
Ийн хамгийн шилдэг
Машин сурах шилдэг 10 алгоритм
Хэдийгээр бид GPU хурдасгасан машин сургалтын ер бусын инновацийн цаг үеийг туулж байгаа ч хамгийн сүүлийн үеийн судалгааны баримт бичгүүдэд олон арван жил, зарим тохиолдолд 70 жилийн настай алгоритмуудыг онцолсон байдаг.
Зарим хүмүүс эдгээр хуучин аргуудын ихэнх нь машин сурах гэхээсээ илүүтэй "статистикийн дүн шинжилгээ"-ний хуаранд багтдаг гэж маргаж болох бөгөөд энэ салбар бий болсон үеэс зөвхөн 1957 оныг хүртэл онцлохыг илүүд үздэг. Perceptron-ийн шинэ бүтээл.
Эдгээр хуучин алгоритмууд нь машин сургалтын сүүлийн үеийн чиг хандлага, гарчигтай хөгжилд хэр зэрэг дэмжлэг үзүүлж, шингээж байгааг харгалзан үзвэл энэ нь маргаантай байр суурь юм. Тиймээс хамгийн сүүлийн үеийн инновацийн үндэс болсон зарим "сонгодог" барилгын блокуудыг, мөн хиймэл оюун ухааны алдрын танхимд эртхэн санал тавьж буй шинэ бүтээлүүдийг харцгаая.
1: Трансформаторууд
2017 онд Google Research нь судалгааны хамтын ажиллагааг удирдан явуулсан цаасан Анхаарал л танд хэрэгтэй. Энэхүү бүтээлд сурталчилсан шинэ архитектурыг тодорхойлсон анхаарлын механизмууд кодлогч/декодер болон давтагдах сүлжээний загварууд дахь "хоолой"-оос эхлээд бие даасан төвийн хувиргах технологи хүртэл.
Арга барилыг нэрлэсэн Transformer, ба түүнээс хойш Байгалийн хэл боловсруулах (NLP)-д хувьсгалт арга зүй болж, бусад олон жишээнүүдийн дунд авторегрессив хэлний загвар болон AI зурагт хуудас-хүүхдийн GPT-3-ийг хүчирхэгжүүлсэн.
![]()
Трансформаторууд асуудлыг гоёмсог байдлаар шийдсэн дарааллын дамжуулалт, мөн "хувиргах" гэж нэрлэдэг бөгөөд энэ нь оролтын дарааллыг гаралтын дараалал болгон боловсруулахад зориулагдсан. Трансформатор нь өгөгдлийг дараалсан багцаар бус тасралтгүй хүлээн авч, удирддаг бөгөөд энэ нь RNN архитектурын олж авахаар төлөвлөөгүй "санах ойн тогтвортой байдлыг" олгодог. Трансформаторын талаар илүү нарийвчилсан тоймыг харна уу бидний лавлах нийтлэл.
CUDA-ийн эрин үед ML судалгаанд ноёрхож эхэлсэн давтагдах мэдрэлийн сүлжээнээс (RNN) ялгаатай нь Трансформаторын архитектур нь бас амархан байж болох юм. зэрэгцүүлсэн, RNN-ээс хамаагүй том хэмжээний өгөгдлийн цогцыг үр бүтээлтэй шийдвэрлэх арга замыг нээж байна.
Түгээмэл хэрэглээ
Transformers нь 2020 онд OpenAI-ийн GPT-3-ыг гаргаснаар олон нийтийн анхаарлыг татсан бөгөөд энэ нь тухайн үеийн дээд амжилтыг эвдсэн юм. 175 тэрбум параметр. Энэхүү гайхалтай амжилт нь 2021 он гэх мэт хожмын төслүүдийн сүүдэрт дарагджээ. Хувилбар Майкрософт компанийн Megatron-Turing NLG 530B төхөөрөмж (нэрээр нь) 530 тэрбум гаруй параметртэй.

Хэт масштабтай Transformer NLP төслүүдийн цагийн хуваарь. Эх сурвалж: Microsoft-
Трансформаторын архитектур нь NLP-ээс компьютерийн хараа руу шилжиж, a шинэ үе OpenAI гэх мэт зургийн синтезийн хүрээний КЛИП болон SLAB, өсөн нэмэгдэж буй холбогдох програмуудын дунд дутуу зургуудыг дуусгах, сургагдсан домайнуудаас шинэ зургуудыг нэгтгэхийн тулд текст>зургийн домайн зураглалыг ашигладаг.

DALL-E нь Платоны цээж баримлын хэсэгчилсэн зургийг дуусгахыг оролддог. Эх сурвалж: https://openai.com/blog/dall-e/
2: Өрсөлдөөнт сүлжээ (GANs)
Хэдийгээр трансформаторууд GPT-3-ыг гаргаж, нэвтрүүлснээр хэвлэл мэдээллийн хэрэгслээр ер бусын мэдээлэл олж авсан ч Гүйцэтгэх дайсны сүлжээ (GAN) нь өөрөө танигдахуйц брэнд болсон бөгөөд эцэст нь нэгдэж магадгүй юм гүнзгийрч байна үйл үг болгон.
Анх санал болгосон 2014 нь болон үндсэндээ зураг нэгтгэхэд ашигладаг, Generative Adversarial Network архитектур бүрдэнэ Генератор болон Ялгаварлагч. Генератор нь өгөгдлийн багц дахь мянга мянган зургийг эргэлдэж, тэдгээрийг дахин бүтээхийг оролддог. Ялгагч нь оролдлого бүрийн хувьд генераторын ажлыг үнэлж, илүү сайн болгохын тулд генераторыг буцааж илгээдэг боловч өмнөх сэргээн босголтод алдаа гаргасан талаар ямар ч ойлголтгүй байдаг.

Эх сурвалж: https://developers.google.com/machine-learning/gan/gan_structure
Энэ нь генераторыг хэрвээ хаана нь буруу болж байгааг хэлсэн бол үүгээрээ гарч болзошгүй сохор гудамжуудыг дагахын оронд олон янзын замыг судлахад хүргэдэг (доорх №8-ыг үзнэ үү). Сургалт дуусах үед генератор өгөгдлийн багц дахь цэгүүдийн хоорондын харилцааны нарийвчилсан, иж бүрэн зураглалтай болно.

Цааснаас Орон зайн мэдлэгийг дээшлүүлэх замаар GAN тэнцвэрийг сайжруулах: шинэ хүрээ нь GAN-ийн заримдаа нууцлагдмал далд орон зайг тойрон эргэлдэж, зургийн синтезийн архитектурт хариу үйлдэл үзүүлэх хэрэгслийг өгдөг. Эх сурвалж: https://genforce.github.io/eqgan/
Үүнтэй адилтгаж үзвэл энэ нь Лондонгийн төв рүү явахдаа ганц удаа явах эсвэл шаргуу сурах хоёрын ялгаа юм. Мэдлэг.
Үр дүн нь бэлтгэгдсэн загварын далд орон зайд өндөр түвшний шинж чанаруудын цуглуулга юм. Өндөр түвшний шинж чанарын утгын үзүүлэлт нь 'хүн' байж болох ч онцлогтой холбоотой өвөрмөц шинж чанараар дамжин удамших нь 'эрэгтэй', 'эмэгтэй' зэрэг бусад сурсан шинж чанаруудыг илрүүлж болно. Доод түвшинд дэд шинж чанарууд нь "шаргал", "Кавказ" гэх мэтээр задардаг.
орооцолдох нь анхаарал татахуйц асуудал GAN болон кодлогч/декодерийн хүрээнүүдийн далд орон зайд: GAN-ээр үүсгэгдсэн эмэгтэйн нүүрэн дээрх инээмсэглэл нь түүний далд орон зай дахь "таних байдлын" орооцолдсон шинж чанар уу, эсвэл энэ нь зэрэгцээ салбар уу?

Энэ хүний GAN-аар үүсгэсэн царай байхгүй. Эх сурвалж: https://this-person-does-not-exist.com/en
Сүүлийн хоёр жил энэ чиглэлээр өсөн нэмэгдэж буй судалгааны шинэ санаачлагуудыг гаргаж ирсэн нь магадгүй GAN-ийн далд орон зайд онцлох түвшний, фотошоп маягийн засварлах замыг тавьсан ч одоогоор олон өөрчлөлтүүд үр дүнтэй байна. Бүгд эсвэл юу ч биш' багц. NVIDIA-ийн 2021 оны сүүлчээр гаргасан EditGAN хувилбар нь тайлбарлах чадварын өндөр түвшин далд орон зайд семантик сегментчлэлийн маск ашиглан.
Түгээмэл хэрэглээ
Алдартай гүнзгий хуурамч видеонуудад (үнэндээ нэлээд хязгаарлагдмал) оролцохоос гадна зураг/видео төвтэй GAN-ууд сүүлийн дөрвөн жилийн хугацаанд олширч, судлаачид болон олон нийтийн анхаарлыг татсан. Хэдийгээр GitHub репозитор нь шинэ хувилбаруудын толгой эргэм хурд, давтамжийг дагаж мөрдөх нь хэцүү байдаг. Гайхалтай GAN програмууд иж бүрэн жагсаалтыг гаргах зорилготой.
Генератив өрсөлдөгчийн сүлжээ нь онолын хувьд ямар ч сайн хүрээтэй домэйноос шинж чанаруудыг гаргаж авах боломжтой. текстийг оруулаад.
3: SVM
Гарал үүсэл 1963 нь, Вектор машиныг дэмжих (SVM) нь шинэ судалгаанд байнга гарч ирдэг үндсэн алгоритм юм. SVM-ийн дагуу векторууд нь өгөгдлийн багц дахь өгөгдлийн цэгүүдийн харьцангуй байрлалыг зураглаж байхад тусламж векторууд нь янз бүрийн бүлэг, онцлог, шинж чанаруудын хоорондох хил хязгаарыг тодорхойлдог.
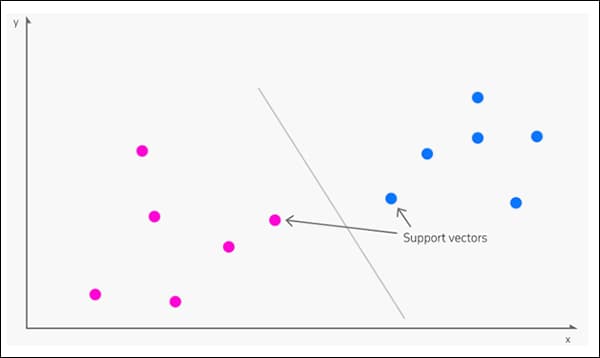
Туслах векторууд нь бүлгүүдийн хоорондын хил хязгаарыг тодорхойлдог. Эх сурвалж: https://www.kdnuggets.com/2016/07/support-vector-machines-simple-explanation.html
Үүсмэл хил хязгаарыг a гэж нэрлэдэг гиперплан.
Бага функцийн түвшинд SVM нь хоёр хэмжээст (дээрх зураг), гэхдээ хүлээн зөвшөөрөгдсөн бүлэг эсвэл төрлүүдийн тоо их байвал энэ нь болдог гурван хэмжээст.

Илүү гүнзгийрүүлсэн цэгүүд болон бүлгүүд нь гурван хэмжээст SVM-ийг шаарддаг. Эх сурвалж: https://cml.rhul.ac.uk/svm.html
Түгээмэл хэрэглээ
Вектор машинуудын дэмжлэг нь олон төрлийн өндөр хэмжээст өгөгдлийг үр дүнтэй, үл тоомсорлож чаддаг тул тэдгээр нь машин сургалтын төрөл бүрийн салбарт өргөн тархдаг. гүн хуурамч илрүүлэлт, зургийн ангилал, үзэн ядсан ярианы ангилал, ДНХ-ийн шинжилгээ болон хүн амын бүтцийн таамаглал, бусад олон хүмүүсийн дунд.
4: К-бүлэглэх гэсэн үг
Кластер нь ерөнхийдөө а хяналтгүй суралцах дамжуулан өгөгдлийн цэгүүдийг ангилахыг эрмэлздэг арга нягтын тооцоо, судалж буй өгөгдлийн тархалтын газрын зургийг гаргах.

K-Өгөгдөл дэх тэнгэрлэг сегмент, бүлэг, нийгэмлэгүүдийг бөөгнөрүүлэх гэсэн үг. Эх сурвалж: https://aws.amazon.com/blogs/machine-learning/k-means-clustering-with-amazon-sagemaker/
K-бүлэглэх гэсэн үг нь хүн ам зүйн салбарууд, онлайн нийгэмлэгүүд эсвэл түүхий статистик мэдээллээс илрэхийг хүлээж буй бусад нууц нэгтгэлийг илтгэж болох өвөрмөц "K бүлэг" болгон мэдээллийн цэгүүдийг нэгтгэсэн энэхүү аргын хамгийн түгээмэл хэрэглүүр болсон.

K-Means шинжилгээнд кластерууд үүсдэг. Эх сурвалж: https://www.geeksforgeeks.org/ml-determine-the-optimal-value-of-k-in-k-means-clustering/
K утга нь өөрөө процессын ашиг тус, кластерын оновчтой утгыг тогтооход тодорхойлогч хүчин зүйл болдог. Эхлээд K утгыг санамсаргүй байдлаар хуваарилж, түүний онцлог, вектор шинж чанарыг хөршүүдтэйгээ харьцуулдаг. Өгөгдлийн цэгтэй санамсаргүй байдлаар томилогдсон утгыг хамгийн их санагдуулдаг хөршүүд нь процессын зөвшөөрөгдсөн бүх бүлэглэлийг гаргаж ирэх хүртэл түүний кластерт давтагдах байдлаар хуваарилагдана.
Квадрат алдааны график буюу кластеруудын өөр өөр утгуудын "зардал" нь тохойн цэг өгөгдлийн хувьд:

Кластер график дахь "тохойн цэг". Эх сурвалж: https://www.scikit-yb.org/en/latest/api/cluster/elbow.html
Тохойн цэг нь өгөгдлийн багцын сургалтын төгсгөлд алдагдлыг хавтгайруулж, өгөөжөө бууруулдагтай төстэй. Энэ нь бүлгүүдийн хооронд цаашид ямар ч ялгаа харагдахгүй байх үеийг илэрхийлдэг бөгөөд энэ нь өгөгдлийн шугамын дараагийн үе шат руу шилжих эсвэл үр дүнг тайлагнах мөчийг харуулж байна.
Түгээмэл хэрэглээ
K-Means Clustering нь тодорхой шалтгааны улмаас олон тооны арилжааны бүртгэлийг хүн ам зүйн ойлголт, "тэргүүлэх" болгон хөрвүүлэх тодорхой бөгөөд тайлбарлах аргачлалыг санал болгодог тул хэрэглэгчийн шинжилгээний үндсэн технологи юм.
Энэ програмаас гадна K-Means Clustering нь бас ашиглагддаг хөрсний гулсалтын таамаглал, эмнэлгийн зургийн сегментчилэл, GAN-уудтай зургийн синтез, баримт бичгийн ангилалБолон хот төлөвлөлт, бусад олон боломжит болон бодит хэрэглээний дунд.
5: Санамсаргүй ой
Санамсаргүй ой нь чуулга сурах массиваас үр дүнг дундажлах арга шийдвэрийн мод үр дүнгийн ерөнхий таамаглалыг бий болгох.

Эх сурвалж: https://www.tutorialandexample.com/wp-content/uploads/2019/10/Decision-Trees-Root-Node.png
Хэрэв та үүнийг үзэх шигээ бага ч гэсэн судалсан бол Ирээдүй рүү буцах Шийдвэрийн мод нь өөрөө ойлгоход маш хялбар байдаг: таны өмнө хэд хэдэн зам байх бөгөөд зам бүр нь шинэ үр дүнд хүрч, улмаар цаашдын боломжит замыг агуулна.
In бэхжүүлэх сургалт, та замаасаа ухарч, өмнөх байр сууринаасаа дахин эхэлж болно, харин шийдвэрийн моднууд аяндаа тууштай ажиллах болно.
Иймээс Random Forest алгоритм нь үндсэндээ шийдвэр гаргахад зориулагдсан бооцоо юм. Алгоритмыг хийдэг учраас "санамсаргүй" гэж нэрлэдэг Ad hoc ойлгохын тулд сонголт, ажиглалт дундаж шийдвэрийн модны массивын үр дүнгийн нийлбэр.
Энэ нь олон хүчин зүйлийг харгалзан үздэг тул санамсаргүй ойн арга нь шийдвэрийн модыг бодвол утга учиртай график болгон хувиргахад илүү хэцүү боловч илүү бүтээмжтэй байх магадлалтай.
Шийдвэрийн модыг хэт тохируулдаг бөгөөд олж авсан үр дүн нь өгөгдлийн онцлогтой бөгөөд ерөнхийлөн дүгнэх боломжгүй байдаг. Санамсаргүй ой санамсаргүй байдлаар өгөгдлийн цэгүүдийг сонгосон нь энэ хандлагатай тэмцэж, өгөгдөл дэх утга учиртай, ашигтай төлөөлөгчийн чиг хандлагыг өрөмдөж байна.

Шийдвэрийн модны регресс. Эх сурвалж: https://scikit-learn.org/stable/auto_examples/tree/plot_tree_regression.html
Түгээмэл хэрэглээ
Энэ жагсаалтад багтсан олон алгоритмуудын нэгэн адил Random Forest нь ихэвчлэн мэдээллийн "эрт" ангилагч, шүүлтүүрийн үүрэг гүйцэтгэдэг бөгөөд шинэ судалгааны баримт бичгүүдэд байнга гарч ирдэг. Санамсаргүй ойн хэрэглээний зарим жишээг дурдвал Соронзон резонансын зургийн синтез, Bitcoin үнийн таамаглал, тооллогын сегментчилэл, текстийн ангилал болон зээлийн картын залилан илрүүлэх.
Random Forest нь машин сургалтын архитектурын доод түвшний алгоритм тул бусад доод түвшний аргууд, түүнчлэн дүрслэх алгоритмуудыг хэрэгжүүлэхэд хувь нэмэр оруулах боломжтой. Индуктив бөөгнөрөл, Онцлогийн өөрчлөлтүүд, текст баримт бичгийн ангилал сийрэг функцуудыг ашиглахБолон Дамжуулах шугамуудыг харуулж байна.
6: Гэнэн Бэйс
Нягтын тооцоололтой хослуулсан (харна уу 4, дээрх), a гэнэн Бэйс Ангилагч нь өгөгдлийн тооцоолсон шинж чанарт үндэслэн магадлалыг тооцоолох чадвартай хүчирхэг боловч харьцангуй хөнгөн алгоритм юм.

Гэнэн Bayes ангилагч дахь онцлог харилцаа. Эх сурвалж: https://www.sciencedirect.com/topics/computer-science/naive-bayes-model
"Гэнэн" гэсэн нэр томъёо нь дээрх таамаглалыг илэрхийлдэг Бэйсийн теорем шинж чанарууд нь хоорондоо хамааралгүй гэж нэрлэгддэг нөхцөлт бие даасан байдал. Хэрэв та энэ байр суурийг баримталбал нугас шиг алхаж, ярих нь биднийг нугастай харьцаж байгааг батлахад хангалттай биш бөгөөд ямар ч "илэрхий" таамаглалыг эрт хүлээн зөвшөөрөхгүй.
Эрдэм шинжилгээний болон мөрдөн байцаалтын нарийн нягт нямбай байдал нь "эрүүл саруул ухаан" байгаа тохиолдолд хэт их байх боловч машин сургалтын өгөгдлийн багцад байж болох олон ойлгомжгүй байдал, хамааралгүй хамаарлыг даван туулахад үнэ цэнэтэй стандарт юм.
Анхны Bayesian сүлжээнд онцлог шинж чанарууд хамаарна онооны функцууд, үүнд хамгийн бага тайлбар урт ба Bayesian оноо, өгөгдлийн цэгүүдийн хооронд олдсон тооцоолсон холболтууд болон эдгээр холболтуудын урсгалын чиглэлийн хувьд өгөгдөлд хязгаарлалт тавьж болно.
Гэнэн Бэйсийн ангилагч нь эсрэгээрээ тухайн объектын шинж чанарууд нь бие даасан гэж үзээд дараа нь Байесийн теоремыг ашиглан тухайн объектын магадлалыг түүний шинж чанарт үндэслэн тооцдог.
Түгээмэл хэрэглээ
Naive Bayes шүүлтүүрүүд нь маш сайн төлөөлөлтэй байдаг өвчний таамаглал, баримт бичгийн ангилал, спам шүүлтүүр, мэдрэмжийн ангилал, зөвлөмжийн системүүдБолон залилангийн илрүүлэг, бусад програмуудын дунд.
7: K- Хамгийн ойрын хөршүүд (KNN)
Анх АНУ-ын Агаарын цэргийн хүчний нисэхийн анагаах ухааны сургуулиас санал болгосон 1951 нь, мөн 20-р зууны дунд үеийн хамгийн сүүлийн үеийн компьютерийн техник хангамжид нийцсэн байх ёстой. K-хамгийн ойрын хөршүүд (KNN) нь эрдэм шинжилгээний бичиг баримтууд болон хувийн хэвшлийн машин сургалтын судалгааны санаачилгууд дээр алдартай хэвээр байгаа туранхай алгоритм юм.
KNN-ийг "залхуу суралцагч" гэж нэрлэдэг, учир нь энэ нь өгөгдлийн цэгүүдийн хоорондын хамаарлыг үнэлэхийн тулд өгөгдлийн багцыг бүрэн сканнердаж, машин сургалтын бүрэн загварыг сургах шаардлагагүй юм.

KNN бүлэглэл. Эх сурвалж: https://scikit-learn.org/stable/modules/neighbors.html
KNN нь архитектурын хувьд нарийхан боловч түүний системчилсэн арга нь унших/бичих үйлдлүүдэд ихээхэн эрэлт хэрэгцээтэй байдаг бөгөөд түүнийг маш том өгөгдлийн багцад ашиглах нь нарийн төвөгтэй, их хэмжээний өгөгдлийн багцыг хувиргах үндсэн бүрэлдэхүүн хэсгүүдийн шинжилгээ (PCA) зэрэг нэмэлт технологигүйгээр асуудал үүсгэдэг. руу төлөөллийн бүлгүүд KNN бага хүчин чармайлтаар туулж чадна.
A сүүлийн үеийн судалгаа Ажилтан нь компанийг орхих эсэхийг урьдчилан таамаглах хэд хэдэн алгоритмын үр ашиг, хэмнэлтийг үнэлж, septuagenarian KNN нь үнэн зөв, урьдчилан таамаглах үр дүнтэй байдлын хувьд орчин үеийн өрсөлдөгчдөөс давуу хэвээр байгааг олж мэдэв.
Түгээмэл хэрэглээ
Үзэл баримтлал, гүйцэтгэлийн бүх алдартай энгийн байдлаас үл хамааран KNN 1950-иад онд гацсангүй - үүнийг дасан зохицсон. илүү DNN төвлөрсөн арга 2018 онд Пенсильвани мужийн их сургуулиас гаргасан саналд багтсан бөгөөд илүү нарийн төвөгтэй машин сургалтын тогтолцооны эхний шатны төв процесс (эсвэл боловсруулалтын дараах аналитик хэрэгсэл) хэвээр байна.
Төрөл бүрийн тохиргоонд KNN-г ашигласан онлайн гарын үсгийн баталгаажуулалт, зургийн ангилал, текст олборлолт, ургацын таамаглалБолон нүүрний хүлээн зөвшөөрөх, бусад програмууд болон нэгдлүүдээс гадна.

Сургалтанд KNN-д суурилсан царай таних систем. Source: https://pdfs.semanticscholar.org/6f3d/d4c5ffeb3ce74bf57342861686944490f513.pdf
8: Марковын шийдвэр гаргах үйл явц (MDP)
Америкийн математикч Ричард Беллманы танилцуулсан математикийн хүрээ 1957 нь, Марковын шийдвэр гаргах үйл явц (MDP) нь хамгийн үндсэн блокуудын нэг юм бэхжүүлэх сургалт архитектурууд. Энэ нь бие даасан үзэл баримтлалын алгоритм бөгөөд бусад олон тооны алгоритмуудад дасан зохицсон бөгөөд одоогийн AI/ML судалгааны үр дүнд байнга давтагддаг.
MDP нь өгөгдлийн орчинг судалж, одоогийн төлөв байдлынхаа үнэлгээг (өөрөөр хэлбэл өгөгдлийн хаана байгааг) ашиглан дараа нь өгөгдлийн аль зангилааг судлахаа шийддэг.

Эх сурвалж: https://www.sciencedirect.com/science/article/abs/pii/S0888613X18304420
Марковын үндсэн шийдвэр гаргах үйл явц нь илүү урт хугацааны зорилгоос илүү ойрын хугацааны давуу талыг чухалчлах болно. Энэ шалтгааны улмаас энэ нь ихэвчлэн бататгах сургалтын илүү цогц бодлогын архитектурын контекстэд багтдаг бөгөөд ихэвчлэн хязгаарлагдмал хүчин зүйлүүд байдаг. хөнгөлөлттэй урамшуулал, болон бусад өөрчлөх хүрээлэн буй орчны хувьсагчууд нь илүү өргөн хүрээтэй хүссэн үр дүнг тооцохгүйгээр шууд зорилгодоо хүрэхээс сэргийлнэ.
Түгээмэл хэрэглээ
MDP-ийн доод түвшний үзэл баримтлал нь судалгаа болон машин сургалтын идэвхтэй хэрэглээнд өргөн тархсан. Үүнийг санал болгосон IoT аюулгүй байдлын хамгаалалтын систем, загас хураахБолон зах зээлийн таамаглал.
Түүнээс гадна хэрэглэх нь илт Шатар болон бусад хатуу дараалсан тоглоомуудын хувьд MDP нь мөн төрөлхийн өрсөлдөгч юм роботын системийн процедурын сургалт, бид доорх видеоноос харж болно.

9: Нэр томъёоны давтамж-урвуу баримт бичгийн давтамж
Хугацааны давтамж (TF) баримт бичигт үг гарч ирэх тоог тухайн баримт бичигт байгаа нийт үгийн тоонд хуваана. Тиймээс үг тамга мянган үгтэй нийтлэлд нэг удаа гарах нь нэр томъёоны давтамж 0.001 байна. TF нь өөрөө утга учиргүй нийтлэл (жишээ нь) байдаг тул нэр томьёоны ач холбогдлын үзүүлэлтийн хувьд огт хэрэггүй юм. a, болон, олон тооБолон it) давамгайлах.
Нэр томъёоны утга учиртай утгыг олж авахын тулд урвуу баримт бичгийн давтамж (IDF) нь өгөгдлийн багц дахь олон баримт бичигт үгийн TF-ийг тооцоолж, бага үнэлгээг маш өндөр давтамжтай болгодог. зогсоох үгснийтлэл гэх мэт. Үүссэн онцлог векторуудыг бүхэл утгаараа хэвийн болгож, үг бүрд тохирох жинг онооно.

TF-IDF нь нэр томъёоны хамаарлыг хэд хэдэн баримт бичгийн давтамж дээр үндэслэн үнэлдэг бөгөөд ховор тохиолдлууд нь анхаарал татахуйц байдлын үзүүлэлт юм. Эх сурвалж: https://moz.com/blog/inverse-document-frequency-and-the-importance-of-uniqueness
Хэдийгээр энэ арга нь утгын хувьд чухал үгсийг алдахаас сэргийлдэг борлуулагч, давтамжийн жинг эргүүлэх нь автоматаар бага давтамжийн нэр томъёо гэсэн үг биш юм үгүй биш зарим зүйл ховор байдаг тул хэт давсан үзүүлэлт болон үнэ цэнэгүй. Тиймээс бага давтамжийн нэр томъёо нь өгөгдлийн багц дахь хэд хэдэн баримт бичигт (баримт бичиг бүрт бага давтамжтай байсан ч гэсэн) тусгаснаар архитектурын өргөн хүрээнд өөрийн үнэ цэнийг батлах шаардлагатай болно.
Гэсэн хэдий ч нас, TF-IDF нь Natural Language Processing фреймворкууд дахь дамжуулалтыг анхан шатны шүүхээр хийх хүчирхэг бөгөөд түгээмэл арга юм.
Түгээмэл хэрэглээ
TF-IDF нь сүүлийн хорин жилийн хугацаанд Google-ийн далдлагдсан PageRank алгоритмыг хөгжүүлэхэд дор хаяж тодорхой үүрэг гүйцэтгэсэн учраас энэ нь маш өргөнөөр хүлээн зөвшөөрсөн Жон Мюллерийн 2019 оныг үл харгалзан манипуляцийн SEO тактикийн хувьд үгүйсгэх хайлтын үр дүнд чухал ач холбогдолтой.
PageRank-ийн эргэн тойронд нууцлагдмал байдлаас болж TF-IDF-ийн талаар тодорхой нотолгоо байхгүй байна үгүй биш одоогоор Google-ийн зэрэглэлд өсөх үр дүнтэй тактик. Шатаагч хэлэлцүүлэг Сүүлийн үед мэдээллийн технологийн мэргэжилтнүүдийн дунд зөв эсэхээс үл хамааран энэ нэр томъёог буруугаар ашиглах нь SEO-ийн байршлыг сайжруулахад хүргэж болзошгүй гэсэн нийтлэг ойлголтыг харуулж байна. монополийг урвуулан ашигласан гэж буруутгаж байна болон хэт их сурталчилгаа энэ онолын хил хязгаарыг бүдгэрүүлэх).
10: Стохастик градиент удам
Стохастик градиент уналт (SGD) нь машин сургалтын загваруудын сургалтыг оновчтой болгох улам бүр түгээмэл хэрэглэгддэг арга юм.
Gradient Descent нь өөрөө сургалтын явцад загвар хийж буй сайжруулалтыг оновчтой болгох, улмаар тоон үзүүлэлтийг гаргах арга юм.
Энэ утгаараа 'градиент' нь доошоо чиглэсэн налууг (өнгөт суурилсан градиент гэхээсээ илүү, доорх зургийг харна уу) заадаг бөгөөд зүүн талд байгаа 'толгод'-ын хамгийн өндөр цэг нь сургалтын үйл явцын эхлэлийг илэрхийлдэг. Энэ үе шатанд загвар нь нэг удаа ч гэсэн өгөгдлийг бүхэлд нь харж амжаагүй байгаа бөгөөд үр дүнтэй хувиргалтыг бий болгохын тулд өгөгдөл хоорондын харилцааны талаар хангалттай суралцаагүй байна.

FaceSwap сургалтын хэсэг дээр градиент буурах. Сургалт хоёрдугаар хагаст хэсэг хугацаанд өндөрлөсөн боловч эцэст нь градиент уруудаж, хүлээн зөвшөөрөгдөхүйц нэгдэл рүү буцсаныг бид харж байна.
Баруун талд байгаа хамгийн доод цэг нь нэгдмэл байдлыг илэрхийлдэг (загвар нь тогтоосон хязгаарлалт, тохиргооны дор хэзээ ч үр дүнтэй байх болно).
Градиент нь алдааны түвшин (загвар одоогоор өгөгдлийн хамаарлыг хэр нарийвчлалтай харуулсан) болон жин (загвар сурах аргад нөлөөлдөг тохиргоо) хоорондын зөрүүг бүртгэх, урьдчилан таамаглах үүрэг гүйцэтгэдэг.
Энэ ахиц дэвшлийн бүртгэлийг мэдээлэл өгөхөд ашиглаж болно суралцах хурдны хуваарь, эртний тодорхойгүй нарийн ширийн зүйлс тодорхой харилцаа холбоо, зураглал болж хувирах тусам архитектурыг илүү нарийн, нарийвчлалтай болгохыг хэлдэг автомат процесс. Үнэн хэрэгтээ, градиент алдагдал нь сургалтын дараа хаашаа явах, хэрхэн үргэлжлэх талаар цаг алдалгүй зураглалыг өгдөг.
Stochastic Gradient Descent-ийн шинэлэг зүйл нь давталт бүрт сургалтын жишээн дээрх загварын параметрүүдийг шинэчилдэг бөгөөд энэ нь ерөнхийдөө нэгдэх аяныг хурдасгадаг. Сүүлийн жилүүдэд хэт масштабтай өгөгдлийн багц гарч ирснээр SGD нь логистикийн асуудлыг шийдвэрлэх боломжит аргуудын нэг болж сүүлийн үед түгээмэл болж байна.
Нөгөөтэйгүүр, SGD сөрөг үр дагавар онцлогийг масштабаар тооцох ба ижил үр дүнд хүрэхийн тулд ердийн Gradient Descent-тэй харьцуулахад нэмэлт төлөвлөлт, нэмэлт параметрүүдийг шаарддаг.
Түгээмэл хэрэглээ
Тохируулах боломж, дутагдалтай байдлаас үл хамааран SGD нь мэдрэлийн сүлжээг тохируулах хамгийн алдартай оновчлолын алгоритм болжээ. AI/ML судалгааны шинэ бүтээлүүдэд давамгайлж буй SGD-ийн нэг тохиргоо нь Дасан зохицох агшины тооцоолол (ADAM, танилцуулсан) сонголт юм. 2015 нь) оновчтой болгох.
ADAM нь параметр тус бүрийн сургалтын хурдыг динамикаар ('дасан зохицох сургалтын хурд') тохируулж, өмнөх шинэчлэлтүүдийн үр дүнг дараагийн тохиргоонд ('momentum') нэгтгэдэг. Нэмж дурдахад, энэ нь дараагийн шинэлэг зүйлүүдийг ашиглахаар тохируулж болно, тухайлбал Нестеровын эрч хүч.
Гэсэн хэдий ч зарим нь импульс ашиглах нь ADAM (болон үүнтэй төстэй алгоритмуудыг) хурдасгах боломжтой гэж үздэг оновчтой бус дүгнэлт. Машин сургалтын судалгааны салбарын ихэнх цус алдалтын нэгэн адил SGD нь хийгдэж буй ажил юм.
Анх 10 оны 2022-р сарын 10-нд нийтлэгдсэн. Өөрчлөгдсөн 20.05-р сарын XNUMX-ны XNUMX EET – форматлах.















