်မြုပ်သွားခဲ့သည်။ မြင့်မားသော resolution ဗီဒီယို (အဆင့်မြှင့်တင်သူများ၏ 7-layer network မှတဆင့်သာသော်လည်းကောင်း)။
ဤအရာမျိုးသည် သုံးမျိုးဖြင့်လာသည်ဟု သင်ယုံကြည်ပါက Stable Diffusion တွဲဖက်တီထွင်သူ Runway တွင် 'ဗီဒီယိုလာမည်' ဟူသော Stable Diffusion သို့ ယခုနှစ်နှောင်းပိုင်းတွင် 'ဗီဒီယိုလာမည်' ဟူသော လျှို့ဝှက်ကတိကိုလည်း ထည့်သွင်းစဉ်းစားပါ။ အလားတူကတိတစ်ခုပြုခဲ့သည်။၎င်းတို့သည် တူညီသောစနစ်အား ရည်ညွှန်းခြင်းရှိမရှိ မရှင်းလင်းသော်လည်း၊ ဟိ သဘောထားကွဲလွဲမှုသတင်းစကား Stability ၏ CEO Emad Mostaque မှလည်း ကတိပြုခဲ့သည်။ 'အသံ၊ ဗီဒီယို [နှင့်] 3d'.
အပြာရောင် ဇာတာပေါင်းများစွာဖြင့် အသစ်အဆန်းတွေ ဘာတွေ အသံထုတ်လုပ်ခြင်းဘောင်များ (အချို့သော latent diffusion ကိုအခြေခံ၍) နှင့်ထုတ်လုပ်နိုင်သော diffusion model အသစ် စစ်မှန်သောဇာတ်ကောင်လှုပ်ရှားမှုGANs နှင့် diffusers ကဲ့သို့သော 'static' frameworks များသည် နောက်ဆုံးတွင် ၎င်းတို့နေရာကို ပံ့ပိုးပေးလိမ့်မည်ဟူသော အယူအဆ၊ ဆက်စပ်ပစ္စည်းများ ပြင်ပကာတွန်းဘောင်များဆီသို့ အမှန်တကယ် ဆွဲငင်အားရရှိရန် စတင်နေပြီဖြစ်သည်။
အတိုချုပ်အားဖြင့်၊ ၎င်းကို ထိထိရောက်ရောက် အစားထိုးနိုင်သည့် autoencoder-based video deepfakes ၏ တုန်လှုပ်ချောက်ချားနေသော ကမ္ဘာသည် ဖြစ်နိုင်ချေရှိသည်။ မျက်နှာတစ်ခု၏ဗဟိုအပိုင်းဤအချိန်တွင်၊ ရုပ်အလောင်းတစ်ခုလုံးသာမက မြင်ကွင်းတစ်ခုလုံးကို လက်တွေ့ကျကျ အတုလုပ်နိုင်သည့် အလားအလာရှိသော လူကြိုက်များသော၊ အဖွင့်အရင်းအမြစ် ချဉ်းကပ်မှုများနှင့်အတူ ပျံ့နှံ့မှုကို အခြေခံသည့် နက်ရှိုင်းသောအတုလုပ်နိုင်စွမ်းရှိသော နည်းပညာမျိုးဆက်သစ်ဖြင့် လာမည့်နှစ်တွင် ကွယ်ပျောက်နိုင်မည်ဖြစ်သည်။
ဤအကြောင်းကြောင့်၊ အတုအယောင်ဆန့်ကျင်ရေး သုတေသနအသိုက်အဝန်းသည် ပုံသဏ္ဌာန်ပေါင်းစပ်မှုကို အလေးအနက်ထားရန် စတင်နေပြီဖြစ်ပြီး ၎င်းသည် ဖန်တီးရုံမျှမက အဆုံးစွန်ကို အကျိုးပြုနိုင်သည်ကို သဘောပေါက်လာပေမည်။ LinkedIn ပရိုဖိုင်ပုံအတုများ; ပြီးတော့ သူတို့ရဲ့ သည်းမခံနိုင်တဲ့ ငုပ်လျှိုးနေတဲ့ နေရာတွေ အားလုံးဟာ ယာယီရွေ့လျားမှု သတ်မှတ်ချက်တွေနဲ့ ပြီးမြောက်နိုင်ရင်၊ တကယ်ကို ကောင်းမွန်တဲ့ texture renderer အဖြစ် ဆောင်ရွက်ပါ။တကယ်တော့ လုံလောက်သည်ထက် ပိုနေနိုင်သည်။
Blade ကို Runner
အသီးသီး ကိုင်တွယ်ဖြေရှင်းရမည့် နောက်ဆုံးစာတမ်းနှစ်စောင်၊ DE-FAKE- Text-to-Image Diffusion Models မှ ဖန်တီးထုတ်လုပ်ထားသော အတုပုံများကို ရှာဖွေခြင်းနှင့် ရည်ညွှန်းခြင်းသတင်းအချက်အလက်လုံခြုံရေးနှင့် Salesforce အတွက် CISPA Helmholtz စင်တာအကြား ပူးပေါင်းဆောင်ရွက်ခြင်း၊ နှင့် BLADERUNNER- Synthetic (AI-Generated) StyleGAN မျက်နှာများအတွက် လျင်မြန်သော တန်ပြန်မှုMIT ၏ Lincoln ဓာတ်ခွဲခန်းရှိ Adam Dorian Wong မှ
၎င်း၏နည်းလမ်းအသစ်ကို မရှင်းပြမီ၊ နောက်ဆုံးစာတမ်းသည် ပုံတစ်ပုံကို GAN မှထုတ်လုပ်ထားခြင်းရှိ၊မရှိ (စာရွက်သည် NVIDIA ၏ StyleGAN မိသားစုနှင့် အထူးသက်ဆိုင်သည်) ကိုစစ်ဆေးရန် ယခင်နည်းလမ်းများကို အချိန်အနည်းငယ်ယူရသည်။
'Brady Bunch' နည်းလမ်း - ဖြစ်ကောင်းဖြစ်နိုင်သည်။ အဓိပ္ပါယ်မဲ့ကိုးကား 1970 ခုနှစ်များအတွင်း TV မကြည့်ဖူးသူ သို့မဟုတ် 1990 ခုနှစ်များအတွင်း လိုက်လျောညီထွေဖြစ်စေမည့် ရုပ်ရှင်များကို လွတ်သွားသူတိုင်းအတွက် - GAN မျက်နှာတစ်ခု၏ အစိတ်အပိုင်းအချို့သည် သေချာပေါက်နေရာယူထားသည့် ပုံသေအနေအထားများပေါ်အခြေခံ၍ GAN အတုပြုလုပ်ထားသော အကြောင်းအရာကို ခွဲခြားသတ်မှတ်သည်၊ 'ထုတ်လုပ်မှုလုပ်ငန်းစဉ်'။

2022 ခုနှစ်တွင် SANS အင်စတီကျုမှ ဝက်ဘ်ကာတ်မှ ပံ့ပိုးပေးသော 'Brady Bunch' နည်းလမ်း- GAN အခြေခံ မျက်နှာ ဂျင်နရေတာသည် ဓာတ်ပုံ၏ မူလအစကို အခြေပြု၍ အချို့သော ကိစ္စများတွင် ပုံ၏ မူလအစကို အခြေပြု၍ အချို့သော မျက်နှာအသွင်အပြင်များကို တူညီစွာ နေရာချထားပေးမည် ဖြစ်သည်။ အရင်းအမြစ်- https://arxiv.org/ftp/arxiv/papers/2210/2210.06587.pdf
နောက်ထပ် အသုံးဝင်သော ညွှန်ပြချက်မှာ လိုအပ်ပါက မျက်နှာများစွာကို ပုံဖေါ်ရန် StyleGAN ၏ မကြာခဏ မစွမ်းဆောင်နိုင်ခြင်း၊ ဆက်စပ်ပစ္စည်းများ ပေါင်းစပ်ညှိနှိုင်းခြင်းတွင် အရည်အချင်းမရှိခြင်း (အောက်ပုံအလယ်ပုံ) နှင့် လက်ငင်းစတင်မှုအဖြစ် ဆံပင်စည်းနည်းကို အသုံးပြုလိုစိတ်၊ ဦးထုပ် (အောက်ပါတတိယပုံ)။

သုတေသီ အာရုံစိုက်စေသော တတိယနည်းလမ်းမှာ ဓာတ်ပုံထပ်ပေးသည်။ (ဥပမာအားဖြင့် ကြည့်ရှုနိုင်ပါသည်။ ကျွန်ုပ်တို့၏သြဂုတ်လဆောင်းပါး CombineZ စီးရီးကဲ့သို့ ပေါင်းစပ်ဖွဲ့စည်းပုံ 'ရုပ်ပုံပေါင်းစပ်ခြင်း' ဆော့ဖ်ဝဲလ်ကို အသုံးပြုထားသည့် AI-အကူအညီဖြင့် ရောဂါရှာဖွေစစ်ဆေးခြင်း) သည် ရုပ်ပုံများစွာကို တစ်ပုံတည်းသို့ ပေါင်းစည်းရန်၊ မကြာခဏ ဖွဲ့စည်းတည်ဆောက်ပုံတွင် အရင်းခံတူညီမှုများကို ထုတ်ဖော်ပြသခြင်း - ပေါင်းစပ်မှု၏ ဖြစ်နိုင်ချေရှိသော ညွှန်ပြချက်ဖြစ်သည်။

စာတမ်းအသစ်တွင် အဆိုပြုထားသော ဗိသုကာလက်ရာသည် (SEO အကြံပြုချက်အားလုံးကို ဆန့်ကျင်နိုင်သည်) Blade ကို Runner, ကိုးကား Voight-Kampff စမ်းသပ်မှု သိပ္ပံဇာတ်လမ်းများတွင် ဆန့်ကျင်ဘက်သမားများသည် 'အတု' ဟုတ်မဟုတ် ဆုံးဖြတ်သည်။
ပိုက်လိုင်းတွင် အဆင့်နှစ်ဆင့်ဖြင့် ဖွဲ့စည်းထားပြီး ပထမအဆင့်မှာ PapersPlease ခွဲခြမ်းစိတ်ဖြာခြင်းဖြစ်ပြီး၊ thispersondoesnotexist.com သို့မဟုတ် generated.photos ကဲ့သို့သော နာမည်ကြီး GAN-မျက်နှာ ဝဘ်ဆိုက်များမှ ခြစ်ထုတ်ထားသော ဒေတာများကို အကဲဖြတ်နိုင်မည်ဖြစ်သည်။

GitHub တွင် ကုဒ်၏ဖြတ်တောက်မှုဗားရှင်းကို စစ်ဆေးနိုင်သော်လည်း OpenCV နှင့် OpenCV မှလွဲ၍ ဤ module နှင့်ပတ်သက်သောအသေးစိတ်အချက်အလတ်အနည်းငယ်ကို ဖော်ပြပေးထားပါသည်။ DLIB စုစည်းထားသော ပစ္စည်းရှိ မျက်နှာများကို အကြမ်းဖျင်းသိရှိရန် အသုံးပြုသည်။
ဒုတိယ module သည် ငါတို့ကြားမှာ detector ဤစနစ်သည် 'Brady Bunch' တွင် ဖော်ပြထားသည့် 'Brady Bunch' မြင်ကွင်းတွင် ပုံသွင်းထားသော StyleGAN ၏ အမြဲမပြတ်အင်္ဂါရပ်ဖြစ်သည့် ဓာတ်ပုံများတွင် ပေါင်းစပ်မျက်လုံးနေရာချထားမှုကို ရှာဖွေရန် ဒီဇိုင်းထုတ်ထားသည်။ AmongUs ကို စံ 68-မှတ်တိုင်ထောက်လှမ်းသည့်ကိရိယာဖြင့် ပါဝါပေးထားသည်။

Blade Runner ပက်ကေ့ဂျ်တွင် အသုံးပြုထားသော မျက်နှာအထင်ကရ ကွက်ကွက်ကုဒ်ကို Intelligent Behavior Understanding Group (IBUG) မှတစ်ဆင့် မျက်နှာအမှတ်အသား မှတ်ချက်များ။
ကျွန်ုပ်တို့သည် PapersPlease မှလူသိများသော 'Brady bunch' သြဒီနိတ်များအပေါ်အခြေခံ၍ ကြိုတင်လေ့ကျင့်ထားသော အထင်ကရနေရာများပေါ်တွင် မူတည်ပြီး StyleGAN အခြေခံ မျက်နှာပုံများ တိုက်ရိုက်ထုတ်လွှနမူနာများကို အသုံးပြုရန်အတွက် ရည်ရွယ်ပါသည်။
ရေးသားသူ Blade Runner သည် ဤနေရာတွင် ကိုင်တွယ်ဖြေရှင်းသည့် deepfake detection အမျိုးအစားအတွက် အိမ်တွင်းဖြေရှင်းချက်များအား ဖော်ထုတ်ရန် အရင်းအမြစ်များမရှိသော ကုမ္ပဏီ သို့မဟုတ် အဖွဲ့အစည်းများအတွက် ရည်ရွယ်သည့် plug-and-play ဖြေရှင်းချက်ဖြစ်ပြီး၊ 'အချိန်ကိုဝယ်ရန်အတွက် stop-gap အတိုင်းအတာတစ်ခုဖြစ်သည်။ နောက်ထပ် အမြဲတမ်း တန်ပြန်မှုတွေ၊
တကယ်တော့ လုံခြုံရေးကဏ္ဍမှာ မငြိမ်မသက်ဖြစ်ပြီး အရှိန်အဟုန်နဲ့ တိုးတက်နေတဲ့အတွက် စိတ်ကြိုက်ရွေးချယ်စရာတွေ အများကြီးမရှိပါဘူး။ or အရင်းအမြစ်နည်းသော ကုမ္ပဏီတစ်ခုသည် လက်ရှိတွင် ယုံကြည်စိတ်ချစွာ လှည့်နိုင်သော ဝန်ဆောင်မှုပေးသည့် cloud ရောင်းချသူ ဖြေရှင်းချက်ဖြစ်သည်။
Blade Runner သည် ခံစစ်ပိုင်း ညံ့ဖျင်းသော်လည်း၊ မျက်မှန်တပ်ထားသည်။ StyleGAN အတုလုပ်ထားသောသူများ၊ ဤကိစ္စများတွင် ဖုံးကွယ်ထားသော အကိုးအကားအချက်များအဖြစ် မျက်လုံးခွဲထွက်မှုများကို အကဲဖြတ်နိုင်ရန် မျှော်လင့်နေသော အလားတူစနစ်များတစ်လျှောက်တွင် ဤအရာသည် အတော်အတန်တွေ့ရလေ့ရှိသော ပြဿနာတစ်ခုဖြစ်သည်။
Blade Runner ဗားရှင်းကို လျှော့ချလိုက်ပါပြီ။ ဖြန့်ချိ GitHub တွင်အရင်းအမြစ်ဖွင့်ရန်။ open source repository ၏ လုပ်ဆောင်မှုတိုင်းတွင် ဓာတ်ပုံတစ်ပုံတည်းထက် ဓာတ်ပုံအများအပြားကို စီမံဆောင်ရွက်နိုင်သည့် စွမ်းဆောင်နိုင်မှုကြွယ်ဝသော မူပိုင်ဗားရှင်းတစ်ခု ရှိပါသည်။ စာရေးဆရာက အချိန်ရသလောက် GitHub ဗားရှင်းကို နောက်ဆုံးမှာ တူညီတဲ့စံနှုန်းအဖြစ် အဆင့်မြှင့်တင်ဖို့ ရည်ရွယ်ထားတယ်လို့ ဆိုပါတယ်။ StyleGAN သည် ၎င်း၏လူသိများသော သို့မဟုတ် လက်ရှိအားနည်းချက်များကိုကျော်လွန်၍ ဖွံ့ဖြိုးတိုးတက်လာဖွယ်ရှိကြောင်းကိုလည်း ၎င်းက ဝန်ခံခဲ့ပြီး ဆော့ဖ်ဝဲလ်သည် အလားတူဖွံ့ဖြိုးတိုးတက်ရန် လိုအပ်မည်ဖြစ်သည်။
DE-FAKE
DE-FAKE ဗိသုကာလက်ရာသည် စာသားမှပုံတစ်ပုံသို့ပျံ့နှံ့မှုပုံစံများမှထုတ်လုပ်သောရုပ်ပုံများအတွက် 'universal detection' ကိုရရှိစေရန်အတွက်သာမက ပိုင်းခြားသိမြင်နိုင်သောနည်းလမ်းကိုပေးစွမ်းရန် ရည်ရွယ်ပါသည်။ အရာ latent diffusion (LD) မော်ဒယ်ရုပ်ပုံကို ထုတ်လုပ်သည်။
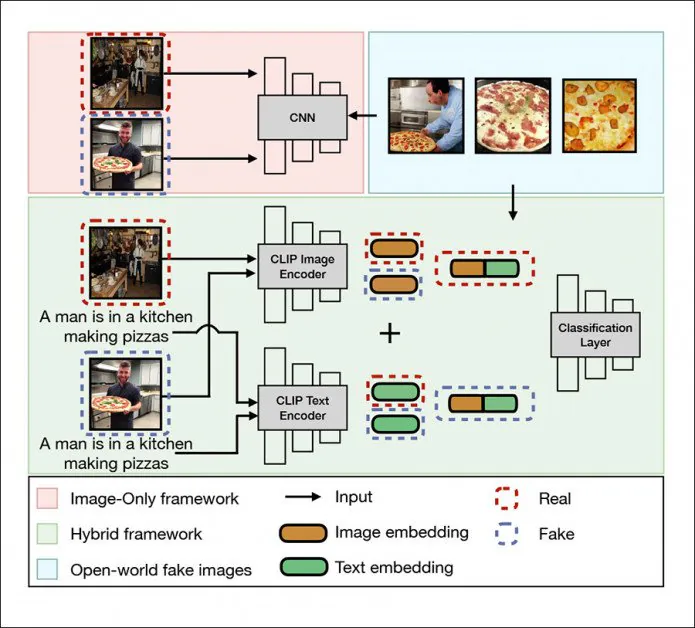
DE-FAKE ရှိ universal detection framework သည် ဒေသတွင်း ရုပ်ပုံများ၊ ပေါင်းစပ်ဘောင် (အစိမ်းရောင်) နှင့် open world ပုံများ (အပြာ) ကို လိပ်စာပေးသည်။ အရင်းအမြစ်- http://export.arxiv.org/pdf/2210.06998
ရိုးရိုးသားသားပြောရလျှင်၊ ယခုအချိန်တွင်၊ ဤသည်မှာ လူကြိုက်များသော LD မော်ဒယ်များ—အပိတ် သို့မဟုတ် အဖွင့်ရင်းမြစ်များ—တွင် ထင်ရှားသော ခြားနားသောဝိသေသလက္ခဏာများရှိသည်ဖြစ်သောကြောင့်၊ ဤသည်မှာ လွယ်ကူသောအလုပ်တစ်ခုဖြစ်သည်။
ထို့အပြင် အများစုမှာ ဦးခေါင်းဖြတ်ရန် စိတ်အားထက်သန်မှုကဲ့သို့သော ဘုံအားနည်းချက်အချို့ကို မျှဝေကြသည်။ မတရားနည်း စတုရန်းပုံမဟုတ်သော ဝဘ်-ခြစ်ရာပုံများကို DALL-E 2၊ Stable Diffusion နှင့် MidJourney ကဲ့သို့သော ပါဝါစနစ်များဖြစ်သည့် ကြီးမားသောဒေတာအတွဲများထဲသို့ ရောက်သွားသည်-

Latent diffusion မော်ဒယ်များသည် ကွန်ပျူတာ အမြင် မော်ဒယ်များအားလုံးနှင့် တူညီသော၊ စတုရန်းပုံစံ ထည့်သွင်းရန် လိုအပ်ပါသည်။ သို့သော် LAION5B ဒေတာအတွဲကို အားဖြည့်ပေးသည့် အစုလိုက်အပြုံလိုက် ဝက်ဘ်ခြစ်ခြင်းသည် မျက်နှာများ (သို့မဟုတ် အခြားအရာများကို မှတ်မိနိုင်စွမ်း) ကဲ့သို့သော 'ဇိမ်ခံအပိုပစ္စည်းများ' ကို မပေးဆောင်ဘဲ ၎င်းတို့ကို ဖုံးအုပ်ထားမည့်အစား ပုံများကို အလွန်ရက်စက်စွာ ဖြတ်တောက်ပေးသည် (အရင်းအမြစ်တစ်ခုလုံးကို ထိန်းသိမ်းထားမည့် ပုံ၊ သို့သော် resolution နိမ့်သည်။) လေ့ကျင့်သင်ကြားပြီးသည်နှင့် ဤ 'သီးနှံများ' သည် ပုံမှန်ဖြစ်လာပြီး Stable Diffusion ကဲ့သို့သော ငုပ်လျှိုးနေသော ပျံ့နှံ့မှုစနစ်၏ အထွက်တွင် မကြာခဏ ဖြစ်ပေါ်သည်။ အရင်းအမြစ်များ- https://blog.novelai.net/novelai-improvements-on-stable-diffusion-e10d38db82ac နှင့် Stable Diffusion။
DE-FAKE သည် algorithm-agnostic၊ autoencoder anti-deepfake သုတေသီများ၏ နှစ်ရှည်လများ မြတ်နိုးခဲ့သော ပန်းတိုင်ဖြစ်ပြီး LD စနစ်များနှင့် ပတ်သက်၍ ယခုအချိန်တွင် ရနိုင်သော အရာတစ်ခုဖြစ်သည်။
ဗိသုကာလက်ရာသည် OpenAI ၏ ဆန့်ကျင်ဘက်ဘာသာစကား-ရုပ်ပုံပြင်ဆင်ခြင်းကို အသုံးပြုသည် (ကလစ်) Multimodal စာကြည့်တိုက် – Stable Diffusion တွင် မရှိမဖြစ်လိုအပ်သော အစိတ်အပိုင်းတစ်ခုဖြစ်ပြီး ရုပ်ပုံ/ဗီဒီယိုပေါင်းစပ်မှုစနစ်များ၏ လှိုင်းသစ်၏ဗဟိုချက်ဖြစ်လာသည်- 'အတုလုပ်ထားသော' LD ပုံများမှ မြုပ်နှံမှုများကို ထုတ်ယူရန်နှင့် စောင့်ကြည့်လေ့လာထားသောပုံစံများနှင့် အတန်းများတွင် အမျိုးအစားခွဲနည်းတစ်ခုကို လေ့ကျင့်ပေးပါသည်။
မျိုးဆက်ဖြစ်စဉ်နှင့်ပတ်သက်သော အချက်အလက်များကို ကိုင်ဆောင်ထားသည့် PNG အတုံးများကို လုပ်ငန်းစဉ်များတင်ခြင်းနှင့် အခြားအကြောင်းရင်းများကြောင့် သုတေသီများက Salesforce ကို အသုံးပြုခြင်းဖြင့် နောက်ထပ် 'သေတ္တာနက်' ဇာတ်လမ်းတွင်၊ BLIP မူဘောင် (အစိတ်အပိုင်းတစ်ခုလည်းဖြစ်သည်။ အနည်းဆုံးတဦးတည်း Stable Diffusion ဖြန့်ချီခြင်း) သည် ၎င်းတို့ကို ဖန်တီးထားသော prompts များ၏ ဖြစ်နိုင်ခြေရှိသော semantic တည်ဆောက်ပုံအတွက် ပုံများကို 'မျက်စိစုံမှိတ်' စစ်တမ်းကောက်ယူရန်။

သုတေသီများသည် MSCOCO နှင့် Flickr2k တို့ကို အသုံးချ၍ လေ့ကျင့်ခြင်းနှင့် စမ်းသပ်ခြင်းဒေတာအစုံကို ဖြည့်သွင်းရန်အတွက် Stable Diffusion၊ Latent Diffusion (၎င်းသည် သီးခြားထုတ်ကုန်တစ်ခု)၊ GLIDE နှင့် DALL-E 30 ကို အသုံးပြုခဲ့သည်။
ပုံမှန်အားဖြင့် ကျွန်ုပ်တို့သည် မူဘောင်အသစ်တစ်ခုအတွက် သုတေသီများ၏ စမ်းသပ်မှုများ၏ ရလဒ်များကို ကျယ်ကျယ်ပြန့်ပြန့် ကြည့်ရှုလေ့ရှိသည်။ သို့သော် အမှန်မှာ၊ DE-FAKE ၏ရှာဖွေတွေ့ရှိချက်များသည် နောက်ပိုင်းတွင် ထပ်ခါထပ်ခါပြုလုပ်မှုများနှင့် အလားတူပရောဂျက်များအတွက် အနာဂတ်စံညွှန်းတစ်ခုအဖြစ် ပိုမိုအသုံးဝင်ပုံရသည်၊ ပရောဂျက်အောင်မြင်မှု၏ အဓိပ္ပါယ်ရှိသော မက်ထရစ်တစ်ခုအဖြစ်၊ ၎င်းတွင်လည်ပတ်နေသော မငြိမ်မသက်သောပတ်ဝန်းကျင်နှင့် ၎င်းစနစ်အား ထည့်သွင်းစဉ်းစားခြင်းထက် ပိုမိုအသုံးဝင်ပုံရသည်။ စက္ကူ၏စမ်းသပ်မှုများတွင်ယှဉ်ပြိုင်နေသည်မှာသုံးနှစ်နီးပါးရှိပြီ - ရုပ်ပုံပေါင်းစပ်မှုမြင်ကွင်းသည်အမှန်တကယ်အခြေတည်နေချိန်တွင်နောက်ကျောမှဖြစ်သည်။

ဘယ်ဘက်အကျဆုံး ရုပ်ပုံနှစ်ပုံ- 2019 ခုနှစ်တွင် အစပြုခဲ့သော 'စိန်ခေါ်ထားသော' မတိုင်မီ မူဘောင်သည် DE-FAKE (ညာဘက်ဆုံးပုံနှစ်ပုံ) ကို စမ်းသပ်ထားသည့် LD စနစ်လေးခုတွင် DE-FAKE (ညာဘက်ဆုံးပုံနှစ်ပုံ) နှင့် ယှဉ်ရန် အလားအလာနည်းသည်။
အဖွဲ့၏ရလဒ်များသည် အကြောင်းပြချက်နှစ်ခုအတွက် အလွန်အမင်းအပြုသဘောဆောင်နေပါသည်- ၎င်းကို နှိုင်းယှဉ်ရန် ကြိုတင်လုပ်ဆောင်ရန် နည်းပါးနေသေးသည် (၎င်းကို မျှတသောနှိုင်းယှဉ်မှုတစ်ခုမျှ မပေးဆောင်ပါနှင့်၊ ဆိုလိုသည်မှာ Stable Diffusion ကို open source မှ ထွက်ရှိပြီးသည့်အချိန်မှစ၍ ဆယ်နှစ်ပတ်မျှသာ အကျုံးဝင်သော မျှတသောနှိုင်းယှဉ်မှုကို မပေးဆောင်နိုင်)။
ဒုတိယအနေနှင့်၊ အထက်တွင်ဖော်ပြခဲ့သည့်အတိုင်း LD ရုပ်ပုံပေါင်းစပ်မှုနယ်ပယ်သည် ကိန်းဂဏန်းအမြန်နှုန်းဖြင့် တိုးတက်နေသော်လည်း၊ လက်ရှိကမ်းလှမ်းချက်များ၏ထွက်ရှိမှုအကြောင်းအရာသည် ၎င်း၏ကိုယ်ပိုင်ဖွဲ့စည်းပုံဆိုင်ရာ (နှင့်အလွန်ခန့်မှန်းနိုင်သော) ချို့ယွင်းချက်များနှင့် ဆန်းသစ်တီထွင်မှုများအား ဖျောက်ဖျက်ခြင်းဖြင့် ၎င်း၏အထွက်တွင် ရေစာအမှတ်ကို ထိရောက်စွာပြုလုပ်ပေးပါသည်။ Stable Diffusion တွင် အနည်းဆုံး စွမ်းဆောင်ရည်ပိုကောင်းသော 1.5 စစ်ဆေးရေးဂိတ် (ဆိုလိုသည်မှာ စနစ်အား ပါဝါပေးသည့် 4GB လေ့ကျင့်ထားသော မော်ဒယ်) ကို ထုတ်ပြန်ခြင်းဖြင့် အနည်းဆုံးဖြစ်သည်။
တစ်ချိန်တည်းမှာပင်၊ Stability သည် စနစ်၏ V2 နှင့် V3 အတွက် ရှင်းလင်းသော လမ်းပြမြေပုံရှိကြောင်း ညွှန်ပြထားပြီးဖြစ်သည်။ ပြီးခဲ့သည့်သုံးလ၏ ခေါင်းစဉ်တပ်ထားသော အဖြစ်အပျက်များကြောင့် OpenAI ၏ ကော်ပိုရိတ်နှင့် အခြားပြိုင်ဖက်များဖြစ်သော ရုပ်ပုံပေါင်းစပ်မှုနေရာရှိ ကော်ပိုရိတ်ထိနမိခြင်းများသည် အငွေ့ပျံသွားဖွယ်ရှိသည်၊ ဆိုလိုသည်မှာ ကျွန်ုပ်တို့သည် အလားတူ လျင်မြန်သောတိုးတက်မှုအရှိန်အဟုန်ကို မျှော်လင့်နိုင်သည်။ အပိတ်-ရင်းမြစ် ရုပ်ပုံပေါင်းစပ်မှု နေရာ။
၂၀၂၂ ခုနှစ် အောက်တိုဘာလ ၅ ရက်နေ့တွင် ပထမအကြိမ် ထုတ်ဝေခဲ့သည်။















