
Greita inžinerija
„ChatGPT“ ir pažangioji greitoji inžinerija: dirbtinio intelekto evoliucijos skatinimas

„OpenAI“ prisidėjo kuriant revoliucinius įrankius, tokius kaip „OpenAI Gym“, skirtą lavinti sustiprinimo algoritmus, ir GPT-n modelius. Taip pat dėmesio centre yra DALL-E – dirbtinio intelekto modelis, kuris kuria vaizdus iš tekstinės įvesties. Vienas iš tokių didelio dėmesio sulaukusių modelių yra OpenAI ChatGPT, puikus pavyzdys didelių kalbų modelių srityje.
GPT-4: Greita inžinerija
„ChatGPT“ pakeitė pokalbių robotų aplinką, siūlydama žmonėms panašius atsakymus į vartotojo įvestį ir išplėtusi savo programas įvairiose srityse – nuo programinės įrangos kūrimo ir testavimo iki verslo komunikacijos ir net poezijos kūrimo.
Pavyzdžiui, įmonių ir asmenų rankose GPT-4 galėtų būti neišsenkantis žinių rezervuaras, išmanantis dalykus nuo matematikos ir biologijos iki teisės studijų. Tokie sudėtingi ir prieinami AI modeliai yra pasirengę iš naujo apibrėžti darbo, mokymosi ir kūrybiškumo ateitį.

Generatyvieji modeliai, tokie kaip GPT-4, gali sukurti naujus duomenis, pagrįstus esamomis įvestimis. Šis išskirtinis požymis leidžia jiems atlikti įvairias užduotis, įskaitant teksto, vaizdų, muzikos ir vaizdo įrašų generavimą.
ChatGPT ir OpenAI modelių kontekste raginimas yra įvestis, kurią vartotojai pateikia modeliams, dažniausiai teksto forma. Raginimai yra pagrindinė šių modelių generuojamų rezultatų valdymo priemonė, todėl jie yra labai svarbūs sėkmingiems ir aktualiems pokalbiams.
Greitos kokybės poveikis
Tiksliai apibrėžtų raginimų naudojimas yra raktas į naudingus ir prasmingus pokalbius su AI sistemomis. Prastai apibrėžti raginimai gali sukelti išvestį, kuri nėra naudinga vartotojui ir netgi gali sukelti klaidinantį turinį.
Norėdami parodyti raginimų kokybės poveikį, palyginkime du skirtingus ChatGPT raginimus. Pirmasis raginimas, prastai apibrėžtas ir numanantis išankstines žinias, sukelia potencialiai nenaudingą vartotojui atsakymą. Kita vertus, antrasis raginimas pateikia daugiau konteksto ir pavyzdžių, užtikrinant aktualesnį ir suprantamesnį atsakymą.
Raginimas 1: „Papasakok man apie konvoliucinius neuroninius tinklus“.
1 atsakas: „Konvoliuciniai neuroniniai tinklai (CNN) yra daugiasluoksniai perceptroniniai tinklai, susidedantys iš visiškai sujungtų sluoksnių ir telkinių sluoksnių. Jie dažniausiai naudojami vaizdų atpažinimo užduotims atlikti. Procesas apima filtrų taikymą įvesties vaizdams ir jų sumažinimą naudojant telkimo sluoksnius.
Raginimas 2: „Noriu sužinoti apie konvoliucinius neuroninius tinklus, bet neturiu išankstinių žinių apie dirbtinius neuroninius tinklus. Ar galite pateikti pradedantiesiems patogų paaiškinimą ir pavyzdį, kaip CNN naudojami vaizdų atpažinimui?
2 atsakas: „Konvoliuciniai neuroniniai tinklai (CNN) yra neuroninio tinklo tipas, pirmiausia naudojamas vaizdų atpažinimo užduotims atlikti. Skirtingai nuo kitų neuroninių tinklų, vaizdams apdoroti jie naudoja konvoliucinius sluoksnius ir telkimo sluoksnius. Įsivaizduokite, kad turite katės atvaizdą. CNN gali atpažinti įvairias vaizdo ypatybes, pvz., ūsus, ausis ir uodegą, taikydami filtrus ir sumažindami vaizdo mėginius naudodami telkinius. Dėl šio proceso CNN yra labai veiksmingi atpažįstant objektus vaizduose.
Palyginus du atsakymus, akivaizdu, kad tiksliai apibrėžtas raginimas suteikia tinkamesnį ir patogesnį atsakymą. Greitas projektavimas ir inžinerija yra augančios disciplinos, kuriomis siekiama optimizuoti AI modelių, tokių kaip „ChatGPT“, išvesties kokybę.
Tolesnėse šio straipsnio dalyse gilinsimės į pažangių metodikų, skirtų patobulinti didelių kalbų modelius (LLM), sferą, pvz., greitus inžinerinius metodus ir taktiką. Tai apima mokymąsi iš kelių kartų, ReAct, minties grandinę, RAG ir kt.
Išplėstinė inžinerinė technika
Prieš tęsdami, svarbu suprasti pagrindinę LLM problemą, vadinamą „haliucinacijomis“. LLM kontekste „haliucinacijos“ reiškia šių modelių tendenciją generuoti rezultatus, kurie gali atrodyti pagrįsti, bet nesusiję su faktine tikrove ar pateiktu įvesties kontekstu.
Ši problema buvo ryškiai pabrėžta neseniai vykusioje teismo byloje, kurioje naudojosi gynėjas ChatGPT teisiniams tyrimams. AI įrankis, šlubuojantis dėl haliucinacijų problemos, nurodė neegzistuojančius teisinius atvejus. Šis klaidingas žingsnis turėjo didelių pasekmių, sukėlė painiavą ir sumažino patikimumą proceso metu. Šis incidentas yra ryškus priminimas, kad reikia skubiai spręsti „haliucinacijų“ AI sistemose problemą.
Mūsų tyrinėjimai apie greitus inžinerinius metodus siekia patobulinti šiuos LLM aspektus. Didindami jų efektyvumą ir saugumą, atveriame kelią naujoviškoms programoms, tokioms kaip informacijos gavimas. Be to, tai atveria duris sklandžiai integruoti LLM su išoriniais įrankiais ir duomenų šaltiniais, praplečiant jų galimo panaudojimo spektrą.
Nulinis mokymasis ir mokymasis nedaug: optimizavimas naudojant pavyzdžius
Generatyvieji iš anksto apmokyti transformatoriai (GPT-3) tapo svarbiu lūžio tašku kuriant generatyvius dirbtinio intelekto modelius, nes jie pristatė koncepciją „kelių kadrų mokymasis.' Šis metodas pakeitė žaidimą, nes jis gali veiksmingai veikti nereikalaujant išsamaus koregavimo. GPT-3 sistema aptariama straipsnyje „Kalbų modeliai mažai mokosi“, kur autoriai demonstruoja, kaip modelis puikiai tinka įvairiais naudojimo atvejais, nereikalaujant pasirinktinių duomenų rinkinių ar kodo.
Skirtingai nuo koregavimo, dėl kurio reikia nuolat stengtis išspręsti įvairius naudojimo atvejus, kelių kadrų modeliai yra lengviau pritaikomi prie įvairesnių programų. Nors patikslinimas kai kuriais atvejais gali suteikti patikimų sprendimų, jis gali būti brangus, todėl kelių kadrų modelių naudojimas yra praktiškesnis būdas, ypač kai jis integruotas su greita inžinerija.
Įsivaizduokite, kad bandote išversti iš anglų į prancūzų kalbą. Mokydamiesi kelių kartų, GPT-3 pateiktumėte kelis vertimo pavyzdžius, pvz., „jūrinė ūdra -> loutre de mer“. GPT-3, kaip pažangus modelis, gali ir toliau teikti tikslius vertimus. Mokydamiesi „nulinio kadro“ nepateiktumėte jokių pavyzdžių, o GPT-3 vis tiek galėtų efektyviai išversti anglų kalbą į prancūzų kalbą.
Sąvoka „mokymasis per kelis kartus“ kilo iš minties, kad modeliui pateikiamas ribotas pavyzdžių, iš kurių galima „pasimokyti“, skaičius. Svarbu pažymėti, kad „mokymasis“ šiame kontekste nereiškia modelio parametrų ar svorių atnaujinimo, veikiau turi įtakos modelio veikimui.

GPT-3 dokumente parodyta, kad mokomasi nedaug
Nulinis mokymasis perkelia šią koncepciją dar vienu žingsniu. Nulinio mokymosi metu modelyje nepateikiami jokie užduočių atlikimo pavyzdžiai. Tikimasi, kad modelis veiks gerai, remiantis pradiniu mokymu, todėl ši metodika idealiai tinka atviro domeno klausimų atsakymų scenarijams, pvz., ChatGPT.
Daugeliu atvejų modelis, įgudęs mokytis be nulio kadrų, gali gerai veikti, kai jam pateikiami kelių ar net vieno kadro pavyzdžiai. Šis gebėjimas perjungti iš nulinio, vieno ir kelių kadrų mokymosi scenarijus pabrėžia didelių modelių pritaikomumą, padidindamas jų galimą pritaikymą įvairiose srityse.
Nuliniai mokymosi metodai tampa vis labiau paplitę. Šie metodai pasižymi gebėjimu atpažinti treniruočių metu nematomus objektus. Pateikiame praktinį „Fow-Shot Prompt“ pavyzdį:
"Translate the following English phrases to French:
'sea otter' translates to 'loutre de mer'
'sky' translates to 'ciel'
'What does 'cloud' translate to in French?'"
Pateikę modeliui kelis pavyzdžius ir užduodami klausimą, galime efektyviai nukreipti modelį generuoti norimą išvestį. Šiuo atveju GPT-3 greičiausiai teisingai išverstų „debesis“ į „nuage“ prancūzų kalba.
Mes gilinsimės į įvairius greitos inžinerijos niuansus ir jos esminį vaidmenį optimizuojant modelio veikimą darant išvadas. Taip pat apžvelgsime, kaip jį galima efektyviai panaudoti kuriant ekonomiškus ir keičiamo dydžio sprendimus įvairiais naudojimo atvejais.
Toliau tyrinėjant greitų inžinerinių metodų sudėtingumą GPT modeliuose, svarbu pabrėžti paskutinį mūsų įrašą „Pagrindinis „ChatGPT“ operatyvios inžinerijos vadovas“. Šiame vadove pateikiama įžvalgų apie strategijas, kaip efektyviai instruktuoti dirbtinio intelekto modelius įvairiais naudojimo atvejais.
Ankstesnėse diskusijose mes gilinomės į pagrindinius didelių kalbų modelių (LLM) skubius metodus, tokius kaip nulinis ir kelių kadrų mokymasis, taip pat nurodymų raginimą. Šių metodų įsisavinimas yra labai svarbus norint įveikti sudėtingesnius greitos inžinerijos iššūkius, kuriuos čia išnagrinėsime.
Keletas kartų mokymasis gali būti apribotas dėl riboto daugumos LLM konteksto lango. Be to, be atitinkamų apsaugos priemonių, LLM gali būti suklaidinti ir pateikti potencialiai žalingą produkciją. Be to, daugeliui modelių sunku atlikti samprotavimo užduotis arba laikytis kelių žingsnių nurodymų.
Atsižvelgiant į šiuos apribojimus, iššūkis yra panaudoti LLM sprendžiant sudėtingas užduotis. Akivaizdus sprendimas galėtų būti pažangesnių LLM kūrimas arba esamų tobulinimas, tačiau tam gali prireikti didelių pastangų. Taigi kyla klausimas: kaip galime optimizuoti dabartinius modelius, kad būtų geriau sprendžiamos problemos?
Taip pat įdomu tyrinėti, kaip ši technika sąveikauja su kūrybinėmis programomis „Unite AI“AI meno įsisavinimas: glaustas vidurio kelionės ir greitos inžinerijos vadovas“, kuriame aprašoma, kaip meno ir dirbtinio intelekto sintezė gali sukelti baimę keliantį meną.
Minčių grandinės raginimas
Minčių grandinės raginimas išnaudoja būdingas automatinės regresines didelių kalbos modelių (LLM) savybes, kurios puikiai nuspėja kitą tam tikros sekos žodį. Skatindamas modelį išsiaiškinti savo mąstymo procesą, jis skatina nuodugnesnį, metodiškesnį idėjų generavimą, kuris linkęs glaudžiai susieti su tikslia informacija. Šis derinimas kyla iš modelio polinkio apdoroti ir teikti informaciją apgalvotai ir tvarkingai, panašiai kaip žmogaus ekspertas, kuris klausytoją perveda per sudėtingą koncepciją. Paprasto teiginio, pvz., „pažingsnis po žingsnio paaiškinkite, kaip…“ dažnai pakanka, kad suaktyvintumėte šį žodinį, išsamesnį rezultatą.
Nulinis minčių grandinės raginimas
Nors įprastiniam CoT raginimui reikalingas išankstinis mokymas su demonstracijomis, atsirandanti sritis yra nulinis CoT raginimas. Šį metodą pristatė Kojima ir kt. (2022), novatoriškai prideda frazę „Galvokime žingsnis po žingsnio“ prie pradinio raginimo.
Sukurkime išplėstinį raginimą, kuriame „ChatGPT“ bus pavesta apibendrinti pagrindinius AI ir NLP tyrimų dokumentus.
Šioje demonstracijoje naudosime modelio gebėjimą suprasti ir apibendrinti sudėtingą informaciją iš akademinių tekstų. Naudodami kelių kadrų mokymosi metodą, išmokykime „ChatGPT“ apibendrinti pagrindines AI ir NLP mokslinių darbų išvadas:
1. Paper Title: "Attention Is All You Need"
Key Takeaway: Introduced the transformer model, emphasizing the importance of attention mechanisms over recurrent layers for sequence transduction tasks.
2. Paper Title: "BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding"
Key Takeaway: Introduced BERT, showcasing the efficacy of pre-training deep bidirectional models, thereby achieving state-of-the-art results on various NLP tasks.
Now, with the context of these examples, summarize the key findings from the following paper:
Paper Title: "Prompt Engineering in Large Language Models: An Examination"
Šis raginimas ne tik palaiko aiškią minčių grandinę, bet ir naudoja kelių žingsnių mokymosi metodą modeliui vadovauti. Ji susieja su mūsų raktiniais žodžiais, daugiausia dėmesio skiriant AI ir NLP domenams, konkrečiai pavedant ChatGPT atlikti sudėtingą operaciją, susijusią su greita inžinerija: apibendrinti mokslinius darbus.
Reakcijos raginimas
„React“ arba „priežastis ir veikimas“ buvo pristatytas „Google“ dokumente „ReAct: samprotavimo ir veikimo sinergija kalbos modeliuose“ ir sukėlė revoliuciją, kaip kalbos modeliai sąveikauja su užduotimi, paskatindami modelį dinamiškai generuoti žodinio samprotavimo pėdsakus ir konkrečias užduotis.
Įsivaizduokite virtuvėje žmogų virėją: jie ne tik atlieka eilę veiksmų (pjausto daržoves, verda vandenį, maišo ingredientus), bet ir užsiima verbaliniais samprotavimais ar vidine kalba („dabar, kai daržovės susmulkintos, turėčiau uždėti puodą viryklė“). Šis nuolatinis psichinis dialogas padeda strateguoti procesą, prisitaikyti prie staigių pokyčių („Man baigėsi alyvuogių aliejus, vietoj jo naudosiu sviestą“) ir atsiminti užduočių seką. „React“ imituoja šį žmogaus gebėjimą, leidžiantį modeliui greitai išmokti naujų užduočių ir priimti tvirtus sprendimus, kaip tai padarytų žmogus naujomis ar neaiškiomis aplinkybėmis.
React gali susidoroti su haliucinacijomis – įprasta minčių grandinės (CoT) sistemų problema. CoT, nors ir veiksminga technika, neturi gebėjimo bendrauti su išoriniu pasauliu, o tai gali sukelti faktų haliucinacijas ir klaidų plitimą. Tačiau „React“ tai kompensuoja sąveikaudama su išoriniais informacijos šaltiniais. Ši sąveika leidžia sistemai ne tik patvirtinti savo samprotavimus, bet ir atnaujinti žinias, remiantis naujausia informacija iš išorinio pasaulio.
Pagrindinį „React“ veikimą galima paaiškinti naudojant „HotpotQA“ pavyzdį – užduotį, kuriai reikalingas aukšto lygio samprotavimas. Gavęs klausimą, „React“ modelis suskaido klausimą į valdomas dalis ir sukuria veiksmų planą. Modelis sukuria samprotavimo pėdsaką (mintį) ir nustato atitinkamą veiksmą. Ji gali nuspręsti ieškoti informacijos apie „Apple Remote“ iš išorinio šaltinio, pvz., „Wikipedia“ (veiksmas), ir atnaujinti savo supratimą, remdamasi gauta informacija (stebėjimas). Atlikdama kelis mąstymo ir veiksmo stebėjimo veiksmus, „ReAct“ gali gauti informaciją, kad pagrįstų savo samprotavimus, tuo pačiu patikslindama, ką reikia gauti toliau.
Pastaba:
HotpotQA yra duomenų rinkinys, gautas iš Vikipedijos, sudarytas iš 113 XNUMX klausimų ir atsakymų porų, skirtų dirbtinio intelekto sistemoms mokyti sudėtingų samprotavimų, nes norint atsakyti į klausimus, reikia samprotauti keliuose dokumentuose. Iš kitos pusės, CommonsenseQA 2.0, sukurta naudojant žaidimus, apima 14,343 XNUMX „taip“ / „ne“ klausimus ir yra sukurta tam, kad iššauktų AI sveiko proto supratimą, nes klausimai yra sąmoningai sukurti taip, kad suklaidintų AI modelius.
Procesas gali atrodyti maždaug taip:
- Mintis: „Man reikia ieškoti Apple Remote ir su juo suderinamų įrenginių.
- Veikla: išoriniame šaltinyje ieško „su Apple Remote suderinami įrenginiai“.
- Stebėjimas: iš paieškos rezultatų gaunamas įrenginių, suderinamų su Apple Remote, sąrašas.
- Mintis: „Remiantis paieškos rezultatais, keli įrenginiai, išskyrus „Apple Remote“, gali valdyti programą, su kuria iš pradžių buvo sukurta sąveikauti.
Rezultatas yra dinamiškas, samprotavimu pagrįstas procesas, kuris gali vystytis remiantis informacija, su kuria sąveikauja, todėl gaunami tikslesni ir patikimesni atsakymai.

Lyginamoji keturių raginimo metodų vizualizacija – Standartinis, Minties grandinės, Tik veikimas ir ReAct, sprendžiant HotpotQA ir AlfWorld (https://arxiv.org/pdf/2210.03629.pdf)
React agentų kūrimas yra specializuota užduotis, atsižvelgiant į jos gebėjimą pasiekti sudėtingų tikslų. Pavyzdžiui, pokalbio agentas, sukurtas remiantis baziniu „React“ modeliu, apima pokalbio atmintį, kad užtikrintų turtingesnę sąveiką. Tačiau šios užduoties sudėtingumą supaprastina tokie įrankiai kaip „Langchain“, kuris tapo šių agentų kūrimo standartu.
Kontekstui ištikimas raginimas
Popierius 'Kontekstą atitinkantis raginimas naudoti didelių kalbų modeliuspabrėžia, kad nors LLM pasisekdavo žiniomis pagrįstomis NLP užduotimis, per didelis jų pasitikėjimas parametrinėmis žiniomis gali juos suklaidinti atliekant kontekstui jautrias užduotis. Pavyzdžiui, kai kalbos modelis mokomas remiantis pasenusiais faktais, jis gali pateikti neteisingus atsakymus, jei nepaiso kontekstinių užuominų.
Ši problema akivaizdi žinių konflikto atvejais, kai kontekste yra faktų, kurie skiriasi nuo LLM jau turimų žinių. Apsvarstykite atvejį, kai Didžiosios kalbos modeliui (LLM), pagrįstam duomenimis prieš 2022 m. pasaulio čempionatą, pateikiamas kontekstas, rodantis, kad Prancūzija laimėjo turnyrą. Tačiau LLM, pasikliaudama iš anksto įgytomis žiniomis, ir toliau tvirtina, kad ankstesnė nugalėtoja, ty komanda, laimėjusi 2018 m. pasaulio čempionatą, vis dar yra karaliaujanti čempionė. Tai rodo klasikinį „žinių konflikto“ atvejį.
Iš esmės žinių konfliktas LLM kyla tada, kai nauja kontekste pateikta informacija prieštarauja jau turimoms žinioms, pagal kurias buvo mokomas modelis. Modelio tendencija remtis ankstesniu mokymu, o ne naujai pateiktame kontekste, gali sukelti neteisingus rezultatus. Kita vertus, haliucinacijos LLM yra atsakymų generavimas, kuris gali atrodyti tikėtinas, bet nėra pagrįstas modelio mokymo duomenimis ar pateiktame kontekste.
Kita problema kyla, kai pateiktame kontekste nėra pakankamai informacijos, kad būtų galima tiksliai atsakyti į klausimą, tokia situacija vadinama kaip prognozė susilaikius. Pavyzdžiui, jei LLM klausiama apie „Microsoft“ įkūrėją, remiantis kontekstu, kuris nepateikia šios informacijos, jis turėtų susilaikyti nuo spėlionių.
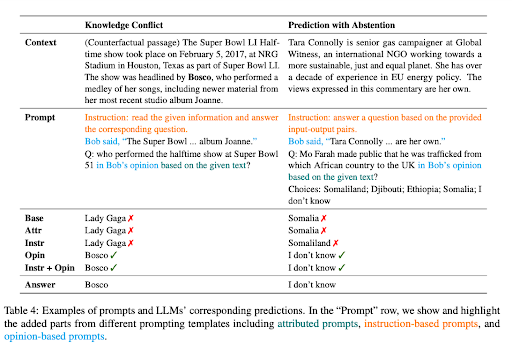
Daugiau žinių konflikto ir susilaikymo galios pavyzdžių
Siekdami pagerinti LLM kontekstinį ištikimybę šiuose scenarijuose, mokslininkai pasiūlė įvairias paskatinimo strategijas. Šiomis strategijomis siekiama, kad LLM atsakymai būtų labiau pritaikyti prie konteksto, o ne pasikliauti jų užkoduotomis žiniomis.
Viena iš tokių strategijų yra suformuluoti raginimus kaip nuomone pagrįstus klausimus, kai kontekstas interpretuojamas kaip pasakotojo teiginys, o klausimas susijęs su šio pasakotojo nuomone. Šis požiūris nukreipia LLM dėmesį į pateiktą kontekstą, o ne pasitelkia jau turimas žinias.
Taip pat nustatyta, kad priešingos padėties demonstravimas prie raginimų yra veiksmingas būdas padidinti ištikimybę žinių konflikto atvejais. Šios demonstracijos pateikia scenarijus su klaidingais faktais, kurie padeda modeliui skirti daugiau dėmesio kontekstui, kad būtų galima pateikti tikslius atsakymus.
Instrukcijų koregavimas
Instrukcijų koregavimas yra prižiūrimas mokymosi etapas, kurio metu modeliui pateikiamos konkrečios instrukcijos, pavyzdžiui, „Paaiškinkite skirtumą tarp saulėtekio ir saulėlydžio“. Instrukcija yra suporuota su tinkamu atsakymu, panašiu į: „Saulėtekis reiškia momentą, kai saulė ryte pasirodo horizonte, o saulėlydis žymi tašką, kai vakare saulė išnyksta žemiau horizonto“. Taikant šį metodą, modelis iš esmės mokosi, kaip laikytis instrukcijų ir vykdyti jas.
Šis metodas daro didelę įtaką LLM raginimo procesui, todėl radikaliai keičiasi raginimo stilius. Tiksliai sureguliuota LLM instrukcija leidžia nedelsiant atlikti nulinio šūvio užduotis ir užtikrinti sklandų užduočių atlikimą. Jei LLM dar reikia sureguliuoti, gali prireikti kelių žingsnių mokymosi metodo, įtraukiant keletą pavyzdžių į savo raginimą, kad modelis būtų nukreiptas į norimą atsakymą.
"Instrukcijų derinimas naudojant GPT-4′ aptariamas bandymas naudoti GPT-4 instrukcijų sekimo duomenims generuoti, kad būtų galima koreguoti LLM. Jie naudojo turtingą duomenų rinkinį, kurį sudaro 52,000 XNUMX unikalių instrukcijų įrašų anglų ir kinų kalbomis.
Duomenų rinkinys atlieka pagrindinį vaidmenį derinant instrukcijas LLaMA modeliai, atvirojo kodo LLM serija, dėl kurios patobulintas naujų užduočių našumas. Verti dėmesio projektai, tokie kaip Stanfordo alpaka efektyviai panaudojo Self-Instruct derinimą – veiksmingą metodą, skirtą LLM suderinti su žmogaus ketinimais, panaudojant duomenis, sugeneruotus naudojant pažangius pagal instrukcijas suderintus mokytojų modelius.

Pagrindinis instrukcijų derinimo tyrimo tikslas yra padidinti LLM apibendrinimo gebėjimus nuliniais ir mažais kadrais. Tolesni duomenys ir modelio mastelio keitimas gali suteikti vertingų įžvalgų. Dabartinis GPT-4 duomenų dydis yra 52 KB, o bazinio LLaMA modelio dydis yra 7 milijardai parametrų, todėl yra didžiulis potencialas surinkti daugiau GPT-4 nurodymų atitinkančių duomenų ir sujungti juos su kitais duomenų šaltiniais, kad būtų galima rengti didesnius LLaMA modelius. už puikų našumą.
„STAR“: „Bootstrapping Reasoning with Reasoning“.
LLM potencialas ypač matomas atliekant sudėtingas samprotavimo užduotis, tokias kaip matematika ar sveiko proto klausimų atsakymas. Tačiau procesas, skatinantis kalbos modelį generuoti loginius pagrindus – laipsniškas pagrindimas arba „minčių grandinė“ – turi savo iššūkių. Dėl to dažnai reikia sukurti didelius loginių duomenų rinkinius arba paaukoti tikslumą, nes remiamasi tik kelių kadrų išvadomis.
„Savamokslis mąstytojas“ (ŽVAIGŽDĖ) siūlo novatorišką šių iššūkių sprendimą. Jis naudoja paprastą kilpą, kad nuolat gerintų modelio argumentavimo galimybes. Šis pasikartojantis procesas prasideda generuojant pagrindimą, kad būtų galima atsakyti į kelis klausimus, naudojant kelis racionalius pavyzdžius. Jei sugeneruoti atsakymai neteisingi, modelis dar kartą bando sugeneruoti pagrindimą, šį kartą pateikdamas teisingą atsakymą. Tada modelis tiksliai suderinamas pagal visus pagrindimus, dėl kurių buvo gauti teisingi atsakymai, ir procesas kartojamas.

STaR metodika, demonstruojanti jos koregavimo kilpą ir pavyzdinį pagrindimo generavimą CommonsenseQA duomenų rinkinyje (https://arxiv.org/pdf/2203.14465.pdf)
Norėdami tai iliustruoti praktiniu pavyzdžiu, apsvarstykite klausimą „Kas gali būti naudojamas nešioti mažą šunį? su atsakymų pasirinkimais nuo baseino iki krepšelio. STaR modelis sukuria pagrindimą, nustatantį, kad atsakymas turi būti toks, kuris gali nešti mažą šunį ir padaryti išvadą, kad krepšys, skirtas daiktams laikyti, yra teisingas atsakymas.
STaR metodas yra unikalus tuo, kad jis išnaudoja kalbos modelio jau turimus argumentavimo gebėjimus. Jame naudojamas savarankiško loginių priežasčių generavimo ir tobulinimo procesas, kartotinai paleidžiant modelio argumentavimo galimybes. Tačiau „STAR“ kilpa turi savo apribojimų. Modeliui gali nepavykti išspręsti naujų mokymo rinkinio problemų, nes jis negauna tiesioginio mokymo signalo apie problemas, kurių nepavyksta išspręsti. Norėdami išspręsti šią problemą, STaR įveda racionalizavimą. Kiekvienai problemai, į kurią modelis neatsako teisingai, jis sukuria naują pagrindimą, pateikdamas modeliui teisingą atsakymą, kuris leidžia modeliui mąstyti atgal.
Todėl STaR yra keičiamo dydžio įkrovos metodas, leidžiantis modeliams išmokti kurti savo loginius pagrindus, kartu mokantis spręsti vis sudėtingesnes problemas. STaR taikymas parodė daug žadančių rezultatų atliekant užduotis, susijusias su aritmetika, matematinėmis tekstinėmis problemomis ir sveiko proto samprotavimu. „CommonsenseQA“ sistemoje STaR pagerėjo tiek kelių kadrų pradine linija, tiek pradine linija, tiksliai sureguliuota, kad būtų galima tiesiogiai numatyti atsakymus, ir veikė panašiai kaip 30 kartų didesnis modelis.
Pažymėti kontekstiniai raginimai
sąvoka "Pažymėti kontekstiniai raginimaiSukasi apie AI modelio suteikimą su papildomu konteksto sluoksniu, pažymint tam tikrą informaciją įvestyje. Šios žymos iš esmės veikia kaip AI orientyrai, padedantys tiksliai interpretuoti kontekstą ir sugeneruoti aktualų ir faktinį atsakymą.
Įsivaizduokite, kad kalbatės su draugu tam tikra tema, tarkime, „šachmatais“. Jūs darote pareiškimą ir pažymite jį nuoroda, pvz., „(šaltinis: Vikipedija)“. Dabar jūsų draugas, kuris šiuo atveju yra AI modelis, tiksliai žino, iš kur gaunama jūsų informacija. Šiuo metodu siekiama, kad dirbtinio intelekto atsakymai būtų patikimesni, sumažinant haliucinacijų arba klaidingų faktų generavimo riziką.
Unikalus pažymėtų konteksto raginimų aspektas yra jų potencialas pagerinti AI modelių kontekstinį intelektą. Pavyzdžiui, dokumente tai parodoma naudojant įvairius klausimus, gautus iš kelių šaltinių, pavyzdžiui, apibendrintus Vikipedijos straipsnius įvairiomis temomis ir neseniai išleistos knygos skyrius. Klausimai pažymėti, suteikiant AI modeliui papildomą kontekstą apie informacijos šaltinį.
Šis papildomas konteksto sluoksnis gali pasirodyti neįtikėtinai naudingas, kai reikia generuoti atsakymus, kurie yra ne tik tikslūs, bet ir atitinka pateiktą kontekstą, todėl dirbtinio intelekto išvestis tampa patikimesnė ir patikimesnė.
Išvada: pažvelgti į perspektyvius metodus ir ateities kryptis
„OpenAI“ „ChatGPT“ demonstruoja neatskleistą didelių kalbų modelių (LLM) potencialą sprendžiant sudėtingas užduotis nepaprastai efektyviai. Pažangūs metodai, tokie kaip mokymasis per kelis kartus, „ReAct“ raginimas, minties grandinė ir STaR, leidžia panaudoti šį potencialą daugelyje programų. Gilindamiesi į šių metodikų niuansus, atrandame, kaip jie formuoja AI kraštovaizdį, siūlydami turtingesnę ir saugesnę žmonių ir mašinų sąveiką.
Nepaisant iššūkių, tokių kaip žinių konfliktas, per didelis pasitikėjimas parametrinėmis žiniomis ir haliucinacijų galimybė, šie dirbtinio intelekto modeliai su tinkama greita inžinerija pasirodė esantys transformuojantys įrankiai. Tikslus nurodymų derinimas, kontekstą atitinkantis raginimas ir integravimas su išoriniais duomenų šaltiniais dar labiau sustiprina jų gebėjimą mąstyti, mokytis ir prisitaikyti.















