AI 101
강화 학습이란 무엇인가?
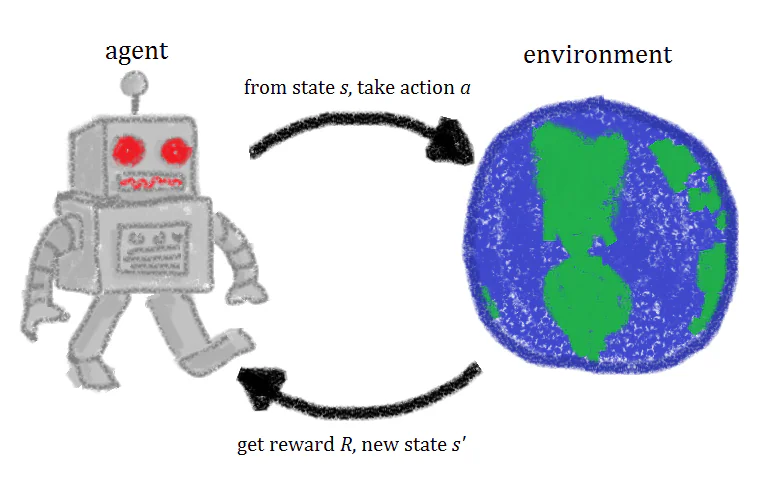
강화 학습이란 무엇인가?
간단히 말해, 강화 학습은 행동과 그에 따른 보상을 반복함으로써 인공 지능 에이전트를 훈련시키는 기계 학습 기법입니다. 강화 학습 에이전트는 환경 내에서 실험을 하며, 행동을 취하고 올바른 행동을 취했을 때 보상을 받습니다. 시간이 지남에 따라 에이전트는 자신의 보상을 극대화할 행동을 취하는 법을 배웁니다. 이것이 강화 학습에 대한 간략한 정의이지만, 강화 학습 뒤에 숨은 개념들을 자세히 살펴보면 더 나은 직관적인 이해를 얻을 수 있습니다. “강화 학습”이라는 용어는 심리학의 강화 개념에서 차용된 것입니다. 그렇기 때문에, 심리학적 강화 개념을 잠시 이해해 보는 것이 좋습니다. 심리학적 의미에서 강화란 특정 반응/행동이 발생할 가능성을 높이는 것을 말합니다. 이 강화 개념은 심리학자 B.F. 스키너가 처음 제안한 조작적 조건화 이론의 핵심 아이디어입니다. 이 맥락에서 강화는 주어진 행동의 빈도를 증가시키는 모든 것입니다. 인간에게 가능한 강화를 생각해 보면, 칭찬, 직장에서의 승진, 사탕, 재미있는 활동 등이 될 수 있습니다. 전통적인 심리학적 의미에서 강화에는 두 가지 유형이 있습니다. 긍정적 강화와 부정적 강화가 있습니다. 긍정적 강화는 행동을 증가시키기 위해 무언가를 추가하는 것으로, 개가 잘 행동할 때 간식을 주는 것과 같습니다. 부정적 강화는 행동을 이끌어내기 위해 자극을 제거하는 것으로, 겁 많은 고양이를 유인하기 위해 시끄러운 소리를 끄는 것과 같습니다.
긍정적 강화 & 부정적 강화
긍정적 강화는 행동의 빈도를 증가시키는 반면, 부정적 강화는 빈도를 감소시킵니다. 일반적으로 긍정적 강화는 강화 학습에서 가장 흔히 사용되는 강화 유형으로, 모델이 주어진 작업에서 성능을 극대화하도록 돕습니다. 그뿐만 아니라 긍정적 강화는 모델이 더 지속 가능한 변화, 즉 일관된 패턴이 되어 오랜 시간 지속될 수 있는 변화를 하도록 이끕니다. 반면, 부정적 강화 또한 행동이 발생할 가능성을 높이지만, 모델의 최대 성능에 도달하기보다는 최소 성능 기준을 유지하는 데 사용됩니다. 강화 학습에서의 부정적 강화는 모델이 바람직하지 않은 행동에서 멀어지도록 보장하는 데 도움을 줄 수 있지만, 모델이 원하는 행동을 탐색하도록 만드는 데는 실제로 도움이 되지 않습니다.
강화 학습 에이전트 훈련하기
강화 학습 에이전트를 훈련할 때, 훈련에는 네 가지 다른 구성 요소 또는 상태가 사용됩니다: 초기 상태(State 0), 새로운 상태(State 1), 행동, 그리고 보상입니다. 화면을 가로질러 오른쪽으로 이동하여 레벨 끝까지 도달하는 것이 AI의 목표인 플랫포머 비디오 게임을 플레이하도록 강화 학습 에이전트를 훈련시킨다고 상상해 보세요. 게임의 초기 상태는 환경에서 가져옵니다. 즉, 게임의 첫 번째 프레임이 분석되어 모델에 제공됩니다. 이 정보를 바탕으로 모델은 행동을 결정해야 합니다. 훈련 초기 단계에서 이러한 행동은 무작위이지만, 모델이 강화됨에 따라 특정 행동이 더 흔해질 것입니다. 행동이 취해진 후 게임 환경이 업데이트되고 새로운 상태 또는 프레임이 생성됩니다. 에이전트가 취한 행동이 바람직한 결과를 낳았다면(이 경우 에이전트가 아직 살아 있고 적에게 맞지 않은 상태라고 가정해 봅시다), 에이전트에게 일정 보상이 주어지고 미래에 같은 행동을 할 가능성이 높아집니다. 이 기본 시스템은 끊임없이 반복되며, 매번 에이전트는 조금 더 배우고 자신의 보상을 극대화하려고 시도합니다.
에피소드 작업 vs 연속 작업
강화 학습 작업은 일반적으로 두 가지 다른 범주 중 하나에 속할 수 있습니다: 에피소드 작업과 연속 작업. 에피소드 작업은 학습/훈련 루프를 수행하고 일부 종료 기준이 충족되어 훈련이 종료될 때까지 성능을 향상시킵니다. 게임에서 이것은 레벨 끝에 도달하거나 가시 함정에 빠지는 것일 수 있습니다. 반대로, 연속 작업에는 종료 기준이 없으며, 엔지니어가 훈련을 종료하기로 선택할 때까지 본질적으로 영원히 훈련을 계속합니다.
몬테카를로 vs 시간차 학습
강화 학습 에이전트를 학습하거나 훈련시키는 데는 두 가지 주요 방법이 있습니다. 몬테카를로 접근법에서는 보상이 훈련 에피소드가 끝날 때만 에이전트에게 전달됩니다(점수가 업데이트됨). 달리 말하면, 종료 조건에 도달했을 때만 모델은 자신이 얼마나 잘 수행했는지 배웁니다. 그런 다음 이 정보를 사용하여 업데이트할 수 있으며, 다음 훈련 라운드가 시작되면 새로운 정보에 따라 반응할 것입니다. 시간차 방법은 몬테카를로 방법과 달리 가치 추정 또는 점수 추정이 훈련 에피소드 과정 중에 업데이트된다는 점이 다릅니다. 모델이 다음 시간 단계로 진행하면 값이 업데이트됩니다.
탐험 vs 활용
강화 학습 에이전트를 훈련시키는 것은 두 가지 다른 지표, 즉 탐험과 활용의 균형을 맞추는 절충의 행위입니다. 탐험은 주변 환경에 대한 더 많은 정보를 수집하는 행위인 반면, 활용은 환경에 대해 이미 알려진 정보를 사용하여 보상 점수를 얻는 것입니다. 에이전트가 오직 탐험만 하고 환경을 전혀 활용하지 않으면, 원하는 행동은 결코 수행되지 않을 것입니다. 반대로, 에이전트가 오직 활용만 하고 탐험을 전혀 하지 않으면, 에이전트는 단 하나의 행동만 수행하는 법을 배우고 보상을 얻는 다른 가능한 전략을 발견하지 못할 것입니다. 따라서 강화 학습 에이전트를 만들 때 탐험과 활용의 균형을 맞추는 것이 중요합니다.
강화 학습의 사용 사례
강화 학습은 매우 다양한 분야에서 사용될 수 있으며, 작업 자동화가 필요한 애플리케이션에 가장 적합합니다. 산업용 로봇이 수행할 작업의 자동화는 강화 학습이 유용하게 쓰이는 한 분야입니다. 강화 학습은 텍스트 마이닝과 같은 문제에도 사용될 수 있으며, 긴 본문을 요약할 수 있는 모델을 생성하는 데 쓰입니다. 연구자들은 또한 의료 분야에서 강화 학습을 사용하는 실험을 하고 있으며, 치료 정책 최적화와 같은 작업을 강화 학습 에이전트가 처리하도록 합니다. 강화 학습은 학생들을 위한 교육 자료를 맞춤화하는 데에도 사용될 수 있습니다.
강화 학습 요약
강화 학습은 인상적이고 때로는 놀라운 결과를 낳을 수 있는 AI 에이전트를 구축하는 강력한 방법입니다. 강화 학습을 통해 에이전트를 훈련시키는 것은 많은 훈련 반복과 탐험/활용 이분법의 미묘한 균형이 필요하기 때문에 복잡하고 어려울 수 있습니다. 그러나 성공한다면, 강화 학습으로 생성된 에이전트는 매우 다양한 환경에서 복잡한 작업을 수행할 수 있습니다.








