인공지능
사용자 스케치로 커스텀 생성적 적대 신경망 만들기

카네기 멜런 대학과 MIT의 연구자들은 사용자가 스케치한 도드들이 나타내는 특징적인 도화지로 커스텀 생성적 적대 신경망(GAN) 이미지 생성 시스템을 만들 수 있는 새로운 방법론을 개발했습니다.
이러한 유형의 시스템은 사용자가 특정 동물, 건물 유형, 심지어 개인과 같은 매우 구체적인 이미지를 생성할 수 있는 이미지 생성 시스템을 만들 수 있습니다. 현재 대부분의 GAN 생성 시스템은 광범위하고 상당히 임의의 출력을 생성하며, 특정 특성(예: 동물 품종, 사람의 헤어 타입, 건축 양식 또는 실제 얼굴 특징)을 지정하는 기능이 제한적입니다.
이 접근 방식은 논문 스케치로 자신의 GAN 만들기에 설명되어 있으며, 새로운 스케치 인터페이스를 사용하여 수천 개의 객체 유형(사용자의 의도와 관련이 없는 많은 하위 유형 포함)을 포함하는 이미지 데이터베이스에서 기능과 클래스를 찾는 효과적인 ‘검색’ 함수로 사용됩니다. 그런 다음 GAN은 이 필터링된 이미지 하위 집합에 대해 훈련됩니다.
사용자가 GAN을 조율하려는 특정 객체 유형를 스케치하면 프레임워크의 생성 기능은 해당 클래스에 chuyên門화됩니다. 예를 들어, 사용자가 특정 유형의 고양이(단순히 존재하는 고양이와는 달리 이 고양이는 존재하지 않습니다를 얻을 수 있는 것과는 달리)를 생성하는 프레임워크를 만들고 싶다면, 사용자의 입력 스케치는 비관련 클래스의 고양이를 제외하는 필터로 작동합니다.

출처: https://peterwang512.github.io/GANSketching/
이 연구는 카네기 멜런 대학의 Sheng Yu-Wang와 MIT의 컴퓨터 과학 및 인공 지능 연구소의 Colleague Jun-Yan Zhu, David Bau가 주도합니다.
이 방법은 ‘GAN 스케치’라고 불리며, 입력 스케치를 사용하여 ‘템플릿’ GAN 모델의 가중치를 직접 변경하여 교차 도메인 적대적 손실을 통해 식별된 도메인 또는 하위 도메인을 대상으로 합니다.
다양한 정규화 방법을 사용하여 모델의 출력이 다양하면서 높은 이미지 품질을 유지하도록 보장했습니다. 연구자들은 잠재 공간을 보간하고 이미지 편집 절차를 수행할 수 있는 샘플 애플리케이션을 만들었습니다.
이 [$클래스]는 존재하지 않습니다
GAN 기반 이미지 생성 시스템은 최근 몇 년 동안 유행이 되었습니다. 사람, 임대 아파트, 스낵, 발, 말, 정치인 및 곤충을 포함한 다양한 비존재하는 것들의 사진을 생성할 수 있는 프로젝트가 많습니다.
GAN 기반 이미지 합성 시스템은 대상 도메인(예: 얼굴 또는 말)의 이미지로 구성된 광범위한 데이터셋을 컴파일하거나 큐레이션하고, 이미지 데이터베이스에 있는 기능의 범위를 일반화하는 모델을 훈련하고, 학습된 기능을 기반으로 임의의 예를 출력할 수 있는 생성기 모듈을 구현하여 생성됩니다.

DeepFacePencil의 스케치에서 생성된 출력. 여러 유사한 스케치-이미지 프로젝트가 존재합니다. 출처: https://arxiv.org/pdf/2008.13343.pdf
고차원 특징은 훈련 과정에서 먼저 구체화되며, 화가의 캔버스에 색칠한 첫 번째 광범위한 색칠과 동일합니다. 이러한 고차원 특징은 결국 더 자세한 특징(예: 고양이의 눈부신 눈과 날카로운 수염, 일반적인 베이지색 덩어리와는 달리 머리)와 상관관계가 있습니다.
나는 당신이 무슨 말을 하는지 압니다…
이러한 초기의 기본적인 모양과 나중에 얻은 자세한 해석 사이의 관계를 매핑하면, 사용자는 粗다른 도화지에서 복잡하고 사진과 같은 이미지를 생성할 수 있습니다.
최근 NVIDIA는 GAN 기반 풍경 생성에 대한 장기적인 GauGAN 연구의 데스크톱 버전을 출시했습니다. 이는 이 원리를 쉽게 보여줍니다:
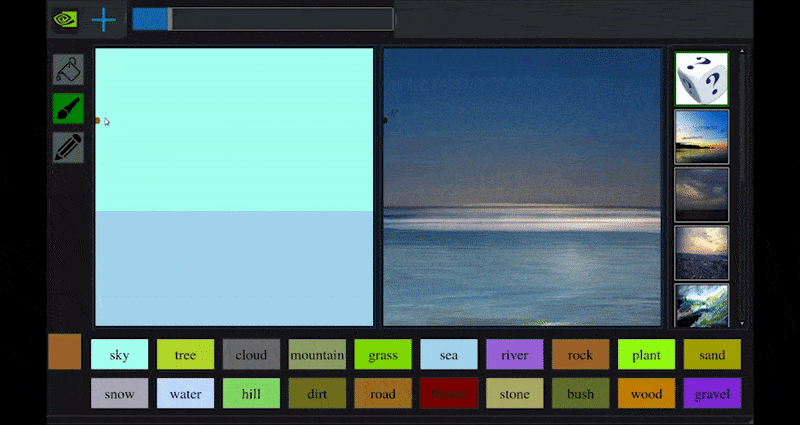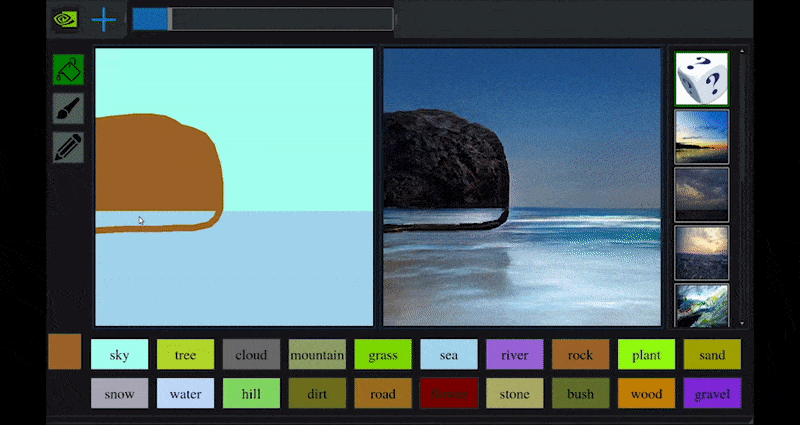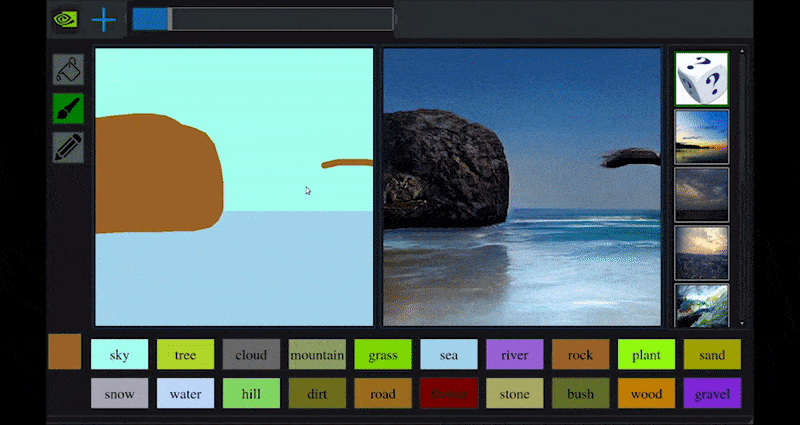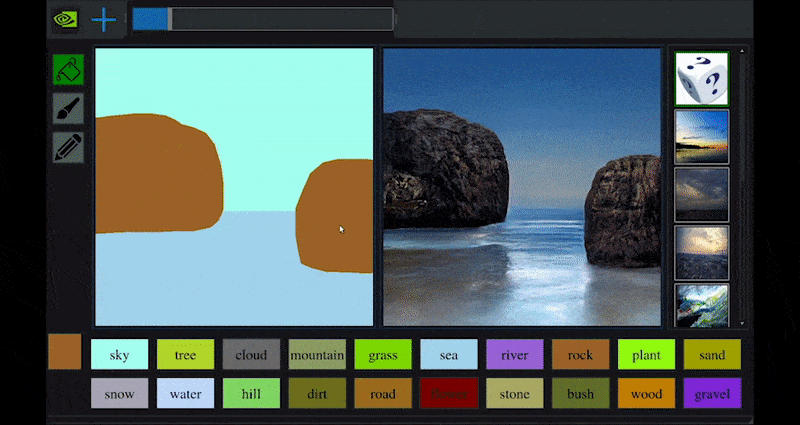
NVIDIA의 GauGAN과 이제 NVIDIA Canvas 애플리케이션을 통해 근사한 도화지에서 풍부한 풍경 이미지를 생성합니다. 출처: https://rossdawson.com/futurist/implications-of-ai/future-of-ai-image-synthesis/
마찬가지로 여러 시스템, 예를 들어 DeepFacePencil,는 동일한 원리를 사용하여 다양한 도메인에 대한 스케치 유도 사진과 같은 이미지 생성기를 만들었습니다.

DeepFacePencil의 아키텍처.
스케치-이미지 단순화
新的 논문의 GAN 스케치 접근 방식은 사용자의 입력을 사용하여 훈련 데이터로 구성해야 하는 이미지 하위 집합을 정의하여 GAN 이미지 프레임워크 개발에서 일반적으로 포함되는 데이터 수집 및 큐레이션의 막중한 부담을 제거합니다.
시스템은 사용자 입력 스케치의 작은 수로만 프레임워크를 조율할 수 있도록 설계되었습니다. 시스템은 실제로 2019年に 카네기 멜런 대학, Adobe, Uber ATG 및 Argo AI의 연구자들이 공동으로 진행한 PhotoSketch 프로젝트의 기능을 역전시킵니다. PhotoSketch는 이미지에서 예술적인 스케치를 생성하도록 설계되었으며, 이미 새로운 작업에 포함되어 있습니다. PhotoSketch는 이미 초기의 모호한 hình태와 나중에 얻은 자세한 해석 사이의 관계를 매핑하는 효과적인 매핑을 포함합니다.
생성 부분에서는 새로운 방법은 StyleGAN2의 가중치만 수정합니다. 사용되는 이미지 데이터는 전체 데이터의 하위 집합이므로 매핑 네트워크만 수정하면 원하는 결과를 얻을 수 있습니다.
이 방법은 여러 인기 있는 하위 도메인(예: 말, 교회, 고양이)에서 평가되었습니다.

프린스턴 대학의 2016년 LSUN 데이터셋이 대상 하위 도메인을 파생하기 위한 핵심 자료로 사용되었습니다. 실제 사용자 입력 스케치의 특이성에 강한 스케치 매핑 시스템을 구축하기 위해 시스템은 Microsoft가 2021-2016년 사이에 개발한 QuickDraw 데이터셋의 이미지에서 훈련됩니다.
PhotoSketch와 QuickDraw 사이의 스케치 매핑은 khá 다르지만, 연구자들은 자신의 프레임워크가 상대적으로 간단한 포즈에서 쉽게 두 가지를 모두 다룰 수 있다는 것을 발견했습니다. 그러나 더 복잡한 포즈(예: 누운 고양이)는 더 큰 도전이 되며, 매우 추상적인 사용자 입력(예: 너무 粗다른 도화지)은 결과의 품질을 저하합니다.

잠재 공간 및 자연스러운 이미지 편집
연구자들은 핵심 작업을 기반으로 두 가지 애플리케이션을 개발했습니다. 잠재 공간 편집과 이미지 편집입니다. 잠재 공간 편집은 훈련 시간에 사용자 제어가 가능하며, 대상 도메인에 忠實하며 일관된 변화를 제공합니다.

커스텀 GAN 스케치 모델의 매끄러운 잠재 공간 보간.
잠재 공간 편집 구성 요소는 Aalto 대학, Adobe 및 NVIDIA의 2020년 GANSpace 프로젝트에 의해 구동됩니다.
단일 이미지도 사용자 지정 모델에 공급될 수 있으며, 자연스러운 이미지 편집을 가능하게 합니다. 이 애플리케이션에서는 단일 이미지를 사영하여 사용자 지정 GAN으로, 직접 편집을 가능하게 하며, 높은 수준의 잠재 공간 편집도 보존합니다.

실제 이미지를 GAN(고양이 모델)의 입력으로 사용하여 제출된 스케치와 일치하도록 편집합니다. 이를 통해 스케치로 이미지 편집을 가능하게 합니다.
시스템은 구성 가능하지만, 훈련 및 보정을 위해 실시간으로 작동하도록 설계되지 않았습니다. 현재 GAN 스케치에는 30,000개의 훈련 반복이 필요합니다. 시스템은 또한 원래 모델의 원래 훈련 데이터에 접근할 수 있어야 합니다.
데이터셋이 오픈 소스이고, 로컬 복사를 허용하는 라이선스가 있는 경우, 이는 로컬로 설치된 패키지에 원본 데이터를 포함하여 수행할 수 있지만, 이는 상당한 디스크 공간을 차지할 것입니다. 또는 원격으로 데이터에 접근하거나 처리할 수 있으며, 이는 네트워크 오버헤드와(클라우드에서 실제 처리가 발생하는 경우) 컴퓨팅 비용 고려를 도입합니다.

인간이 생성한 4개의 스케치만으로 훈련된 사용자 지정 FFHQ 모델의 변환.












