AI 101
베이즈 정리란 무엇인가?
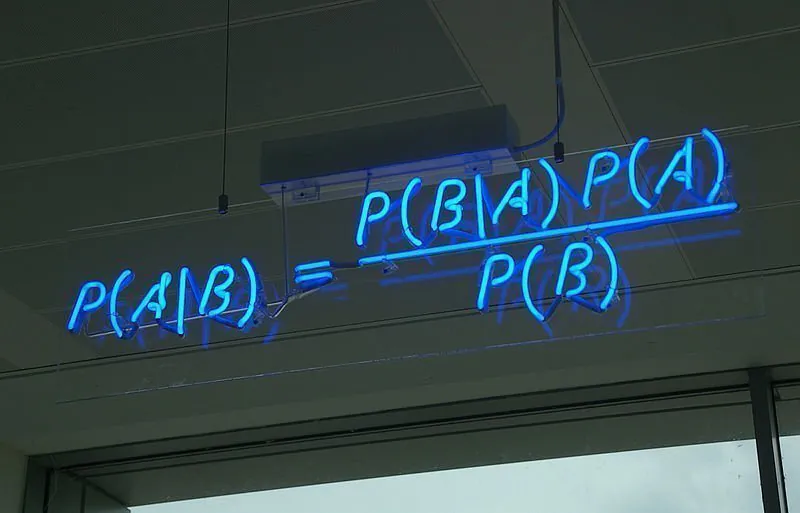
데이터 과학이나 기계 학습에 대해 공부해 본 적이 있다면, ‘베이즈 정리’라는 용어를 들어보거나 ‘베이즈 분류기’라는 용어를 들어보았을 가능성이 있습니다. 이러한 개념들은 전통적인 빈도주의 통계학 관점에서 확률에 대해 생각하는 데 익숙하지 않다면 다소 혼란스러울 수 있습니다. 이 기사는 베이즈 정리의 원리를 설명하고 기계 학습에서 어떻게 사용되는지 설명하려고 합니다.
베이즈 정리란 무엇인가?
베이즈 정리는 조건부 확률을 계산하는 방법입니다. 조건부 확률(한 이벤트가 발생할 때 다른 이벤트가 발생할 확률)을 계산하는 전통적인 방법은 조건부 확률 공식을 사용하여 두 이벤트가 동시에 발생하는 공동 확률을 계산하고 이벤트 2가 발생할 확률로 나누는 것입니다. 그러나 조건부 확률은 베이즈 정리를 사용하여 약간 다른 방식으로 계산할 수도 있습니다.
베이즈 정리를 사용하여 조건부 확률을 계산할 때 다음 단계를 따르세요:
- 조건 A가 참인 경우 조건 B가 참인 확률을 결정합니다.
- 이벤트 A가 발생할 확률을 결정합니다.
- 두 확률을 곱합니다.
- 이벤트 B가 발생할 확률로 나눕니다.
이것은 베이즈 정리의 공식이 다음과 같이 표현될 수 있음을 의미합니다.
P(A|B) = P(B|A)*P(A) / P(B)
이와 같이 조건부 확률을 계산하는 것은 반대 조건부 확률을 쉽게 계산할 수 있을 때 또는 공동 확률을 계산하는 것이 너무 어려울 때 특히 유용합니다.
베이즈 정리의 예
이것을 더 쉽게 이해하기 위해 베이즈 정리와 베이즈 추론을 적용하는 예를 살펴보겠습니다. 여러 참가자가 당신에게 이야기를 해주고 당신이 참가자 중 누구가 당신에게 거짓말을 하는지 결정해야 하는 간단한 게임을 하기로 했습니다. 가상 시나리오의 변수를 베이즈 정리 방정식에 채워보겠습니다.
우리는 각 개인이 거짓말을 하는지 진실을 하는지 예측하려고 합니다. 따라서 당신을 제외한 3명의 플레이어가 있다면 범주형 변수는 A1, A2, A3으로 표현할 수 있습니다. 그들이 거짓말을 하는지 진실을 하는지에 대한 증거는 그들의 행동입니다. 포커를 chơi할 때처럼 누군가 거짓말을 할 때 나타나는 특정 ‘신호’를 찾고 그 정보를 사용하여 예측합니다. 또는 질문을 허용한다면 그들의 이야기가 일치하지 않는 모든 증거가 됩니다. 우리는 누군가 거짓말을 할 증거를 B로 나타낼 수 있습니다.
명확히 하기 위해, 우리는 각 개인이 거짓말을 하는지 진실을 하는지에 대한 확률을 예측하려고 합니다. 즉, 그들의 행동에 대한 증거가 주어졌을 때 확률(A는 거짓말/진실). 이를 위해서는 행동이 발생할 확률을 결정해야 합니다. 즉, 누군가 실제로 거짓말을 할 때 또는 진실을 할 때 행동이 발생할 확률, 즉 P(B|A)를 결정합니다. 당신은 그 행동이 가장 합리적인 조건에서 발생할 확률을 결정하려고 합니다. 만약에 3가지 행동을 관찰한다면 각 행동에 대해 계산을 해야 합니다. 예를 들어, P(B1, B2, B3|A). 당신은 게임에 참여한 모든 사람에게 이 계산을 해야 합니다. 즉, A/각 사람에 대해 이 계산을 해야 합니다. 방정식의 이 부분입니다:
P(B1, B2, B3,|A) * P|A
마지막으로 이것을 B의 확률로 나눕니다.
이 방정식의 실제 확률에 대한 어떤 정보도 받으면 우리의 확률 모델을 업데이트하여 새로운 증거를 고려합니다. 이것을 ‘사전 확률 업데이트’라고 하며 관찰된 이벤트의 사전 확률에 대한 우리의 가정에서 업데이트합니다.
베이즈 정리의 기계 학습 응용
베이즈 정리가 기계 학습에서 가장 일반적으로 사용되는 것은 나이브 베이즈 알고리즘의 형태입니다.
나이브 베이즈는 이진 분류와 다중 클래스 분류 모두에 사용됩니다. 나이브 베이즈의 이름은 증거/속성의 값, 즉 P(B1, B2, B3|A)의 B가 서로 독립적이라고 가정했기 때문입니다. 즉, 이러한 속성이 서로 영향을 미치지 않는다고 가정하여 모델을 단순화하고 계산을 가능하게 합니다. 이러한 단순화된 모델에도 불구하고 나이브 베이즈는 분류 알고리즘으로서 상당히 잘 작동하는 경향이 있습니다. 이는 이러한 속성이 실제로 서로 영향을 미치지 않는다고 가정하는 것이 대부분의 경우 사실이 아니기 때문입니다.
나이브 베이즈 분류기의 일반적으로 사용되는 변형에는 다항식 나이브 베이즈, 베르누이 나이브 베이즈, 가우시안 나이브 베이즈가 있습니다.
다항식 나이브 베이즈 알고리즘은 문서를 분류하는 데 자주 사용되며 문서 내에서 단어의 빈도를 해석하는 데 효과적입니다.
베르누이 나이브 베이즈는 다항식 나이브 베이즈와 유사하게 작동하지만 알고리즘이 생성하는 예측은 불리언 값입니다. 즉, 클래스를 예측할 때 값은 이진 값(예 또는 아니요)입니다. 텍스트 분류의 경우 베르누이 나이브 베이즈 알고리즘은 문서에 단어가 포함되어 있는지 여부에 따라 매개변수를 할당합니다.
예측 변수/특징의 값이 이산적이지 않고 연속적인 경우 가우시안 나이브 베이즈를 사용할 수 있습니다. 연속적인 특징의 값은 가우시안 분포에서 샘플링된 것으로 가정됩니다.












