
Dirbtinis intelektas
OLMo: Kalbos modelių mokslo tobulinimas

Kalbos modelių kūrimas ir pažanga per pastaruosius kelerius metus pažymėjo jų buvimą beveik visur, ne tik NLP tyrimuose, bet ir komerciniuose pasiūlymuose bei realiose programose. Tačiau išaugusi komercinė kalbų modelių paklausa tam tikru mastu stabdė bendruomenės augimą. Taip yra todėl, kad dauguma naujausių ir pažangių modelių yra už nuosavybės sąsajų, todėl kūrėjai negali pasiekti svarbios mokymo architektūros, duomenų ir kūrimo procesų informacijos. Dabar neabejotina, kad šie mokymai ir struktūrinės detalės yra labai svarbios atliekant mokslinius tyrimus, įskaitant prieigą prie galimos rizikos ir šališkumo, todėl mokslinių tyrimų bendruomenei keliamas reikalavimas turėti prieigą prie tikrai atviro ir galingo kalbos modelio.
Kad atitiktų šį reikalavimą, kūrėjai sukūrė OLMo – pažangiausią, tikrai atvirą kalbos modelio sistemą. Ši sistema leidžia mokslininkams naudoti OLMo kalbos modeliams kurti ir studijuoti. Skirtingai nuo daugumos naujausių kalbų modelių, kurie išleido tik sąsajos kodą ir modelio svarmenis, OLMo sistema yra tikrai atvirojo kodo, su viešai prieinamu vertinimo kodu, mokymo metodais ir mokymo duomenimis. Pagrindinis OLMo tikslas yra suteikti daugiau galimybių atvirai mokslinių tyrimų bendruomenei ir nuolat plėtoti kalbos modelius.
Šiame straipsnyje mes išsamiai aptarsime OLMo sistemą, išnagrinėsime jos architektūrą, metodiką ir našumą, palyginti su dabartinėmis pažangiausiomis sistemomis. Taigi, pradėkime.
OLMo: Kalbos modelių mokslo tobulinimas
Kalbos modelis, be abejo, buvo karščiausia tendencija per pastaruosius kelerius metus ne tik AI ir ML bendruomenėje, bet ir technologijų pramonėje, nes jis puikiai sugeba atlikti realaus pasaulio užduotis su žmogaus našumu. „ChatGPT“ yra puikus galimų kalbų modelių pavyzdys, kai pagrindiniai technologijų pramonės žaidėjai tiria kalbos modelių integravimą su savo produktais.
NLP arba natūralios kalbos apdorojimas yra viena iš pramonės šakų, kuri per pastaruosius kelerius metus plačiai taikė kalbos modelius. Tačiau nuo tada, kai pramonė pradėjo naudoti žmogaus anotacijas derinimui ir didelio masto išankstiniam mokymui, kalbos modelių komercinis gyvybingumas sparčiai pagerėjo, todėl dauguma pažangiausių kalbos ir NLP sistemų apribojo. patentuotos sąsajos, o kūrimo bendruomenė neturi prieigos prie svarbios informacijos.
Siekdama užtikrinti kalbos modelių pažangą, OLMo, moderniausias, tikrai atviros kalbos modelis, siūlo kūrėjams pagrindą kurti, studijuoti ir tobulinti kalbos modelius. Ji taip pat suteikia mokslininkams prieigą prie mokymo ir vertinimo kodo, mokymo metodikos, mokymo duomenų, mokymo žurnalų ir tarpinių modelių patikros taškų. Esami moderniausi modeliai turi skirtingą atvirumo laipsnį, o OLMo modelis išleido visą sistemą, nuo mokymo iki duomenų iki vertinimo įrankių, taip sumažindamas našumo atotrūkį, palyginti su moderniausiais modeliais, pvz., LLaMA2 modelis.
Modeliavimui ir mokymui OLMo sistema apima treniruočių kodą, visus modelio svorius, abliacijas, treniruočių žurnalus ir treniruočių metriką sąsajos kodo pavidalu, taip pat svorio ir šališkumo žurnalus. Analizei ir duomenų rinkinio kūrimui OLMo sistema apima visus treniruočių duomenis, naudojamus AI2 Dolma ir WIMBD modeliams, kartu su kodu, kuris gamina mokymo duomenis. Vertinimo tikslais OLMo sistema apima AI2 „Catwalk“ modelį, skirtą tolesniam vertinimui, ir „Paloma“ modelį, skirtą sumišimu pagrįstam vertinimui.
OLMo: modelis ir architektūra
OLMo modelis naudoja tik dekoderio transformatoriaus architektūrą, pagrįstą neuroninėmis informacijos apdorojimo sistemomis, ir pateikia du modelius su atitinkamai 1 milijardu ir 7 milijardais parametrų, o šiuo metu kuriamas 65 milijardų parametrų modelis.

OLMo sistemos architektūra suteikia keletą patobulinimų, palyginti su sistemomis, įskaitant vanilės transformatoriaus komponentą jų architektūroje, įskaitant naujausią techniką. didelių kalbų modeliai kaip OpenLM, Falcon, LLaMA ir PaLM. Toliau pateiktame paveikslėlyje palyginamas OLMo modelis su 7 mlrd. milijardų parametrų su naujausiais LLM, veikiančiais beveik vienodu parametrų skaičiumi.

OLMo sistema parenka hiperparametrus optimizuodama modelį, skirtą aparatinės įrangos pralaidumui treniruoti, tuo pačiu sumažindama lėto skirtumo ir nuostolių šuolio riziką. Atsižvelgiant į tai, pagrindiniai OLMo sistemos pakeitimai, kurie skiriasi nuo vanilės transformatoriaus architektūros, yra šie:
Nėra šališkumo
Skirtingai nuo „Falcon“, „PaLM“, „LLaMA“ ir kitų kalbų modelių, „OLMo“ sistemoje nėra jokio šališkumo savo architektūroje, kad būtų padidintas mokymo stabilumas.
Neparametrinio sluoksnio norma
OLMo sistema savo architektūroje įgyvendina neparametrinę sluoksnio normos formuluotę. Neparametrinio sluoksnio norma nesiūlo jokios afininės transformacijos normos ribose, ty nesiūlo jokio adaptyvaus stiprinimo ar šališkumo. Neparametrinio sluoksnio norma ne tik suteikia didesnį saugumą nei parametrinio sluoksnio normos, bet ir yra greitesnė.
SwiGLU aktyvinimo funkcija
Kaip ir daugumoje kalbų modelių, tokių kaip PaLM ir LLaMA, OLMo sistema į savo architektūrą įtraukė SwiGLU aktyvinimo funkciją, o ne ReLU aktyvinimo funkciją, ir padidina paslėpto aktyvinimo dydį iki artimiausio 128 kartotinio, kad pagerintų pralaidumą.
Virvės arba sukamieji padėties įterpimai
OLMo modeliai seka LLaMA ir PaLM modelius ir keičia absoliučią padėties įterpimą į lynų arba sukamąsias padėties įterpimus.
Išankstinė treniruotė su Dolma
Nors kūrėjų bendruomenė dabar turi geresnę prieigą prie modelio parametrų, durys prieiti prie išankstinio mokymo duomenų rinkinių vis dar lieka uždarytos, nes išankstinio mokymo duomenys nėra skelbiami kartu su uždarais modeliais arba kartu su atvirais modeliais. Be to, tokius duomenis apimančiuose techniniuose dokumentuose dažnai trūksta svarbios informacijos, reikalingos norint visiškai suprasti ir atkartoti modelį. Dėl kliūties sunku tęsti tyrimus tam tikrose gijose kalbos modelis tyrimai, įskaitant supratimą, kaip mokymo duomenys veikia modelio galimybes ir apribojimus. OLMo sistema sukūrė ir išleido savo išankstinio mokymo duomenų rinkinį „Dolma“, kad palengvintų atvirą kalbos modelio išankstinio mokymo tyrimą. „Dolma“ duomenų rinkinys yra kelių šaltinių ir įvairus rinkinys, susidedantis iš daugiau nei 3 trilijonų žetonų iš 5 milijardų dokumentų, surinktų iš 7 skirtingų šaltinių, kuriuos paprastai naudoja galingi didelio masto LLM išankstiniam mokymui ir yra prieinami plačiajai auditorijai. Dolma duomenų rinkinio sudėtis apibendrinta šioje lentelėje.
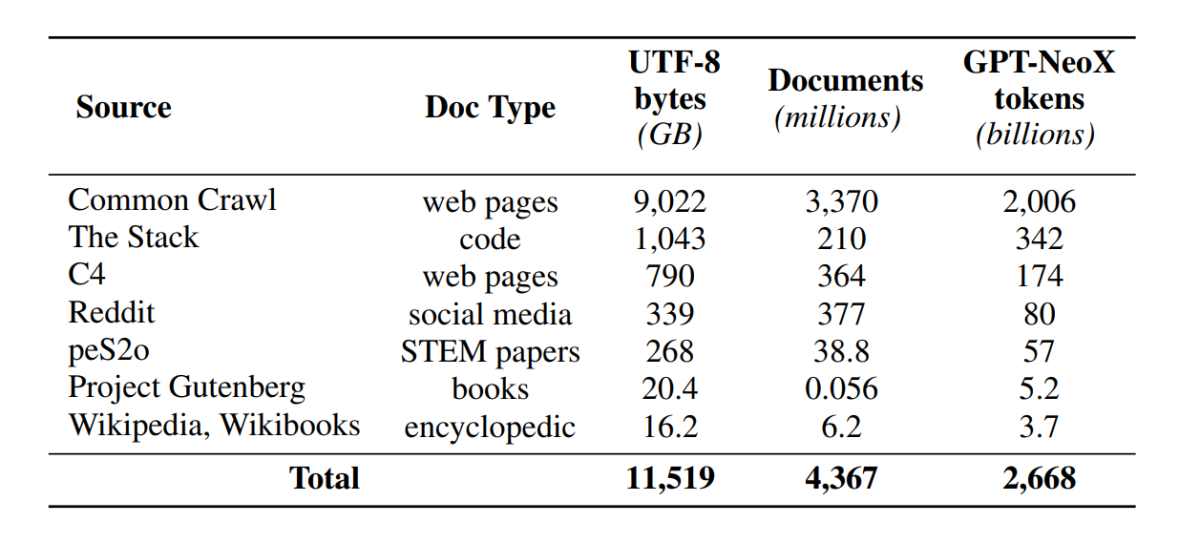
„Dolma“ duomenų rinkinys sukurtas naudojant 5 komponentų konvejerį: kalbos filtravimą, kokybės filtravimą, turinio filtravimą, kelių šaltinių maišymą, dubliavimo panaikinimą ir prieigos raktą. „OLMo“ taip pat išleido „Dolma“ ataskaitą, kurioje pateikiama daugiau įžvalgų apie projektavimo principus ir konstrukcijos detales bei išsamesnę turinio santrauką. Modelis taip pat turi savo didelio našumo duomenų tvarkymo įrankius, kad būtų galima lengvai ir greitai kuruoti išankstinio mokymo duomenų korpusus. Modelis vertinamas pagal dviejų etapų strategiją, pradedant nuo internetinio įvertinimo, kad būtų galima priimti sprendimus modelio mokymo metu, ir galutiniu neprisijungus įvertinimu, kad būtų galima atlikti bendrą įvertinimą iš modelio kontrolinių punktų. Vertindama neprisijungus, OLMo naudoja Catwalk sistemą – mūsų viešai prieinamą vertinimo įrankį, turintį prieigą prie įvairių duomenų rinkinių ir užduočių formatų. Sistema naudoja Catwalk paskesniam vertinimui, taip pat vidinio kalbos modeliavimo vertinimui pagal mūsų naują painiavos etaloną Paloma. Tada OLMo palygina jį su keliais viešaisiais modeliais, naudodama fiksuotą vertinimo vamzdyną, kad įvertintų tiek pasroviui, tiek sumišimui.
Kuriant modelį, OLMo vykdo keletą vertinimo metrikų apie modelio architektūrą, inicijavimą, optimizatorius, mokymosi greičio grafiką ir duomenų mišinius. Kūrėjai tai vadina OLMo „internetu įvertinimu“, nes tai yra ciklo iteracija kas 1000 mokymo žingsnių (arba ~ 4B mokymo žetonų), kad būtų duotas ankstyvas ir nuolatinis signalas apie mokomo modelio kokybę. Šių vertinimų sąranka priklauso nuo daugelio pagrindinių užduočių ir eksperimento nustatymų, naudojamų vertinant neprisijungus. OLMo siekia ne tik palyginti OLMo-7B su kitais modeliais, kad būtų pasiektas geriausias našumas, bet ir parodyti, kaip jis leidžia atlikti išsamesnį ir labiau kontroliuojamą mokslinį vertinimą. OLMo-7B yra didžiausias kalbos modelis su aiškiu dezaktyvavimu, kad būtų galima įvertinti sumišimą.
OLMo mokymas
Svarbu pažymėti, kad OLMo sistemos modeliai yra mokomi naudojant ZeRO optimizavimo strategiją, kurią teikia FSDP sistema per PyTorch, ir tokiu būdu žymiai sumažinamas GPU atminties suvartojimas, nes modelio svoris skiriasi nuo GPU. Taikant 7B skalę, mūsų aparatinėje įrangoje galima atlikti 4096 žetonų mikro partijos dydį. OLMo-1B ir -7B modelių mokymo sistemoje naudojamas visame pasaulyje pastovus maždaug 4 mln. prieigos raktų partijos dydis (2048 egzemplioriai, kurių kiekvienos sekos ilgis yra 2048 prieigos raktai). Modeliui OLMo-65B (šiuo metu mokomasi) kūrėjai naudoja partijos dydžio apšilimą, kuris prasideda nuo maždaug 2M žetonų (1024 egzemplioriai), padvigubinant kas 100B žetonų iki maždaug 16M žetonų (8192 egzemplioriai).
Norėdami pagerinti pralaidumą, naudojame mišraus tikslumo mokymus (Micikevičius ir kt., 2017) per FSDP integruotus nustatymus ir PyTorch stiprintuvo modulį. Pastaroji užtikrina, kad tam tikros operacijos, pvz., „Softmax“, visada būtų vykdomos visiškai tiksliai, kad būtų pagerintas stabilumas, o visos kitos operacijos atliekamos pusiau tiksliai naudojant bfloat16 formatą. Pagal mūsų konkrečius nustatymus kiekvieno GPU suskaidytų modelių svoriai ir optimizatoriaus būsena išlaikomi visiškai tiksliai. Svoriai kiekviename transformatoriaus bloke perduodami tik į bfloat16 formatą, kai kiekvieno GPU perjungiant pirmyn ir atgal yra matuojami viso dydžio parametrai. Gradientai sumažinami visu GPU tikslumu.
Optimizatorius
OLMo sistema naudoja AdamW optimizavimo priemonę su šiais hiperparametrais.

Visų dydžių modelių mokymosi greitis tiesiškai įšyla per pirmuosius 5000 21 žingsnių (∼ 1.0 B žetonų) iki didžiausios vertės, o tada tiesiškai mažėja su atvirkštine žingsnio skaičiaus kvadratine šaknimi iki nurodyto minimalaus mokymosi greičio. Pasibaigus apšilimo laikotarpiui, modelis nupjauna gradientus taip, kad bendra parametrų gradientų l norma neviršytų 7. Šioje lentelėje pateikiami mūsų optimizavimo XNUMXB skalės parametrų palyginimai su kitų naujausių LM, kurie taip pat naudojo AdamW, parametrais.

Treniruočių duomenys
Mokymas apima mokymo egzempliorių atpažinimą pagal žodį ir BPE prieigos raktą sakinio dalies modeliui, kiekvieno dokumento pabaigoje pridėjus specialų EOS prieigos raktą, tada sugrupuojame 2048 prieigos raktų dalis, kad sudarytume mokymo egzempliorius. Treniruotės yra sumaišomos lygiai taip pat kiekvienam treniruočių bėgimui. Duomenų tvarką ir tikslią kiekvienos mokymo partijos sudėtį galima atkurti iš mūsų išleistų artefaktų. Visi išleisti OLMo modeliai buvo išmokyti naudoti bent 2T žetonus (viena epocha per mokymo duomenis), o kai kurie buvo mokomi vėliau, pradedant antrą duomenų epochą kita maišymo tvarka. Atsižvelgiant į nedidelį duomenų kiekį, kuris kartojasi, tai turėtų turėti nereikšmingą poveikį.
rezultatai
Kontrolinis taškas, naudojamas vertinant OLMo-7B, yra apmokytas iki 2.46 T žetonų Dolma duomenų rinkinyje, naudojant anksčiau minėtą linijinio mokymosi greičio mažinimo grafiką. Toliau derinant šį kontrolinį tašką Dolma duomenų rinkinyje 1000 žingsnių su tiesiškai mažėjančiu mokymosi dažniu iki 0, dar labiau padidina modelio našumą, susijusį su anksčiau aprašytais sudėtingumo ir galutinių užduočių vertinimo rinkiniais. Galutiniam vertinimui kūrėjai palygino OLMo su kitais viešai prieinamais modeliais – LLaMA-7B, LLaMA2-7B, Pythia-6.9B, Falcon-7B ir RPJ-INCITE-7B.
Tolesnis vertinimas
Pagrindinis tolesnio vertinimo rinkinys apibendrintas šioje lentelėje.
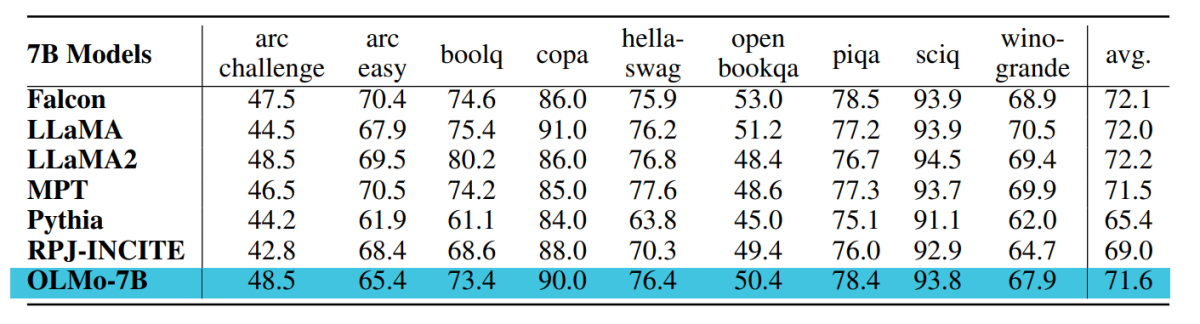
Visais atvejais atliekame nulinį vertinimą pagal rangų klasifikavimo metodą. Šiuo požiūriu kandidatas teksto užbaigimai (pvz., įvairios kelių pasirinkimų parinktys) reitinguojamos pagal tikimybę (dažniausiai normalizuojamos pagal tam tikrą normalizavimo veiksnį), o numatymo tikslumas pateikiamas.
Nors „Catwalk“ naudoja kelis tipinius tikimybių normalizavimo metodus, pvz., normalizavimą pagal žetoną ir normalizavimą pagal simbolį, taikomos normalizavimo strategijos kiekvienam duomenų rinkiniui parenkamos atskirai ir apima besąlyginę atsakymo tikimybę. Konkrečiau kalbant, tai neapėmė jokio arc ir openbookqa užduočių normalizavimo, hellaswag, piqa ir winogrande užduočių normalizavimo pagal raktą ir boolq, copa ir sciq užduočių normalizavimo (ty užduočių formuluotėje, artimoje vienam žetonui prognozavimo užduotis).

Toliau pateiktame paveikslėlyje parodyta devynių pagrindinių galutinių užduočių tikslumo balo eiga. Galima daryti išvadą, kad visų užduočių, išskyrus OBQA, tikslumo skaičiaus didėjimo tendencija, nes OLMo-7B toliau mokomas naudoti daugiau žetonų. Staigus daugelio užduočių tikslumo padidėjimas tarp paskutinio ir antrojo iki paskutinio žingsnio rodo, kad LR tiesiškai sumažinama iki 0 per paskutinius 1000 treniruočių žingsnių. Pavyzdžiui, vidinių vertinimų atveju Paloma argumentuoja atlikdama daugybę analizių, pradedant kiekvienos srities našumo patikrinimu atskirai ir baigiant labiau apibendrintais rezultatais, susijusiais su sričių deriniais. Pateikiame dviejų detalumo lygių rezultatus: bendrą našumą 11 iš 18 šaltinių Palomoje, taip pat tikslesnius kiekvieno iš šių šaltinių rezultatus atskirai.

Baigiamosios mintys
Šiame straipsnyje mes kalbėjome apie OLMo – pažangiausią, tikrai atviros kalbos modelį, kuris siūlo kūrėjams pagrindą kurti, studijuoti ir tobulinti kalbos modelius, taip pat suteikia mokslininkams prieigą prie jo mokymo ir vertinimo kodo, mokymo metodikos, treniruočių duomenys, treniruočių žurnalai ir tarpiniai modelio kontroliniai taškai. Esami modernūs modeliai turi skirtingą atvirumo laipsnį, o OLMo modelis išleido visą sistemą nuo mokymo iki duomenų iki vertinimo įrankių, taip sumažindamas našumo atotrūkį, palyginti su moderniausiais modeliais, tokiais kaip LLaMA2 modelis.















