AI 101
강화 학습이란 무엇인가?
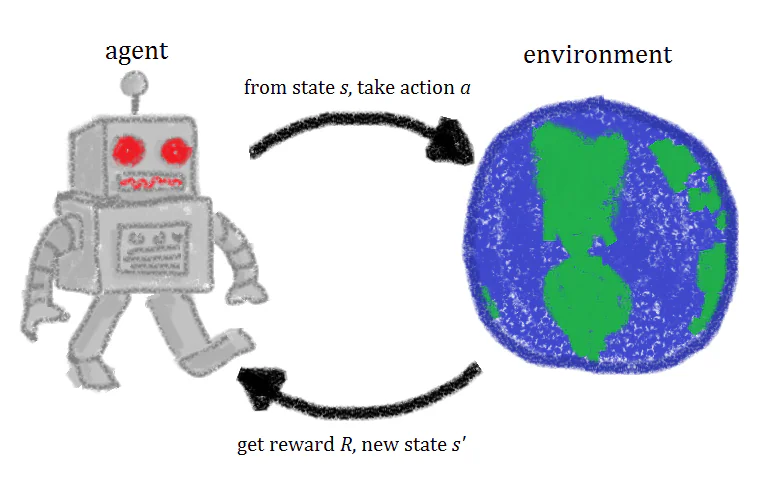
강화 학습이란 무엇인가?
간단히 말하면, 강화 학습은 인공 지능 에이전트를 반복적인 행동과 관련된 보상을 통해 훈련하는 기계 학습 기술입니다. 강화 학습 에이전트는 환경에서 실험을 통해 행동을 취하고 올바른 행동을 취할 때 보상을 받습니다. 시간이 지남에 따라 에이전트는 보상을 최대화하는 행동을 취하는 법을 배웁니다. 이것이 강화 학습의 간단한 정의입니다. 그러나 강화 학습의 개념을 더 자세히 살펴보면 더 나은 이해를 얻을 수 있습니다.
강화 학습이라는 용어는 심리학의 강화 개념에서 유래했습니다. 따라서 심리학적 강화 개념을 이해하기 위해 잠시 시간을 내보겠습니다. 심리학적 의미에서 강화란 특정 반응이나 행동의 발생 가능성을 증가시키는 것을 의미합니다. 강화는 조작적 조건화 이론의 중심 개념으로, 심리학자 B.F. 스키너에 의해 처음 제안되었습니다. 이 контек스트에서 강화는 특정 행동의 빈도를 증가시키는 모든 것을 의미합니다. 인간의 강화 예로는 칭찬, 승진, 사탕, 재미있는 활동 등이 있습니다.
전통적인 심리학적 의미에서 강화는 두 가지 유형이 있습니다. 양적 강화와 음적 강화가 있습니다. 양적 강화는 행동을 증가시키기 위해 무언가를 추가하는 것을 의미합니다. 예를 들어, 잘 행동한 강아지에게 간식을 주는 것입니다. 음적 강화는 행동을 유도하기 위해 자극을 제거하는 것을 의미합니다. 예를 들어, 소심한 고양이를 유도하기 위해 큰 소음을 끕니다.
양적 강화와 음적 강화
양적 강화는 행동의 빈도를 증가시키는 반면 음적 강화는 행동의 빈도를 감소시킵니다. 일반적으로 양적 강화는 강화 학습에서 가장 많이 사용되는 강화 유형입니다. 왜냐하면 모델이 특정 작업에서 성능을 최대화하는 데 도움이 되기 때문입니다. 또한 양적 강화는 모델이 지속 가능한 변화를 만들어내도록 도와줍니다. 이러한 변화를 통해 모델은 일관된 패턴을 만들고 오랜 기간 동안 지속할 수 있습니다.
반면에 음적 강화도 행동을 더 가능하게 만들지만 최소 성능 기준을 유지하는 데 사용됩니다. 음적 강화는 모델이 원치 않는 행동을 피하도록 도와주지만 원하는 행동을 khám phá하도록 만들 수는 없습니다.
강화 에이전트 훈련
강화 학습 에이전트를 훈련할 때, 네 가지 다른 성분 또는 상태가 사용됩니다. 초기 상태(상태 0), 새로운 상태(상태 1), 행동, 보상이 있습니다.
예를 들어, 플랫폼 게임에서 에이전트가 레벨의 끝까지 도달하기 위해 화면을 오른쪽으로 이동하도록 훈련한다고 가정해 보겠습니다. 게임의 초기 상태는 환경에서 가져오며, 게임의 첫 번째 프레임이 분석되어 모델에 제공됩니다. 이 정보에 따라 모델은 행동을 결정해야 합니다.
초기 훈련 단계에서 이러한 행동은 임의적입니다. 그러나 모델이 강화되면 특정 행동이 더 일반적으로 됩니다. 행동이 취해진 후 환경이 업데이트되고 새로운 상태 또는 프레임이 생성됩니다. 에이전트가 취한 행동이 원하는 결과를 생산했다면, 예를 들어 에이전트가 살아 있고 적에게 맞지 않았다면, 에이전트에게 보상이 주어지고 미래에 같은 행동을 더 많이 할 가능성이 됩니다.
이 기본 시스템은 끊임없이 반복되며, 에이전트는 조금씩 더 배워서 보상을 최대화하도록 노력합니다.
에피소드와 연속 작업
강화 학습 작업은 일반적으로 두 가지 범주 중 하나에 속합니다: 에피소드 작업과 연속 작업.
에피소드 작업은 학습/훈련 루프를 수행하고 종료 기준이 충족될 때까지 성능을 개선합니다. 게임에서 이것은 레벨의 끝에 도달하거나 위험에 빠지는 것입니다. 반면에 연속 작업은 종료 기준이 없으므로 훈련이 영원히 계속됩니다.
몬테 카를로와 시간차
에이전트를 훈련시키는 두 가지 주요 방법이 있습니다. 몬테 카를로 접근법에서 보상은 에이전트에게 훈련 에피소드의 끝에만 제공됩니다. 즉, 모델은 종료 조건이 충족될 때까지 성능을 얼마나 잘했는지 알지 못합니다. 이후에 모델은 새로운 정보를 사용하여 업데이트하고 다음 훈련 라운드에서 새로운 정보에 따라 반응합니다.
시간차 방법은 몬테 카를로 방법과 달리 훈련 에피소드 중에 값 추정 또는 점수 추정이 업데이트됩니다. 모델이 다음 시간 단계로 진행되면 값이 업데이트됩니다.
탐색과 이용
강화 학습 에이전트를 훈련하는 것은 두 가지 지표를 균형 있게 하는 것입니다: 탐색과 이용.
탐색은 환경에 대한 더 많은 정보를 수집하는 것을 의미합니다. 이용은 이미 환경에 대한 정보를 사용하여 보상을 얻는 것을 의미합니다. 에이전트가 탐색만 하고 이용하지 않으면 원하는 행동이 결코 수행되지 않습니다. 반대로 에이전트가 이용만 하고 탐색하지 않으면 에이전트는 하나의 행동만 학습하고 다른 가능한 전략을 발견하지 못합니다. 따라서 탐색과 이용의 균형을 맞추는 것이 강화 학습 에이전트를 생성할 때 중요합니다.
강화 학습의 사용 사례
강화 학습은 다양한 역할에서 사용될 수 있으며, 자동화가 필요한 작업에 가장 적합합니다.
산업 로봇의 작업 자동화는 강화 학습이 유용한 분야 중 하나입니다. 강화 학습은 또한 텍스트 마이닝, 긴 텍스트를 요약하는 모델 생성과 같은 문제에 사용될 수 있습니다. 연구자들은 또한 강화 학습을 의료 분야에서 실험하고 있으며, 강화 에이전트가 치료 정책 최적화를 처리하는 작업을 수행하고 있습니다. 강화 학습은 또한 학생들을 위한 교육 자료를 맞춤화하는 데 사용될 수 있습니다.
강화 학습의 요약
강화 학습은 인공 지능 에이전트를 생성하는 강력한 방법으로, 인상적인 결과를 가져올 수 있습니다. 강화 학습을 통해 에이전트를 훈련하는 것은 복잡하고 어려울 수 있습니다. 그러나 성공하면 에이전트는 다양한 환경에서 복잡한 작업을 수행할 수 있습니다.








